Pour lancer une dynamique d’expérimentation au sein d’une entreprise, Lukas Vermeer recommande de démarrer par de petits objectifs simples.
Lukas Vermeer a pris ce conseil très au sérieux lorsqu’il a plongé tête baissée dans le monde de l’IA et du machine learning aux premiers stades de leur développement, alors que la demande du secteur était encore faible. Par des missions de conseil auprès de diverses entreprises, Lukas a découvert son environnement de travail idéal : une scale-up , dans laquelle il pouvait mettre à profit son expertise en matière de données et de machine learning.
C’est là qu’intervient Booking.com. Lukas a rejoint l’agence néerlandaise de voyages en ligne en pleine phase d’expansion et a par la suite dirigé l’équipe expérimentation pendant 8 ans, faisant passer l’équipe de 3 à 30 personnes.
Une fois l’équipe expérimentation de Booking.com arrivée à maturité, Lukas s’est lancé dans une nouvelle aventure en 2021 pour rejoindre Vista en tant que directeur de l’expérimentation. Il construit et façonne la culture de l’expérimentation et exploite le potentiel des données pour renforcer l’impact de Vista en tant que leader dans le secteur des solutions design et marketing pour les petites entreprises.
Lukas a échangé avec Marylin Montoya, VP Marketing chez AB Tasty, à propos du processus et de la culture de l’expérimentation : depuis les méthodes jusqu’aux rôles des équipes impliquées dans l’expérimentation. Voici quelques éléments essentiels à retenir de leur conversation.
.
Expérimentez de manière stratégique
Il est primordial de connaître le but de votre expérimentation. Lukas conseille de concentrer ses efforts sur les tests de fonctionnalités majeures capables de générer un réel changement ou d’avoir un impact sur les résultats de l’entreprise, plutôt que sur le design de l’UI.
Demandez- vous : “Quelles grandes questions motivent actuellement votre business case ? Quelles sont les principales hypothèses sur lesquelles repose votre planification stratégique ?”, dit-il. Plutôt que d’augmenter la quantité d’expérimentations, il vaut mieux se concentrer sur des expérimentations plus importantes mais correctement exécutées.
Pour mettre en place une culture de l’expérimentation au sein d’une organisation, Lukas suggère d’utiliser la méthode de la flywheel. La première expérimentation doit attirer l’attention en divisant l’opinion des employés quant à savoir si elle fonctionnera. Cela démontre qu’il peut être difficile de prédire le succès des expérimentations soulignant ainsi “la valeur non-quantifiable de l’expérimentation”. Nous devons reconnaître que tout comme il est essentiel de ne pas livrer un mauvais produit (qui pourrait faire baisser les revenus), il est tout aussi crucial d’avoir une idée stratégique des investissements à réaliser à l’avenir.
Structurez votre organisation pour réussir vos expérimentations
La structure de votre entreprise et de vos équipes va jouer sur la fluidité de mise en œuvre de vos expérimentations. Le conseil de Lukas ? L’équipe développement de produits doit s’approprier complètement les expérimentations.
L’équipe expérimentation doit quant à elle faciliter les expérimentations en fournissant les outils, la formation et l’assistance technique à l’équipe développement de produits, qui pourra ensuite mener les expérimentations en toute autonomie.
En formant les product managers au processus d’expérimentation (en leur montrant par exemple les différents tests et outils à leur disposition, leurs points forts et leurs points faibles, les hypothèses à formuler et le bon moment pour les utiliser), ils peuvent tester leurs idées en toute autonomie et prendre une décision en s’appuyant sur un portfolio de méthodes expérimentales.
Toutefois, l’expérimentation revêt également un aspect social qu’il ne faut pas négliger. Au vu de la nature subjective de l’interprétation et de l’analyse de données, Lukas souligne l’importance d’un échange sur les résultats et d’un retour sur le processus d’expérimentation afin de l’optimiser.
