

Lleva la optimización de la experiencia al siguiente nivel con IA y consigue más
experimentos personalizaciones conversionesUna sola plataforma para todo tu progreso
Probar nuevas funciones, acelerar resultados, mejorar cada experiencia. Todo empieza con una mentalidad de optimización. Todo empieza con probar y luego hacerlo mejor.
Experimentación WEB
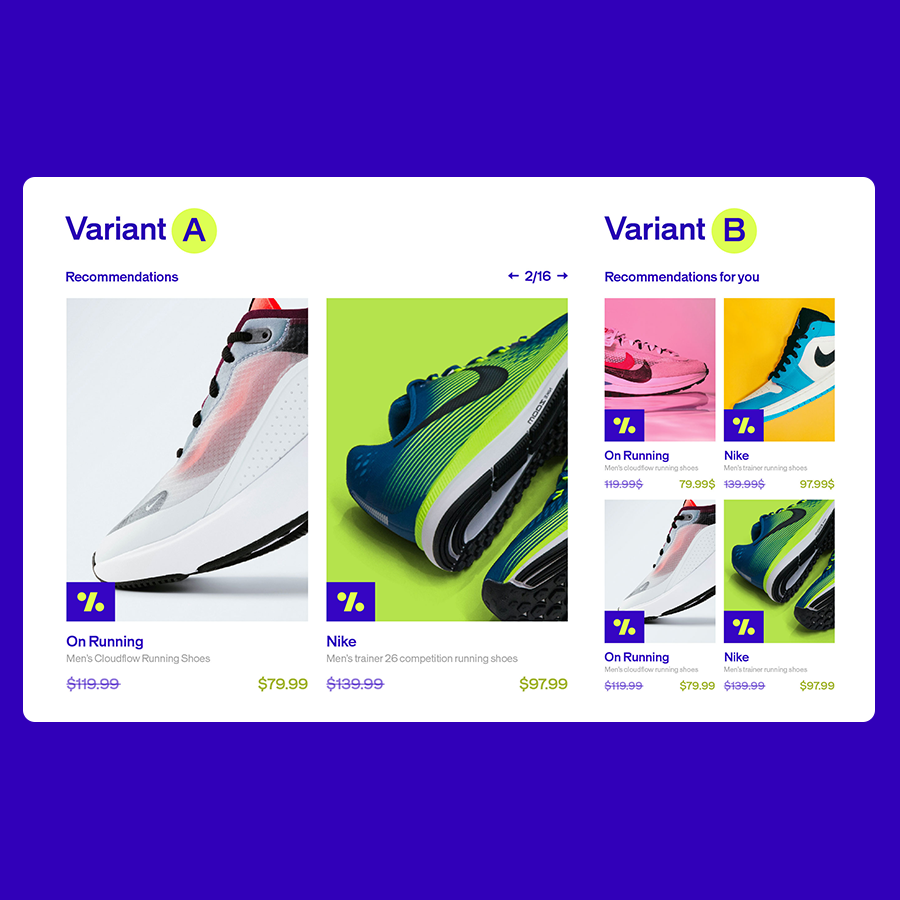
Combina test avanzados con una construcción de experiencias simple y alcanza tus objetivos de conversión con rapidez y confianza.
- Empieza con algo sencillo o ve más allá con múltiples formas de experimentar a lo largo de todo el recorrido.
- Toma decisiones con la tranquilidad de que tus conversiones están en buenas manos.

