Comprendre facilement le calcul de la taille d’échantillon pour les tests A/B
Le processus de test A/B est conçu pour fournir des résultats fiables, afin que vous puissiez prendre des décisions fondées sur des données concrètes. Cependant, définir la taille d’échantillon nécessaire pour que ces résultats soient fiables peut dépendre de plusieurs facteurs. Heureusement, il existe aujourd’hui des outils en ligne qui vous aident à éviter les approximations, sans qu’il soit nécessaire d’avoir un diplôme en mathématiques.

Comment fonctionne le calcul de la taille de l’échantillon
La raison principale pour laquelle il est important de calculer une taille d’échantillon adaptée est de s’assurer que celui-ci soit représentatif de l’ensemble de votre public. Cela garantira ainsi la fiabilité des résultats de votre test et vous aidera à éviter les faux positifs et les faux négatifs. Si votre échantillon est trop petit, vous risquez d’obtenir des résultats trompeurs. S’il est trop grand, vous risquez de gaspiller du temps et des ressources sans obtenir des résultats exploitables.
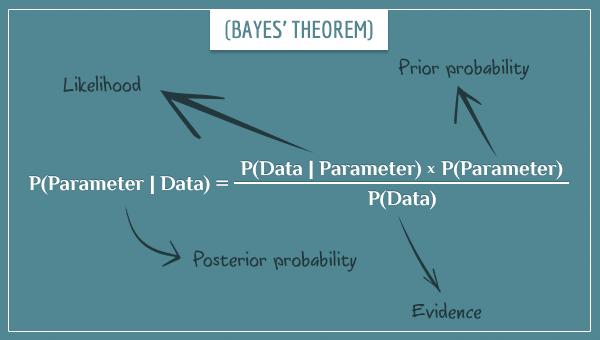
En règle générale, il est recommandé de disposer d’un échantillon d’au moins 10 000 visiteurs par variante de test et d’au moins 300 conversions pour chacune d’entre elles. Cependant, vous pouvez calculer la taille d’échantillon adéquate pour une variante de test A/B à l’aide de la formule mathématique suivante :
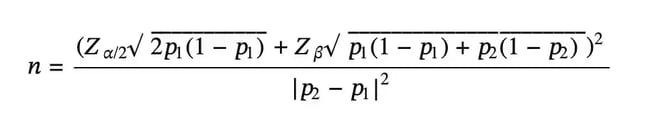
Voici la signification de chaque lettre dans l’équation :
- n correspond à la taille d’échantillon requise pour chaque variante de test
- p1 correspond au taux de conversion de référence
- p2 correspond au taux de conversion augmenté de l’effet minimal détectable absolu
- Z⍺/2 correspond au score Z pour le niveau de signification statistique
- Zβ est le score Z de la puissance statistique
Cette équation vous paraît complexe ? Avant de vous précipiter sur votre manuel d’algèbre, pas de panique ! Voyons plutôt ce que ces variables représentent en pratique :
- Taux de conversion de référence : le taux de conversion actuel pour l’objectif spécifique que vous cherchez à améliorer. Il peut s’agir, par exemple, du taux d’abonnement, du taux de transaction ou du taux de clics.
- Effet minimal détectable (MDE) : la plus petite variation du taux de conversion que vous souhaitez détecter avec une fiabilité statistique. Cela détermine la sensibilité statistique de votre test A/B.
- Niveau de signification statistique : la probabilité que la différence entre votre taux de conversion de référence et le taux de conversion d’une variante testée ne soit pas due au hasard. Le niveau de signification généralement utilisé est de 95 %. Le score Z correspondant à un niveau de signification de 95 % est de 1,96.
- Puissance statistique : la probabilité que votre test détecte un effet réel lorsqu’il existe. Là encore, la pratique courante consiste à fixer la puissance à 80 %, ce qui signifie que vous avez 80 % de chances de repérer un effet significatif. Le score Z correspondant à une puissance de 80 % est de 0,84.

Heureusement, il existe aujourd’hui toute une gamme d’outils en ligne qui se chargent pour vous de ce calcul parfois complexe. Pour la plupart d’entre eux, il suffit généralement de saisir les variables indiquées ci-dessus.
Il convient de noter que l’effet minimal détectable (MDE) et la puissance statistique ont tous deux une incidence directe sur la taille de l’échantillon d’un test. Si vous souhaitez obtenir une puissance statistique plus élevée (c’est-à-dire plus de chances d’identifier une variante gagnante) ou un MDE plus faible (c’est-à-dire une plus grande sensibilité du test), votre échantillon devra être plus important. Cela peut avoir une incidence sur la durée d’exécution d’un test et sur les ressources nécessaires.
Il faut alors évaluer si l’investissement en vaut la peine.