“Tout l’intérêt d’une expérimentation (…) consiste à motiver une décision, et cette décision doit être appuyée par les preuves dont on dispose”, déclare Lukas. Tout comme les scientifiques soumettent leurs articles à des pairs avant publication, les expérimentations basées sur une méthode scientifique doivent suivre les mêmes lignes directrices en documentant dans le reporting l’hypothèse, la méthode, les résultats et les conclusions (une opinion partagée par Jonny Longden, invité du podcast 1,000 Experiments Club).
Le pire ennemi de la culture de l’expérimentation : leadership ou roadmaps ?
Dans le domaine du développement de produit, Lukas indique que lorsque l’on parle de “roadmaps”, il ne s’agit pas tout à fait de cela. Il s’agit plutôt d’une liste linéaire d’étapes qui sont censées permettre d’atteindre un objectif. Le problème, c’est qu’il n’y a pas souvent d’itinéraires bis ou d’alternatives si l’on s’écarte du plan initial.
Il n’est pas évident de changer de cap après une première expérimentation ratée, explique Lukas. Cela s’explique par le concept “d’escalade de l’engagement”, c’est à dire que plus vous investissez de temps et d’énergie dans quelque chose, et plus il est difficile de changer de cap.
Alors, est-il temps d’abandonner totalement les roadmaps ? Selon Lukas, elles devraient simplement servir à reconnaître l’existence d’une incertitude inhérente. Le développement de produit est rempli d’inconnues, et elles n’apparaissent que lorsque les produits sont conçus et montrés aux clients. C’est pour cela que le modèle construire-mesurer-apprendre fonctionne : parce que l’on avance de quelques pas avant de vérifier si l’on prend la bonne direction.
Lukas souligne que l’objectif ne devrait pas être de “livrer un produit finalisé dans deux mois” mais plutôt, d’intégrer l’incertitude aux livrables et d’énoncer l’objectif en conséquence. Par exemple, vérifier si les clients réagissent de la manière souhaitée.
Que pouvez-vous apprendre d’autre de notre conversation avec Lukas Vermeer ?
Quand expérimenter et comment bâtir une culture de l’expérimentation
L’importance de l’autonomie des équipes expérimentation
Les trois niveaux de l’expérimentation : méthode, conception, exécution
Comment accélérer le processus d’expérimentation
A propos de Lukas Vermeer
Lukas Vermeer est un expert de l’implémentation et de la mise à l’échelle de l’expérimentation, doté également d’une expérience dans le domaine de l’IA et du machine learning. Actuellement, Lukas est directeur de l’expérimentation chez Vista. Avant cela, il a passé plus de huit ans chez Booking.com où il a exercé les postes de data scientist et de responsable produit, avant d’être nommé directeur de l’expérimentation. Il continue de proposer son expertise en tant que consultant pour des entreprises qui commencent à intégrer l’expérimentation. Son tout dernier article coécrit “It Takes a Flywheel to Fly: Kickstarting and Keeping the A/B Testing Momentum,” aide les entreprises à débuter et à accélérer le processus d’expérimentation grâce à la flywheel “l’investissement suit la valeur, qui suit l’investissement”.
A propos de 1,000 Experiments Club
Le 1,000 Experiments Club est un podcast produit par AB Tasty et animé par Marylin Montoya, VP Marketing chez AB Tasty. Rejoignez Marylin et l’équipe marketing alors qu’ils s’entretiennent avec les experts les plus compétents du monde de l’expérimentation pour découvrir leurs points de vue sur ce qu’il faut faire pour créer et exécuter des programmes d’expérimentation réussis.
Rejoignez Marylin Montoya, VP Marketing pour une immersion dans le monde de l’expérimentation
Aujourd’hui, nous tendons le micro à Marylin Montoya, VP Marketing d’AB Tasty, pour donner le coup d’envoi de notre nouvelle série de podcasts, le « 1,000 Experiments Club ».
