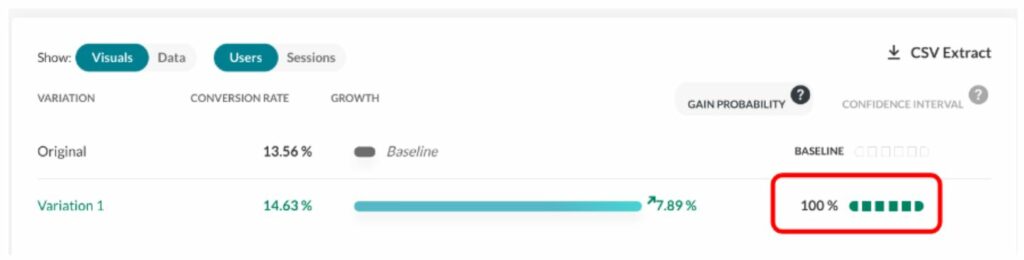
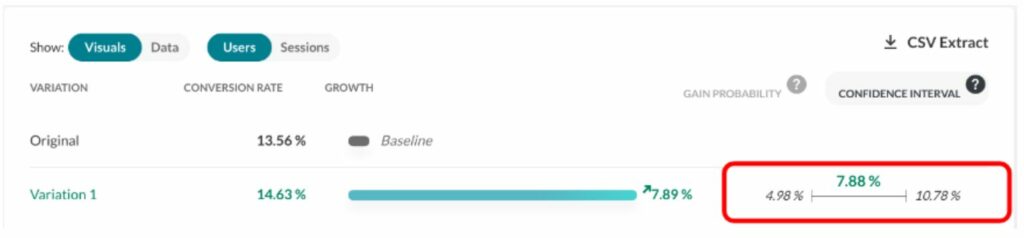
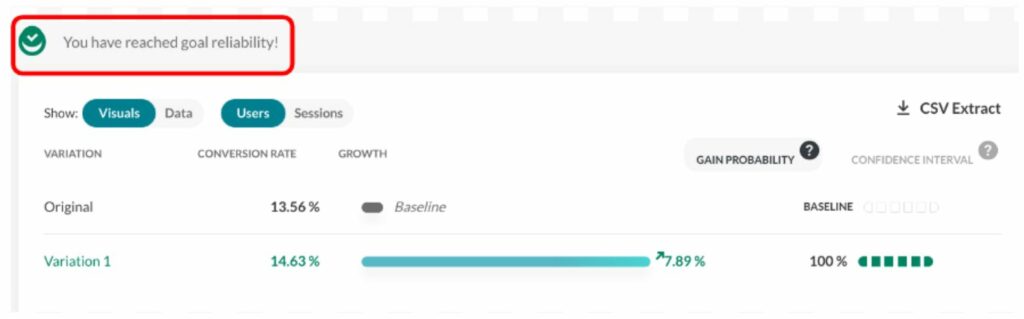
Stichprobengrößen für A/B-Tests leicht berechnen
A/B-Tests helfen dabei, fundierte Entscheidungen auf Basis von Daten statt Bauchgefühl zu treffen. Wie viele Besucher Sie für eine Stichprobe benötigen, um diesen Ergebnissen vertrauen zu können, hängt wiederum von verschiedenen Faktoren ab. Zum Glück stehen Ihnen heutzutage zahlreiche Online-Tools zur Verfügung, die diese Berechnung übernehmen und den Prozess vereinfachen. Ein Mathematikstudium brauchen Sie nicht mehr.

So berechnen Sie die Stichprobengröße
Die optimale Stichprobengröße für einen Test ist entscheidend, da sie Ihre gesamte Zielgruppe möglichst realistisch abbilden soll. Nur so werden die Ergebnisse belastbar und Sie vermeiden Fehlinterpretationen, wie etwa falsch-positive oder negative Resultate. Ist die Stichprobe zu klein, können die Ergebnisse stark verzerrt sein. Ist sie hingegen zu groß, investieren Sie unnötig Zeit und Ressourcen ohne zusätzlichen Erkenntnisgewinn.