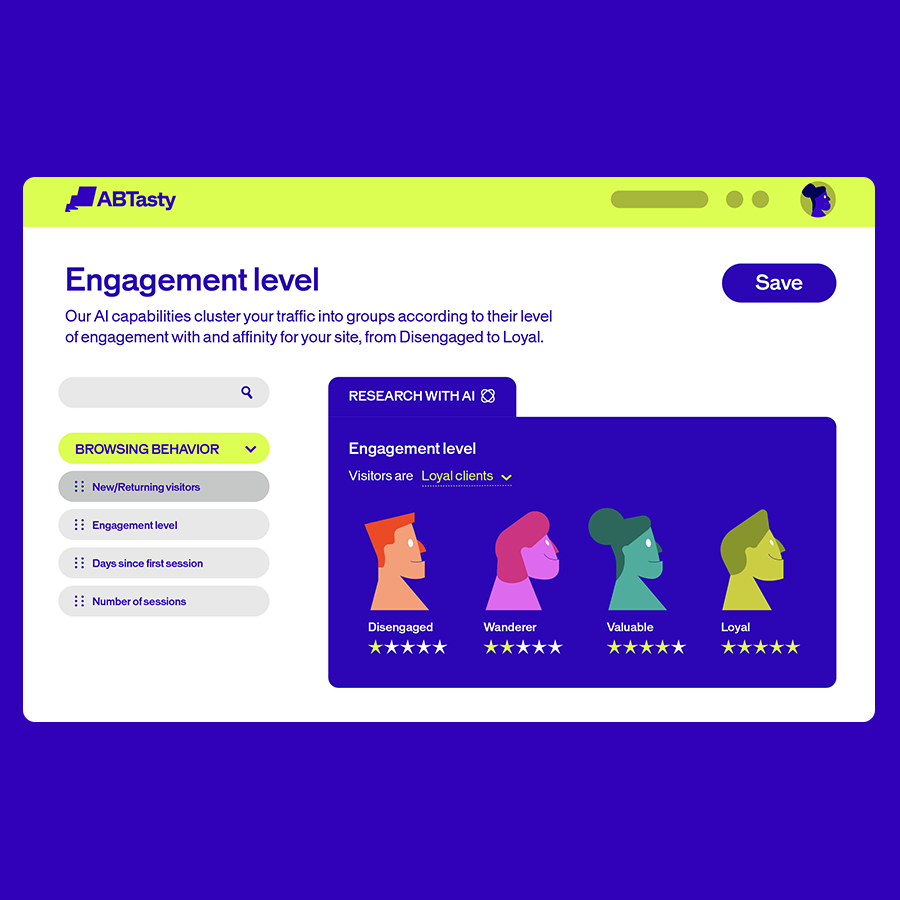
IA que funciona para ti
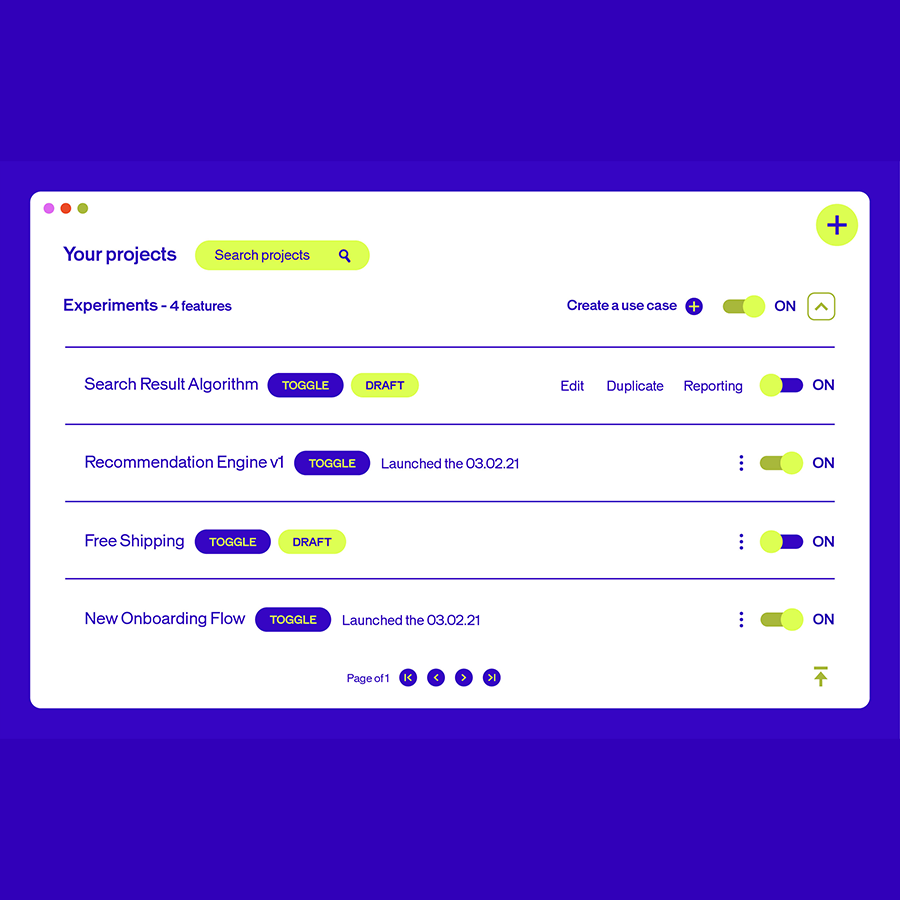
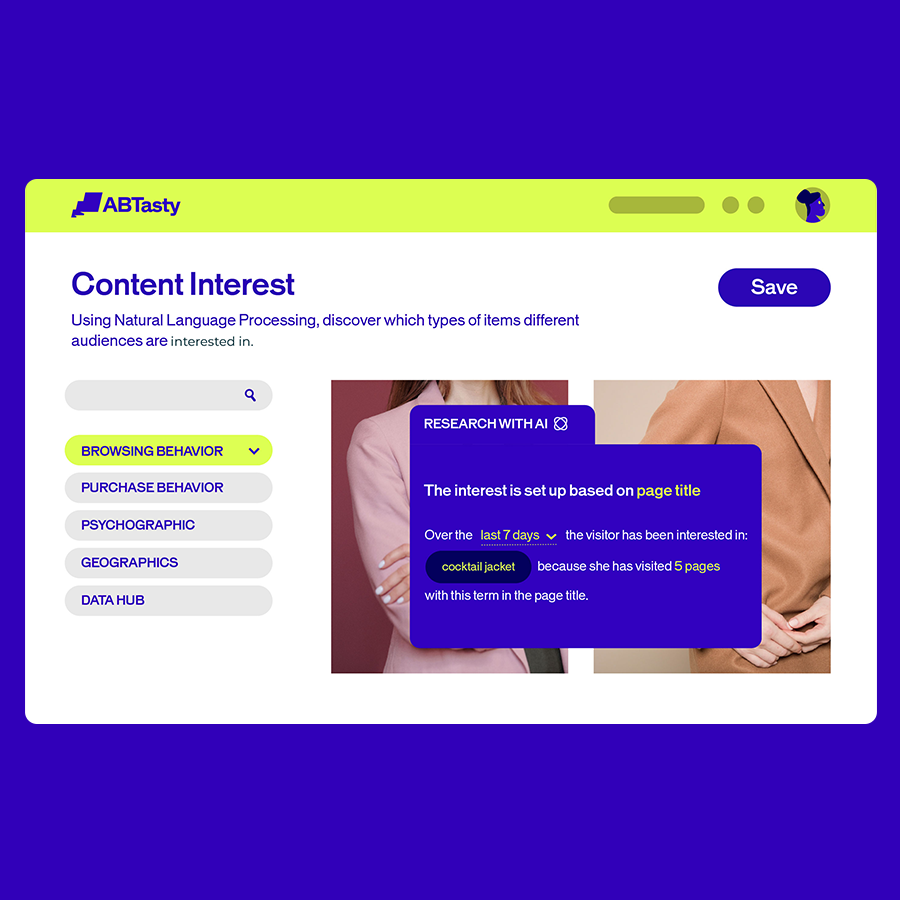
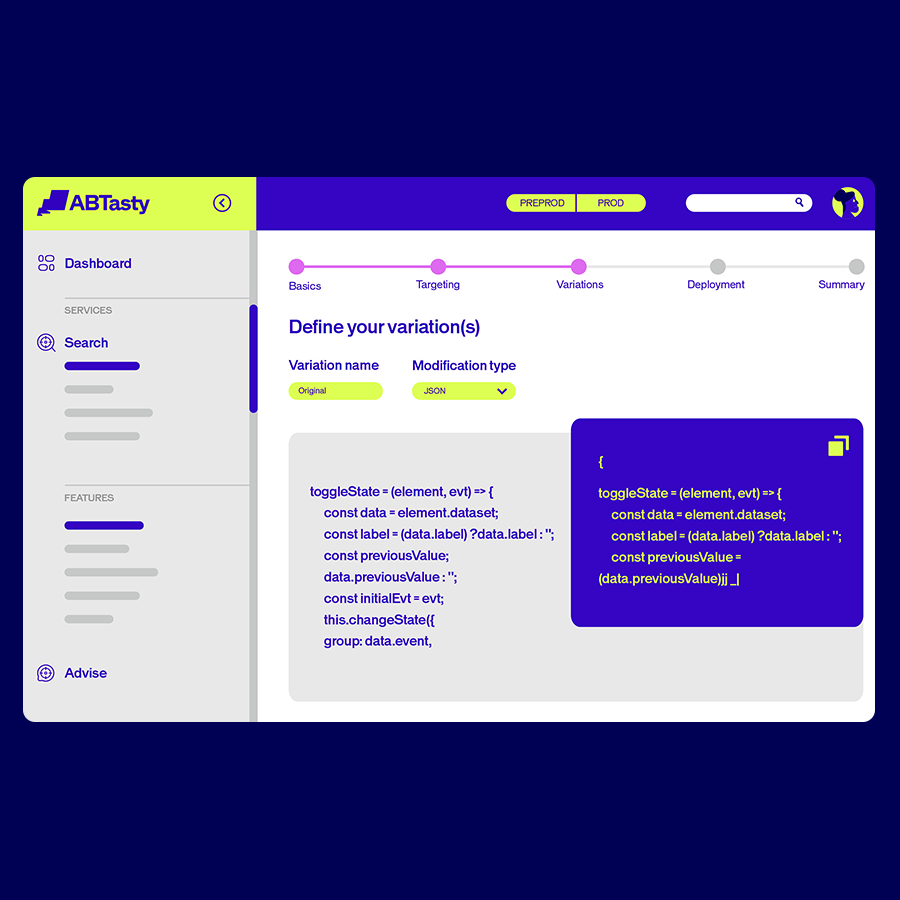