Chez AB Tasty, nous sommes un groupe de product designers, software engineers et spécialistes du marketing (alias « Magic Makers ») qui s’efforce de créer une culture de l’expérimentation. Nous voulions aller au-delà de la théorie de haut niveau de l’expérimentation et nous pencher sur les éléments de base de la gestion des programmes d’expérimentation et des expériences digitales.
Découvrez : « 1,000 Experiments Club », le podcast qui vous permet de réussir l’expérimentation à grande échelle. Notre podcast réunit une sélection des leaders les plus brillants pour découvrir leurs idées sur la façon d’expérimenter et d’échouer… avec succès.
Dans chaque épisode, Marylin s’entretient avec nos invités, qu’il s’agisse de géants de la technologie, de start-ups en hypercroissance ou d’agences de conseil. Chacun d’entre eux a un point de vue unique sur la manière dont ils ont fait de l’expérimentation le fondement de leurs stratégies de croissance.
Vous apprendrez pourquoi l’échec fait partie du processus, comment faire de vos metrics vos alliés les plus fiables, comment adapter l’expérimentation à la taille de votre entreprise et comment obtenir le soutien de la direction si vous débutez. Notre podcast s’adresse aux experts en CRO, aux product managers, aux software engineers ; chacun y trouvera son compte, quelle que soit sa position sur le modèle de maturité de l’expérimentation !
Nous donnons le coup d’envoi avec trois épisodes, dans lesquels chaque invité revient sur son parcours, les erreurs qu’il a commises, mais aussi les succès qu’il a retirés de décennies d’expérimentation, d’optimisation et de développement de produits.
Il pense que tout le monde peut et doit faire de l’expérimentation
Dans la culture de l’expérimentation, il n’existe pas d’expérience « ratée ». Chaque test est une occasion d’apprendre et de construire des idées nouvelles et meilleures. Alors, écoutez et abonnez-vous au « 1,000 Experiments Club » sur Apple Podcasts, Spotify ou sur tout autre site de podcasts.
L’expérimentation convient-elle à tout le monde ? Un oui retentissant, affirme Jonny Longden. Tout ce dont vous avez besoin, ce sont deux ingrédients : une forte volonté et de la ténacité pour l’implémenter.
Il existe un mythe dangereux, à savoir l’idée qu’il faut être une grande entreprise pour pratiquer l’expérimentation. En réalité, ce sont les plus petites entreprises et les start-ups qui ont le plus besoin d’expérimenter, affirme Jonny Longden, de l’agence de marketing à la performance Journey Further.
Fort de plus de dix ans d’expérience dans l’optimisation des conversions et la personnalisation, Jonny a cofondé Journey Further pour aider les clients à intégrer l’expérimentation au cœur de leurs activités. Il dirige actuellement la division conversion de l’agence, qui se concentre également sur le PPC, le SEO, les RP – parmi d’autres spécialisations marketing.
Toute entreprise qui souhaite dénicher une quelconque découverte devrait recourir à l’expérimentation, en particulier les start-ups qui sont dans la phase exploratoire de leur développement. « L’expérimentation ne requiert aucune taille : tout dépend de la façon dont on l’aborde », a déclaré Jonny à Marylin Montoya, VP marketing d’AB Tasty.
Voici quelques-uns des éléments que nous avons retenus de notre vaste discussion avec Jonny.
.
La démocratisation de l’expérimentation
On a tendance à voir davantage d’équipes et de programmes d’expérimentation dans les grandes entreprises, mais cela ne signifie pas nécessairement que d’autres entreprises de tailles différentes ne peuvent pas tremper leurs orteils dans le bassin de d’expérimentation. Les petites entreprises et les start-ups peuvent également en bénéficier, à condition qu’elles aient la ténacité et les capacités de l’implémenter.
Vous devez vraiment croire que sans expérimentation, vos idées ne fonctionneront pas, dit Jonny. Il y a des choses dont vous pensez qu’elles vont fonctionner et qui ne le font pas. À l’inverse, il y a beaucoup de choses qui ne semblent pas fonctionner mais qui finissent par avoir un impact positif. La seule façon d’arriver à cette conclusion est d’expérimenter.