Différentes méthodes de calcul de la taille de l’échantillon
De nombreuses plateformes en ligne recommandent de calculer la taille de l’échantillon d’un test A/B lors de la phase de préparation du test. Mais chez AB Tasty, nous estimons qu’il est déjà trop tard. En effet, si vous constatez que la taille d’échantillon requise est trop importante, ce qui signifie que le test devrait durer trop longtemps pour être réalisable dans la pratique, il est alors tout simplement inutile de créer la variante.
C’est pourquoi nous avons développé un calculateur de MDE spécialement conçu pour la phase de préparation des tests. Cet outil vous aide à déterminer le gain minimal requis et le temps nécessaire pour qu’une expérience atteigne la signification statistique, en se basant sur vos données historiques réelles. Vous pourrez ainsi définir des attentes réalistes avant de lancer un test.
Utiliser notre calculateur d’effet minimal détectable est très simple :
Saisie
Définissez votre référence
Saisissez votre volume actuel de visiteurs et le taux de conversion associé à l’objectif que vous souhaitez améliorer.
Calcul
Évaluez le potentiel du test
Le calculateur estime le gain minimal nécessaire pour atteindre le seuil de signification statistique. Visualisez précisément le nombre de jours nécessaires pour atteindre votre seuil de confiance.
Lancement
Évitez les tests inutiles
Évitez de perdre du temps et des ressources sur des tests qui ont peu de chances de générer des résultats exploitables ou statistiquement significatifs.
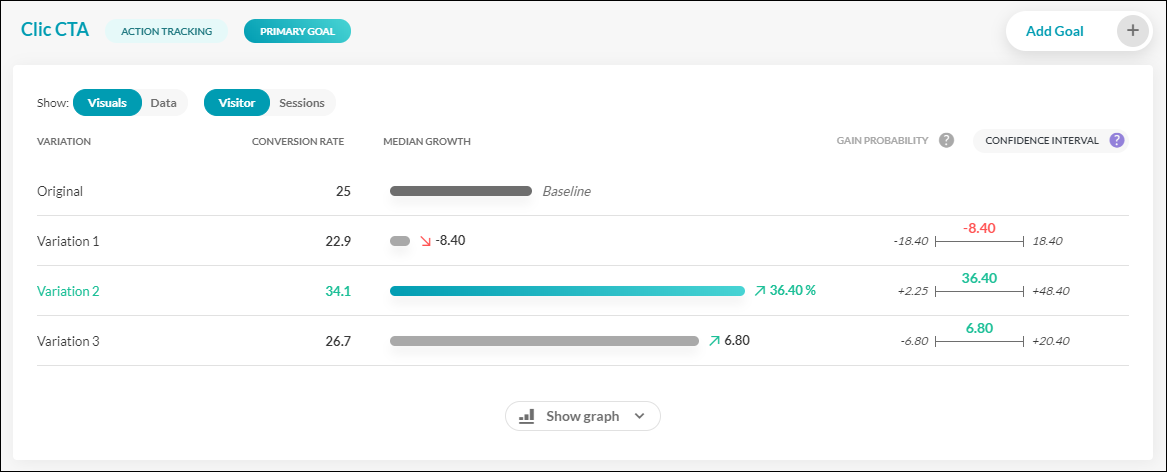
Nous proposons également un calculateur d’échantillon qui vous aide à déterminer le nombre de visiteurs requis pour votre test et à estimer la durée nécessaire pour obtenir les résultats souhaités. Cet outil est destiné aux tests en cours et ne doit pas être utilisé pour la phase de préparation des tests.
Pour estimer le nombre de visiteurs :
- Vous saisissez le taux de conversion actuel pour l’objectif que vous cherchez à améliorer, ainsi que l’augmentation attendue entre les différentes variantes du test.
- Notre calculateur estime ensuite le nombre de visiteurs nécessaires pour chaque variante du test.
Pour estimer la durée de votre test A/B :
- En plus des informations saisies à l’étape précédente, vous devez indiquer le nombre moyen de visiteurs quotidiens de la page testée ainsi que le nombre total de variantes du test, y compris la version de référence.
- Notre calculateur estime ensuite la durée minimale nécessaire du test, en jours, pour obtenir les résultats souhaités. Cette estimation doit toutefois être interprétée avec précaution, comme expliqué ci-dessous.
Bonnes pratiques et pièges à éviter
Voyons les principales bonnes pratiques et erreurs à éviter lors du calcul de la durée des tests et de la taille de l’échantillon.
1. Effectuez des tests pendant au moins 14 jours
Même si vous atteignez votre taille d’échantillon cible en quelques jours, ou si notre calculateur de durée de test indique le contraire, il est recommandé de mener un test A/B pendant au moins deux semaines. Cela permet de tenir compte des variations dans le comportement des utilisateurs, comme les variations de trafic entre semaine et week-end, et garantit une bien plus grande fiabilité de vos données.