Als grobe Faustregel gilt, dass pro Testvariante mindestens 10.000 Website-Besucher einbezogen sowie mindestens 300 Conversions erzielt werden sollten. Die exakte Stichprobengröße lässt sich für jede A/B-Testvariante mithilfe einer standardisierten mathematischen Formel berechnen, die wie folgt aussieht:
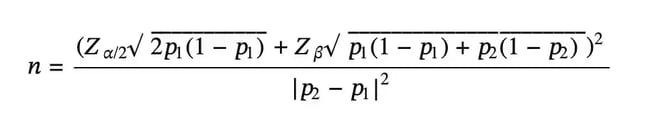
Die nachfolgende Übersicht erläutert, wofür die einzelnen Variablen in der Gleichung stehen:
- n ist die benötigte Stichprobengröße pro Testvariante
- p1 ist die erwartete Konversionsrate vor einer Veränderung
- p2 ist die Konversionsrate, die um die absolute minimale Effektgröße erhöht wurde
- Z⍺/2 ist der Z-Wert des Konfidenzniveaus
- Zβ ist der Z-Wert der Teststärke
Klingt kompliziert? Bevor Sie jetzt zum Mathebuch greifen, lassen Sie uns einen Blick darauf werfen, was die einzelnen Variablen im Detail bedeuten:
- Erwartete Konversionsrate: beschreibt die aktuelle Konversionsrate für das Ziel, das Sie verbessern möchten. Das kann zum Beispiel die Anmelderate, die Kaufabschlussrate oder die Click-Through-Rate (CTR) sein.
- Minimale Effektgröße (MDE): steht für die kleinste Veränderung der erwarteten Konversionsrate, die Sie mit statistischer Sicherheit nachweisen möchten. Sie bestimmt, wie sensibel Ihr A/B Testing auf Veränderungen reagiert.
- Konfidenzniveau: gibt an, wie wahrscheinlich es ist, dass der Unterschied zwischen Ihrer erwarteten Konversionsrate und der Konversionsrate einer Testvariante nicht zufällig entstanden ist. Als gängiger Standard gelten hierbei 95 Prozent. Der zugehörige Z-Wert liegt bei 1,96.
- Teststärke: beschreibt die Wahrscheinlichkeit, dass Ihr Test einen tatsächlich vorhandenen Effekt auch erkennt. Üblicherweise wird hier mit 80 Prozent gearbeitet. Das bedeutet, Sie haben eine 80-prozentige Chance, eine echte Gewinner-Variante zu identifizieren. Der entsprechende Z-Wert beträgt 0,84.

Zum Glück gibt es inzwischen zahlreiche Online-Tools, die Ihnen diese Berechnungen abnehmen. In den meisten Fällen reicht es aus, die zuvor genannten Variablen in die Tools einzugeben und Sie erhalten sofort eine verlässliche Einschätzung.
Wichtig: Sowohl die minimale Effektgröße als auch die Teststärke beeinflussen die Stichprobengröße eines Tests. Wenn Sie eine höhere Teststärke anstreben oder eine kleinere minimale Effektgröße festlegen, muss Ihre Stichprobe entsprechend größer sein. Das wirkt sich wiederum auf die Laufzeit des Tests und den erforderlichen Ressourceneinsatz aus.
Irgendwann stellt sich daher die Frage, ob dieser zusätzliche Aufwand lohnenswert ist.
Verschiedene Ansätze zur Berechnung des Stichprobenumfangs
Viele Plattformen empfehlen, die Stichprobengröße eines A/B-Tests erst in der Planungsphase direkt vor dem Test zu berechnen. Aus Sicht von AB Tasty ist das bereits zu spät. Es könnte sich herausstellen, dass die benötigte Stichprobe zu groß ist und der Test dadurch zu lange laufen würde, um praktisch umsetzbar zu sein. In solchen Fällen lohnt es sich schlicht nicht, die Testvariante überhaupt zu erstellen.
Aus diesem Grund hat AB Tasty einen MDE-Rechner entwickelt, der bereits vor der eigentlichen Testplanung ansetzt. Damit können Sie frühzeitig abschätzen, welche minimale Effektgröße erforderlich ist und wie lange ein Experiment basierend auf Ihren realen historischen Daten laufen müsste, um das Konfidenzniveau zu erreichen. So arbeiten Sie von Anfang an mit realistischen Erwartungen.
Die Nutzung unseres MDE-Rechners ist unkompliziert:
Eingeben
Erwartete Konversionsrate definieren
Geben Sie Ihre aktuellen Website-Besucherzahlen sowie die Konversionsrate für das Ziel ein, das Sie verbessern möchten.
Berechnen
Chancen identifizieren
Der Rechner schätzt die für das Konfidenzniveau erforderliche Mindesteffektgröße. Sie sehen, wie viele Tage es dauert, bis Ihr Konfidenzniveau erreicht ist.