En fin de compte, les plus grandes découvertes (par exemple, dans le domaine de l’espace, des voyages, de la médecine, etc.) sont issues d’une méthodologie scientifique, qui se résume à l’observation, aux hypothèses, aux tests et au perfectionnement. Abordez l’expérimentation avec cet état d’esprit, et tout le monde pourra y gagner.
Établir les bonnes roadmaps avec les équipes produit
Il est important d’intégrer l’expérimentation en amont du processus de développement produit, mais la plupart des gens ne le font pas, affirme Jonny. D’un point de vue purement commercial, il s’agit d’essayer de réduire les risques liés au développement et de prouver la valeur d’un changement ou d’une fonctionnalité avant d’investir davantage de temps, d’argent et de bande passante.
Heureusement, la méthodologie agile employée par de nombreuses équipes modernes est similaire à l’expérimentation. Toutes deux reposent sur une collaboration itérative avec le client et un cycle de recherche rigoureux, de collecte de données quantitatives et qualitatives, de validation et d’itération. Le point idéal est la collecte de données quantitatives et qualitatives – un bon équilibre entre le feedback et le volume.
Pour réussir à établir une roadmap pour un programme d’expérimentation, il faut comprendre la structure organisationnelle d’une entreprise ou d’un secteur. Dans les entreprises SaaS, l’expérimentation est intégrée aux équipes produit ; pour les entreprises d’e-commerce, l’expérimentation s’intègre mieux dans la partie marketing. Une fois que vous avez déterminé le responsable et les objectifs de l’expérimentation, vous devez déterminer si vous pouvez déployer efficacement les tests et si vous disposez des bons processus pour implémenter les résultats d’un test.
L’expérimentation est, en définitive, l’innovation
Plus vous expérimentez, plus vous créez de la valeur. L’expérimentation à grande échelle permet aux gens d’apprendre et de construire d’autres tests sur la base de ces apprentissages. N’utilisez pas les tests pour identifier uniquement les gagnants, car il y a beaucoup plus de connaissances à tirer des tests qui échouent. Par exemple, il se peut que seul un test sur dix fonctionne. La véritable valeur réside dans les 9 leçons que vous avez acquises, et pas seulement dans le seul test qui a eu un impact positif.
Si vous regardez les choses sous cet angle, vous vous rendrez compte que la recherche post-test et les actions qui en découlent sont essentielles : c’est là que vous commencerez à faire des progrès vers une plus grande innovation.
Jonny appelle cela l’effet boule de neige de l’expérimentation. L’expérimentation est l’innovation – lorsqu’elle est bien menée. À la base, il s’agit d’explorer et de voir comment vos clients réagissent. Et tant que vous tirez des enseignements des résultats de vos tests, vous serez en mesure d’innover plus rapidement, précisément parce que vous vous appuyez sur ces leçons. C’est ainsi que l’on conduit une innovation qui fonctionne réellement.
Que pouvez-vous apprendre d’autre de notre conversation avec Jonny Longden ?
Passer de l’expérimentation à la validation
Comment maintenir la créativité pendant l’expérimentation
Utiliser le CRO pour identifier les bonnes questions à résoudre
Les éléments nécessaires à une expérimentation réussie
A propos de Jonny Longden
Jonny Longden dirige la division conversion de Journey Further, une agence de marketing à la performance spécialisée dans le PPC, le SEO, les RP, etc. Basée au Royaume-Uni, cette agence et ce cabinet de conseil aident les entreprises à s’appuyer sur les données et à intégrer l’expérimentation dans leurs programmes. Auparavant, Jonny a consacré plus de dix ans à l’optimisation des conversions, à l’expérimentation et à la personnalisation, travaillant pour Sky, Visa, Nike, O2, Mvideo, Principal Hotels et Nokia.