2. Tenez compte des facteurs externes tels que la saisonnalité
Certaines périodes de l’année, comme Noël, le Black Friday ou les ponts et jours fériés, peuvent fausser vos résultats si vous effectuez un test à ces moments-là. Vous devrez en tenir compte si vous souhaitez que votre échantillon reste représentatif de votre audience habituelle.
3. N’interrompez pas un test trop tôt
Vous devez également résister à la tentation de consulter les résultats du test avant que la durée prévue et la taille de l’échantillon aient été atteintes. Cela augmenterait considérablement le risque de tirer de mauvaises conclusions concernant le test.
Notre agent IA Evi Analysis s’appuie sur la signification statistique pour vous indiquer si une variante obtient de meilleurs résultats. Pour qu’il fonctionne correctement, vous ne devez demander à Evi d’interpréter les résultats qu’une fois que le test a atteint le nombre de visiteurs recommandé par le calculateur de taille d’échantillon. En effet, Evi Analysis n’a aucun moyen de savoir que vous aviez prévu une taille d’échantillon de, disons, 100 000 visiteurs, mais que vous avez décidé d’arrêter après seulement 10 000.
4. Ne négligez pas la valeur pratique
Le fait que les résultats d’un test soient statistiquement significatifs ne signifie pas pour autant qu’ils aient une application concrète pour votre entreprise. Si la mise en œuvre d’un changement suggéré par les résultats d’un test s’avère trop coûteuse, il n’est peut-être pas utile de réaliser ce test.
5. Donnez la priorité aux pages les plus consultées
Dans un premier temps, les tests doivent se concentrer sur les pages de votre site web susceptibles d’attirer le plus grand nombre de visiteurs. Il s’agit par exemple de la page d’accueil, des pages de listing de produits (PLP) ou des pages produits (PDP). Le trafic plus important sur ces pages vous permettra de collecter des données plus rapidement et de mener des tests plus efficacement.
6. Limitez le nombre de variantes
Tester plusieurs variantes à la fois peut sembler plus efficace, mais cela augmente le risque de faux positifs. Si vous effectuez des tests sur des pages à faible trafic, le fait de limiter le nombre de variantes permet de ne pas diluer l’échantillon entre trop de versions.
7. Ciblez un large public
Dans la mesure du possible, effectuez des tests A/B dans plusieurs pays ou sur plusieurs segments afin d’augmenter la taille de l’échantillon.
Conclusion : passer de l’intuition à des résultats concrets
Déterminer la taille d’échantillon adéquate pour vos tests A/B est essentiel pour obtenir des résultats statistiquement significatifs auxquels vous pouvez vous fier. Mais vous n’avez plus besoin d’être un as en maths pour déterminer la taille d’échantillon nécessaire.
En utilisant notre calculateur de MDE pour la planification préalable des tests et en respectant les bonnes pratiques en matière de taille de l’échantillon et de durée des tests, vous vous assurez que vos tests A/B seront à la fois plus efficaces et plus fiables.
Prêt à passer du calcul à la conversion ?
FAQ
Vous avez encore des questions sur les calculateurs de taille d’échantillon ? Voici les réponses dont vous avez besoin.
Pourquoi le calcul de la taille de l’échantillon est-il important dans les tests A/B ?
Le calcul de la taille de l’échantillon garantit une puissance suffisante à votre test pour identifier une différence significative entre les variantes testées, sans mobiliser des ressources de manière excessive. Un échantillon trop petit peut entraîner des faux négatifs, tandis qu’un échantillon trop grand peut s’avérer inefficace ou exposer inutilement trop d’utilisateurs.
Quelle méthode dois-je utiliser pour calculer la taille de l’échantillon ?
En général, on s’appuie sur une analyse de puissance qui intègre l’effet attendu, le niveau de signification (α) et la puissance souhaitée (1−β). Des outils tels que des calculateurs en ligne ou des logiciels statistiques peuvent s’avérer utiles ; ils reposent sur une approximation binomiale ou normale, selon la métrique analysée.
Comment détermine-t-on l’effet minimal détectable (MDE) pour un test A/B ?
Le MDE désigne la plus petite variation entre la version de référence et une variante que vous jugez suffisamment pertinente. Il est calculé en fonction des objectifs commerciaux, des taux de conversion de référence et de la puissance statistique souhaitée, en identifiant le niveau d’amélioration des indicateurs ( taux de clics, chiffre d’affaires) qui justifie le déploiement de la variante.

À propos de l’auteur
Hubert Wassner
Hubert Wassner est Chief Data Scientist chez AB Tasty avec plus de trente ans d’expérience en intelligence artificielle et en apprentissage automatique. Il conçoit des modèles statistiques avancés, publie ses analyses sur le blog et aide les marques à prendre des décisions fiables basées sur les données. Sa réalisation la plus récente est l’obtention d’un brevet pour RevenueIQ.