Con la IA integrada en todas las funciones, nunca ha sido tan fácil crear experiencias digitales más inteligentes y significativas para cada visitante. Nuestra suite de IA gestiona el trabajo entre bastidores, para que tú dispongas de más tiempo para innovar, elaborar estrategias y ofrecer experiencias sobresalientes.
Superemos juntos los límites de la optimización de la experiencia.
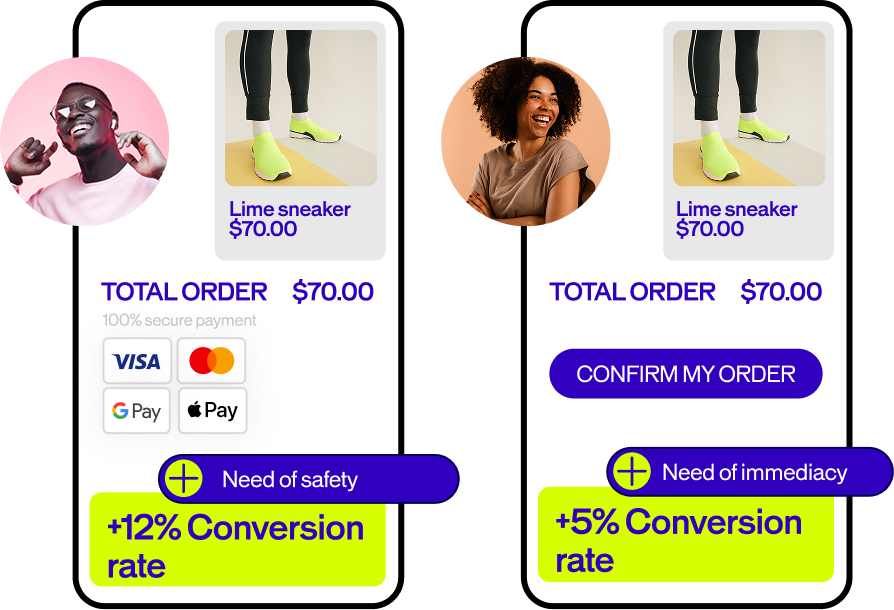
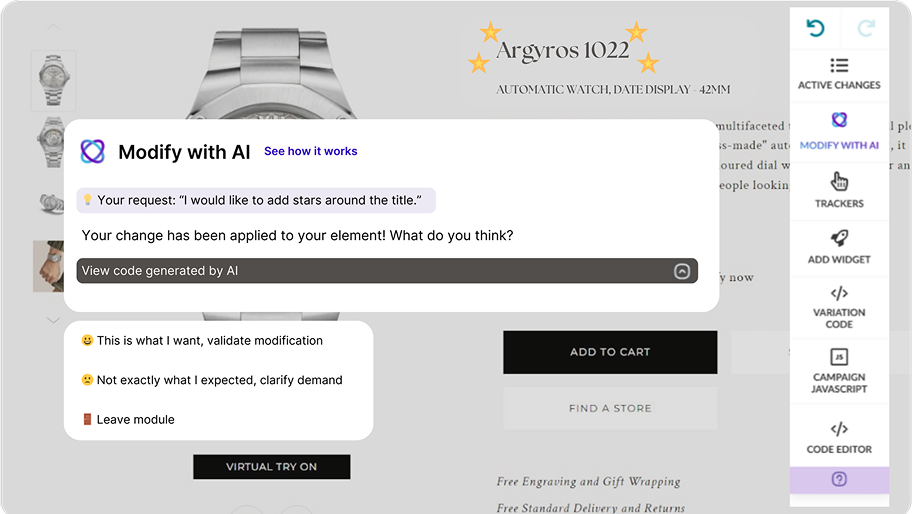
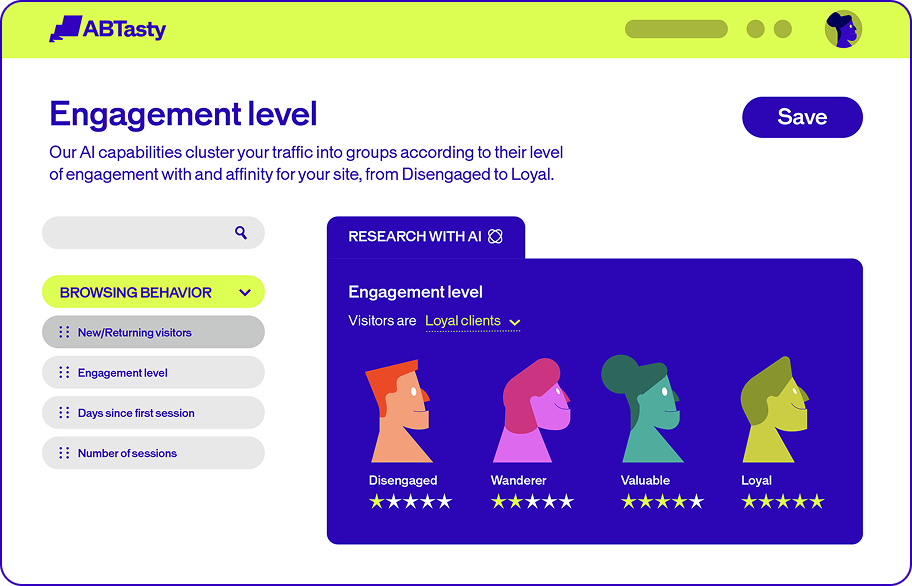