A propos de 1,000 Experiments Club
Le 1,000 Experiments Club est un podcast produit par AB Tasty et animé par Marylin Montoya, VP Marketing chez AB Tasty. Rejoignez Marylin et l’équipe marketing alors qu’ils s’entretiennent avec les experts les plus compétents du monde de l’expérimentation pour découvrir leurs points de vue sur ce qu’il faut faire pour créer et exécuter des programmes d’expérimentation réussis.
Chad Sanderson présente les types d’expérimentation les plus réussis en fonction de la taille de l’entreprise et de ses ambitions de croissance
Pour Chad Sanderson, head of product – data platform chez Convoy, le rôle des données et de l’expérimentation sont inextricablement liés.
Chez Convoy, il supervise l’équipe data platform de bout en bout – qui comprend le data engineering, le machine learning, l’expérimentation, le pipeline de données – parmi une multitude d’autres équipes qui ont toute pour but d’apporter de l’aide à des milliers de transporteurs pour expédier le fret plus efficacement. Ce rôle lui a permis d’avoir une vue d’ensemble du processus, de l’idéation à l’exécution en passant par la construction.
Par conséquent, Chad a eu une place importante que la plupart des professionnels n’ont jamais : le processus d’expérimentation de bout en bout, de l’hypothèse à l’analyse et la production de rapports, jusqu’aux états financiers de fin d’année. Naturellement, il avait quelques idées à partager avec Marylin Montoya, VP marketing d’AB Tasty, lors de leur conversation sur la discipline de l’expérimentation et la complexité de l’identification de paramètres fiables.
Introduire l’expérimentation en tant que discipline
L’expérimentation, malgré toutes ses louanges, est encore relativement nouvelle. Vous aurez du mal à trouver de grandes collections de littérature ou une approche académique (bien que Ronny Kohavi ait écrit quelques réflexions sur le sujet). En outre, l’expérimentation n’est pas considérée comme une discipline de data science, surtout si on la compare aux domaines du machine learning ou du stockage de données.
Bien que l’on puisse trouver quelques conseils ici et là sur des blogs, on finit par passer à côté des connaissances techniques approfondies et des meilleures pratiques en matière de mise en place d’une plateforme, de création d’une bibliothèque de metrics et de sélection des bonnes metrics de manière systématique.
Chad attribue l’accessibilité de l’expérimentation à une arme à double tranchant. Beaucoup d’entreprises n’ont pas encore appliqué la même rigueur qu’à d’autres domaines liés à la data science, car il est facile de commencer d’un point de vue marketing. Mais à mesure que l’entreprise se développe, la maturité et la complexité de l’expérimentation augmentent également. C’est à ce moment-là que la littérature sur la création et la mise à l’échelle des plateformes est peu abondante, ce qui fait que le domaine est sous-évalué et qu’il est difficile de recruter les bons profils.
Quand l’expérimentation à petite échelle est votre meilleure chance
Lorsque l’on est une entreprise de grande envergure – comme Microsoft ou Google, avec des business units, des sources de données, des technologies et des opérations différentes – le déploiement de nouvelles fonctionnalités ou de modifications est une entreprise incroyablement risquée, étant donné que toute erreur peut avoir un impact sur des millions d’utilisateurs. Imaginez que vous introduisiez accidentellement un bug pour Microsoft Word ou PowerPoint : l’impact sur le résultat net serait préjudiciable.
Pour ces entreprises, le meilleur moyen de mener des expériences est d’adopter une approche prudente et à petite échelle. L’objectif est de se concentrer sur l’action immédiate, en attrapant les choses rapidement en temps réel et en effectuant des roll back.
En revanche, si vous êtes une startup en phase d’hypercroissance, votre approche sera très différente. Ces petites entreprises doivent généralement montrer à leurs investisseurs des gains à deux chiffres pour chaque nouvelle fonctionnalité déployée, ce qui signifie que leurs actions sont davantage axées sur la preuve de l’impact positif de la fonctionnalité et de la longévité de son succès.