Starten
Verlust vermeiden
Verschwenden Sie keine Zeit und Ressourcen für Tests, die voraussichtlich keine schlüssigen oder statistisch signifikanten Ergebnisse liefern werden.
Außerdem steht Ihnen ein Rechner für Stichprobengrößen zur Verfügung. Damit können Sie die benötigte Anzahl an Website-Besuchern für Ihren Test bestimmen. Sie können darüber hinaus abschätzen, wie lange Ihr Test laufen sollte, um die gewünschten Ergebnisse zu erzielen. Dieses Tool ist ideal für laufende Tests, weniger für die Planungsphase vor einem Test.
So schätzen Sie die Zahl der Website-Besucher ein:
- Sie geben die aktuelle Konversionsrate für das Ziel ein, das Sie verbessern möchten, sowie die erwartete minimale Effektgröße zwischen den Testvarianten.
- Unser Rechner schätzt dann die erforderliche Anzahl an Website-Besuchern pro Testvariante.
So berechnen Sie die Dauer Ihres A/B-Tests:
- Zusätzlich zu den im vorherigen Schritt eingegebenen Informationen fügen Sie die durchschnittliche Anzahl der täglichen eindeutigen Website-Besucher (Unique Visitors) einer getesteten Seite sowie die Gesamtzahl der Testvarianten einschließlich der Kontrollversion hinzu.
- Unser Rechner schätzt dann die minimal erforderliche Testdauer in Tagen, um die gewünschten Ergebnisse zu erzielen. Dabei gibt es jedoch einen wichtigen Punkt zu beachten, den wir im nächsten Abschnitt erläutern.
Best Practices und Fallstricke
Sehen wir uns nun einige der wichtigsten Dos und Don’ts an, die Sie bei der Berechnung der Testdauer und des Stichprobenumfangs beachten sollten.
1. Testen Sie für mindestens 14 Tage
Selbst wenn Sie Ihre erforderliche Stichprobengröße bereits nach wenigen Tagen erreichen oder der Rechner eine kürzere Testdauer nahelegt, gilt es als Best Practice, einen A/B-Test mindestens zwei Wochen laufen zu lassen. So werden Schwankungen im Nutzerverhalten besser ausgeglichen, etwa Unterschiede zwischen Wochentagen und Wochenenden. Ihre Datenbasis wird dadurch deutlich belastbarer.
2. Berücksichtigen Sie externe Faktoren wie saisonale Schwankungen
Bestimmte Zeitpunkte im Jahr, etwa Weihnachten, Ostern oder lange Wochenenden, können Ihre Ergebnisse stark verzerren. Wenn Ihre Stichprobe Ihre Zielgruppe realistisch abbilden soll, berücksichtigen Sie solche Sondereffekte bei Ihren Testläufen.
3. Beenden Sie Tests nicht zu früh
Sie sollten außerdem der Versuchung widerstehen, Tests bereits vor Erreichen der geplanten Testdauer oder Stichprobengröße auszuwerten. Andernfalls steigt das Risiko für falsche Schlussfolgerungen.
Unser KI-Agent „Evi Analysis“ stützt sich auf das Konfidenzniveau, um eine Gewinner-Variante zu ermitteln. Damit er seine Aufgabe korrekt erfüllen kann, sollte Evi erst dann Ergebnisse interpretieren, wenn der Test die vom Stichprobengrößen-Rechner empfohlene Besucherzahl erreicht hat.
Denn: Evi Analysis kann nicht wissen, dass Sie ursprünglich eine Stichprobengröße von zum Beispiel 100.000 Website-Besuchern geplant hatten, sich danach aber entschieden haben, den Test nach nur 10.000 Besuchern zu beenden.
4. Überprüfen Sie die Machbarkeit
Auch wenn Testergebnisse statistisch signifikant sein sollten, bedeutet das nicht automatisch, dass sie für Ihr Unternehmen einen praktischen Nutzen haben. Eine Änderung, die aus Testergebnissen abgeleitet wurde, kann so kostspielig sein, dass es sich möglicherweise gar nicht erst lohnt, den Test durchzuführen.
5. Legen Sie den Fokus auf Seiten mit hohem Traffic
Zu Beginn sollten Sie Ihre Tests auf die Seiten Ihrer Website konzentrieren, die den meisten Traffic erhalten. Dazu zählen beispielsweise die Startseite, Kategorieseiten (PLPs) und Produktseiten (PDPs). Durch das höhere Besucheraufkommen auf diesen Seiten sammeln Sie schneller ausreichend Daten und bringen Ihre Tests zügiger zum Abschluss.