Optimizar es nuestro objetivo. La colaboración es la forma de conseguirlo.
Nos tomamos tu progreso en serio, como si fuera propio. Desde el primer contacto hasta cada hito que alcanzamos juntos, estamos a tu lado.
Piensa en nosotros como una extensión de tu equipo: con mirada estratégica, enfoque en la experiencia del cliente y un plan concreto para lograr una optimización que realmente mueva la aguja.
Cuando se trata de optimizar, primero hay que probar. Luego viene lo mejor.

ROI
Maximiza el retorno de la inversión con una toma de decisiones basada en datos, para que tomes las decisiones correctas para tu negocio desde el principio.

Compromiso
Impulsar el compromiso a lo largo de todo el recorrido del cliente con experiencias interactivas adaptadas a cada individuo.

Lealtad
Consigue que los clientes vuelvan una y otra vez con momentos personalizados en todos los puntos de contacto.

Riesgo
Atrévete sin miedo: prueba ideas, lanza de forma progresiva y activa funciones con total control.
¿Quiere ver AB Tasty en acción?
Crea experiencias integrales que impulsen el crecimiento en todos los canales digitales.

El equipo de AB Tasty propone muchas ideas diferentes. Al combinarlas con nuestros conceptos, obtenemos la perspectiva que necesitamos. Desde el punto de vista del software, siempre hay algo nuevo en camino en la lista de funcionalidades.


Lo fundamental para nosotros es aprovechar nuestros datos para ofrecer un servicio y experiencias personalizadas en línea. Y con AB Tasty lo tenemos. Los clientes, después de todo, están en el centro de todo lo que hace Clarins.


Trabajar con AB Tasty nos ha permitido aprovechar hipótesis no solo de su propio equipo, sino también de otros con los que colaboran. Gracias a ello, uestras estrategias se han acelerado. Veo a AB Tasty más como un partner que trabaja con nosotros como parte de nuestro equipo, y no solo como un proveedor.

El año 2023 marcó un hito fenomenal en nuestra transformación digital. AB Tasty ha desempeñado un papel fundamental en esto, ayudando a nuestro equipo a innovar y validar a un ritmo más rápido y con menos riesgo.

La decisión de cambiarnos a AB Tasty se debió al retorno de inversión general. AB Tasty nos ofreció una solución rica en funcionalidades a un precio competitivo. La implementación fue sencilla, ejecutar experimentos se puede hacer de manera eficiente y el equipo de soporte nos ha estado ayudando a llevar a cabo pruebas exitosas.

AB Tasty ofrece resultados extraordinarios. Los escenarios son altamente relevantes y adaptados a nuestras necesidades específicas. La cultura de «probar y aprender» en AB Tasty nos permite optimizar continuamente.
13 años transformando frustraciones en bases sólidas para el crecimiento.
Your paragraph text here

Cultura de prueba y aprendizaje
Llevamos nuestra cultura de testeo y aprendizaje a tu negocio.
Cada decisión deja de ser un riesgo y se convierte en una elección.
Nuestro equipo de expertos
Nuestro equipo ha trabajado con miles de clientes, en distintas etapas de su recorrido y en todo el mundo. Somos expertos en optimización de experiencias y te acompañamos en cada paso de tu roadmap hacia un impacto real.
Red de partners e integraciones
Hemos construido una red sólida de partners e integraciones para trabajar cómo y dónde lo necesites.
Plataforma robusta
Nuestra plataforma, con motores estadísticos pensados para el negocio, rendimiento optimizado y máxima seguridad, está lista para crecer contigo.






Crece más rápido con
AB Tasty
Obtén un recorrido personalizado de la plataforma