Faites des métriques vos alliés de confiance
Chaque entreprise aura des indicateurs très différents en fonction de ce qu’elle recherche ; il est essentiel de définir ce que vous voulez avant de vous lancer dans l’expérimentation et la construction de votre programme.
Une question que vous devrez vous poser est la suivante : de quoi mes managers se soucient-ils ? Quels sont les objectifs de la direction ? C’est la clé pour définir le bon ensemble d’indicateurs qui fera avancer votre entreprise dans la bonne direction. Chad recommande d’établir une distinction entre les indicateurs front-end et back-end : les premiers sont facilement accessibles, les seconds le sont moins. Les indicateurs client-side, qu’il appelle indicateurs front-end, mesurent le revenu par transaction. Toutes les mesures mènent alors aux revenus, ce qui en soi n’est pas nécessairement une mauvaise chose, mais cela signifie simplement que toutes vos décisions sont basées sur la croissance des revenus et moins sur la preuve de l’évolutivité ou de l’impact gagnant d’une fonctionnalité.
Le conseil de Chad est de commencer par les problèmes de mesure que vous rencontrez, et à partir de là, de développer votre culture de l’expérimentation, de développer le système et enfin de choisir une plateforme.
Que pouvez-vous apprendre d’autre de notre conversation avec Chad Sanderson?
Des besoins d’expérimentation différents pour les équipes engineering et marketing
Construire une culture de l’expérimentation de haut en bas
L’inconvénient de la mise à l’échelle des MVPs
Pourquoi les spécialistes du marketing sont les porte-drapeaux de l’expérimentation
A propos de Chad Sanderson
Chad Sanderson est un expert de l’expérimentation digitale et de l’analyse à grande échelle. Product manager, écrivain et conférencier, il a donné des conférences sur des sujets tels que l’analyse avancée de l’expérimentation, les statistiques de l’expérimentation digitale, l’expérimentation à petite échelle pour les petites entreprises, etc. Il a précédemment travaillé en tant que gestionnaire de programme senior pour la plateforme d’IA de Microsoft. Avant cela, Chad a travaillé pour l’équipe d’expérimentation de Subway en tant que responsable de la personnalisation.
A propos de 1,000 Experiments Club
Le 1,000 Experiments Club est un podcast produit par AB Tasty et animé par Marylin Montoya, VP Marketing chez AB Tasty. Rejoignez Marylin et l’équipe marketing alors qu’ils s’entretiennent avec les experts les plus compétents du monde de l’expérimentation pour découvrir leurs points de vue sur ce qu’il faut faire pour créer et exécuter des programmes d’expérimentation réussis.
L’un des pionniers de l’expérimentation nous fait part d’une réalité qui fait réfléchir : la plupart des idées sont vouées à l’échec (et c’est une bonne chose)
Peu de personnes ont accumulé autant d’expérience que Ronny Kohavi en matière d’expérimentation. Son travail chez des géants de la tech tels qu’Amazon, Microsoft et Airbnb – pour n’en citer que quelques-uns – a permis de construire les fondations de ce qui est aujourd’hui l’expérimentation digitale.
Avant que l’idée de « build fast, deploy often » ne s’impose dans les entreprises techs, les développeurs suivaient un modèle en cascade qui prévoyait des releases moins nombreuses (parfois tous les 2 ou 3 ans). Le raccourcissement des cycles de développement au début des années 2000, grâce à la méthodologie Agile et à une hausse de l’expérimentation digitale, a créé la tempête parfaite pour une révolution du développement logiciel – et Ronny était au centre de tout cela.
Marylin Montoya, VP Marketing d’AB Tasty, a voulu découvrir les débuts de l’expérimentation avec Ronny et pourquoi l’échec est en fait une bonne chose. Voici quelques-unes des principales conclusions de leur conversation.
.