6. Begrenzen Sie die Anzahl der Varianten
Das gleichzeitige Testen mehrerer Varianten mag effizient erscheinen, erhöht jedoch das Risiko von falsch-positiven Ergebnissen. Wenn Sie Tests auf Seiten mit geringem Besucheraufkommen durchführen, ist es daher sinnvoll, mit weniger Varianten zu arbeiten. So vermeiden Sie, dass sich die Stichprobe auf zu viele Testgruppen verteilt und die Ergebnisse an Aussagekraft verlieren.
7. Stellen Sie Ihre Tests möglichst breit auf
Führen Sie nach Möglichkeit A/B-Tests in mehreren Ländern oder Marktsegmenten durch, um den Stichprobenumfang zu vergrößern.
Fazit: Von wagen Vermutungen zu konkretem Wachstum
Die Berechnung der richtigen Stichprobengröße für Ihre A/B-Tests ist der Schlüssel zu verlässlichen, statistisch signifikanten Ergebnissen. Und das Beste: Um Ihre Stichprobengröße zu ermitteln, müssen Sie heutzutage kein Mathegenie mehr sein.
Nutzen Sie unseren MDE-Rechner für die Planungsphase Ihrer Tests und halten Sie sich an die Best Practices für Stichprobengröße und Testdauer. So stellen Sie sicher, dass Ihre A/B-Tests sowohl effektiv als auch zuverlässig sind.
Sind Sie bereit, das Rechnen hinter sich zu lassen und mit der Umsetzung zu beginnen?
Häufige Fragen zur Berechnung der Stichprobengröße bei A/B-Tests
Haben Sie noch Fragen zur Berechnung der Stichprobengröße? Hier finden Sie die Antworten, die Sie suchen.
Warum ist die Berechnung der Stichprobengröße bei A/B-Tests wichtig?
Die Berechnung der Stichprobengröße stellt sicher, dass Ihr Test über genügend Aussagekraft verfügt. Es sollte ein signifikanter Unterschied zwischen den Varianten festgestellt werden, ohne dabei Ressourcen zu verschwenden. Eine zu kleine Stichprobe kann zu falsch-negativen Ergebnissen führen, während eine zu große Stichprobe ineffizient ist oder unnötig viele Nutzer einbezieht.
Welchen Ansatz sollte ich zur Berechnung des Stichprobenumfangs verwenden?
In der Regel verwendet man eine Leistungsanalyse, welche die erwartete Effektgröße, das Konfidenzniveau (α) und die gewünschte Teststärke (1−β) berücksichtigt. Hilfsmittel wie Online-Rechner oder Statistiksoftware können dabei helfen; sie basieren je nach der gewählten Metrik auf einer binomialen oder einer normalen Näherung.
Wie bestimmt man die minimale Effektgröße (MDE) für einen A/B-Test?
Die MDE ist die kleinste Veränderung zwischen Ihrer Kontroll- und Ihrer Variantenversion, die Sie als praktisch signifikant erachten. Dieser Wert wird auf der Grundlage von Geschäftszielen, erwarteten Konversionsraten und der von Ihnen angestrebten Teststärke berechnet. In der Regel legen Sie fest, welcher Anstieg der Kennzahlen (z. B. Klickrate/CTR, Umsatz) die Einführung der neuen Variante rechtfertigen würde.

Über den Autor
Hubert Wassner
Hubert Wassner ist Chief Data Scientist bei AB Tasty, wo er seit über einem Jahrzehnt seine Erfahrung in Künstlicher Intelligenz und Maschinellem Lernen in die Welt der Experimente einbringt. Mit seinem fundierten akademischen Hintergrund in Computerwissenschaften ist Hubert der leitende Entwickler der ausgeklügelten statistischen Modelle, auf denen die AB Tasty-Plattform basiert. Damit trägt er dazu bei, dass Marken wichtige Entscheidungen mit vollstem Vertrauen treffen können.
Er schreibt zudem regelmäßig Beiträge für den AB Tasty-Blog. Hier liegt sein Fokus darauf, komplexe datenwissenschaftliche Konzepte wie die Bayes’sche Statistik oder prädiktive KI verständlich zu erklären und in praktische Strategien für digitales Wachstum zu verwandeln. Mit dem Ziel, die Kluft zwischen anspruchsvoller Technik und praktischer Geschäftsanwendung zu überbrücken, hilft Hubert Marken dabei, die technische Evolution des digitalen Zeitalters mit Klarheit, Präzision und einem Fokus auf menschenzentrierte Innovation zu meistern.