Les déploiements progressifs comme filet de sécurité
Un cycle typique d’expérimentation consiste à exposer le test à 50 % de la population pendant deux semaines en moyenne avant une diffusion progressive. Mais Ronny suggère d’aborder la question d’un point de vue différent. Commencer par une petite audience de seulement 2 % avant de passer à 50 %. La montée en puissance plus lente vous donne le temps de détecter tout problème flagrant ou une dégradation des valeurs des métriques en temps quasi réel.
Dans une expérience, nous pouvons nous concentrer sur deux fonctionnalités seulement, mais nous disposons d’un large ensemble de garde-fous qui suggèrent que nous ne devrions pas dégrader X, Y ou Z. Les données statistiques que vous recueillez peuvent également suggérer que vous avez un impact sur quelque chose que vous ne vouliez pas. D’où l’utilisation de déploiements progressifs qui permettent d’identifier les facteurs externes et de rollback facilement.
C’est comme si vous faisiez refroidir de l’eau : vous vous rendez compte que vous changez la température, mais ce n’est que lorsque vous atteignez 0ºC que la glace se forme. Vous réalisez soudain que lorsque vous atteignez un certain point, quelque chose de très important se produit. Ainsi, le fait de déployer à une vitesse sûre et de surveiller les résultats peut conduire à d’énormes améliorations.
Votre idée géniale ? Elle va très probablement échouer.
Rien ne vous permet de mieux vérifier la réalité que l’expérimentation à grande échelle. Tout le monde pense qu’il fait le meilleur travail du monde jusqu’à ce qu’il soit entre les mains de ses utilisateurs. C’est à ce moment-là que le vrai feedback entre en jeu.
Plus de deux tiers des idées ne parviennent pas à faire évoluer les paramètres qu’elles étaient censées améliorer – une statistique que Ronny partage avec nous depuis son passage chez Microsoft, où il a fondé l’équipe d’expérimentation, composée de plus de 100 data scientists, développeurs et responsables de programmes.
Cependant, ne vous laissez pas décourager. Dans le monde de l’expérimentation, l’échec est une bonne chose. Échouer rapidement, pivoter rapidement. Le fait de se rendre compte que la direction dans laquelle vous vous engagez n’est pas aussi prometteuse que vous le pensiez vous permet d’utiliser ces nouvelles découvertes pour enrichir vos prochaines actions.
Chez Airbnb, l’équipe d’expérimentation de Ronny a déployé de nombreux algorithmes d’apprentissage automatique pour améliorer la recherche. Sur 250 idées testées dans le cadre d’expériences contrôlées, seules 20 d’entre elles se sont avérées avoir un impact positif sur les paramètres clés – ce qui signifie que plus de 90 % des idées n’ont pas réussi à faire bouger l’aiguille. En revanche, qu’en est-il des 20 idées qui ont connu un certain succès ? Elles ont permis d’améliorer de 6 % la conversion des réservations, ce qui représente des centaines de millions de dollars.
Le starter pack pour l’expérimentation
Il est plus facile aujourd’hui de convaincre les dirigeants d’investir dans l’expérimentation, car il existe de nombreux cas d’utilisation réussis. Le conseil de Ronny est de commencer avec une équipe qui dispose d’un capital d’itération. Si vous êtes en mesure d’effectuer davantage d’expériences et qu’un certain pourcentage d’entre elles sont réussies ou échouées, cette capacité à essayer des idées est essentielle.
Choisissez un scénario dans lequel vous pouvez facilement intégrer le processus d’expérimentation dans le cycle de développement, puis passez à des scénarios plus complexes. La valeur de l’expérimentation est plus claire car les déploiements sont plus fréquents. Si vous travaillez dans une équipe qui effectue des déploiements tous les six mois, il n’y a pas beaucoup de marge de manœuvre car tout le monde a déjà investi ses efforts dans l’idée que la fonctionnalité ne peut pas échouer. Ce qui, comme Ronny l’a souligné plus tôt, a une faible probabilité de succès.
L’expérimentation convient-elle à toutes les entreprises ? La réponse courte est non. Une entreprise doit disposer de certains ingrédients pour pouvoir tirer profit de l’expérimentation. L’un de ces ingrédients est d’être dans un domaine où il est facile d’apporter des changements, comme les services pour les sites Web ou les logiciels. Le deuxième ingrédient est qu’il faut un nombre suffisant d’utilisateurs. Une fois que vous avez des dizaines de milliers d’utilisateurs, vous pouvez commencer à expérimenter et à le faire à grande échelle. Enfin, assurez-vous de disposer de résultats fiables pour prendre vos décisions.
Que pouvez-vous apprendre d’autre de notre conversation avec Ronny Kohavi ?
Comment l’expérimentation devient centrale dans la construction de votre produit
Pourquoi l’expérimentation est à la base des meilleures entreprises technologiques
Le rôle des dirigeants dans l’évangélisation d’une culture de l’expérimentation
Comment créer un environnement propice à une l’expérimentation et à des résultats fiables ?
A propos de Ronny Kohavi
Ronny Kohavi est un véritable expert en matière d’expérimentation, ayant travaillé sur des expériences contrôlées, le machine learning, la recherche, la personnalisation et l’IA pendant près de trois décennies. Ronny était auparavant vice-président technique chez Airbnb. Avant cela, Ronny a dirigé l’analyse et l’expérimentation au sein du groupe Cloud et IA de Microsoft et a été directeur de l’exploration des données et de la personnalisation chez Amazon. Ronny est également co-auteur de “Trustworthy Online Controlled Experiments : A Practical Guide to A/B Testing.,” qui est actuellement le livre sur le data mining le plus vendu sur Amazon.
A propos de 1,000 Experiments Club
Le 1,000 Experiments Club est un podcast produit par AB Tasty et animé par Marylin Montoya, VP Marketing chez AB Tasty. Rejoignez Marylin et l’équipe marketing alors qu’ils s’entretiennent avec les experts les plus compétents du monde de l’expérimentation pour découvrir leurs points de vue sur ce qu’il faut faire pour créer et exécuter des programmes d’expérimentation réussis.
Dans le secteur de l’AB testing, il existe deux méthodes majeures pour interpréter les résultats d’un test : fréquentiste ou bayésienne.
Ces termes font référence à deux méthodes de statistiques inférentielles. Des débats houleux visent à déterminer la « meilleure » solution mais chez AB Tasty, nous savons quelle méthode a fini par gagner nos faveurs.
Que vous soyez à la recherche d’une solution d’AB testing, que vous découvriez le domaine ou que vous cherchiez simplement à mieux interpréter les résultats d’une expérience, il est essentiel de comprendre la logique de chaque méthode. Cela vous aidera à prendre de meilleures décisions commerciales et/ou à choisir la meilleure plateforme d’expérimentation.
Dans cet article, nous allons évoquer :
[toc]
Définition des statistiques inférentielles
Les méthodes fréquentistes et bayésiennes appartiennent à la branche des statistiques inférentielles. Contrairement aux statistiques descriptives (qui comme leur nom l’indique, décrivent exclusivement des événements passés), les statistiques inférentielles visent à induire ou à anticiper des événements futurs. De la version A ou la version B, laquelle aura un meilleur impact sur un KPI X ?
À savoir : Pour entrer un peu plus dans les détails, techniquement, les statistiques inférentielles ne consistent pas à anticiper au sens temporel du terme, mais à extrapoler ce qu’il se passera en appliquant les résultats à un plus grand nombre de participants. Que se passe-t-il si nous proposons la version B gagnante à l’ensemble de l’audience de mon site web ? La notion d’événements « futurs » est bien présente dans le sens où nous devrons effectivement implémenter la version B demain, mais nous n’utilisons pas les statistiques pour « prédire l’avenir » au sens strict.
Prenons un exemple. Imaginons que vous soyez fan de sports olympiques et que vous vouliez en apprendre davantage sur une équipe de natation masculine. Plus précisément, combien mesurent les membres de l’équipe ? Grâce aux statistiques descriptives, vous pourriez déterminer quelques données intéressantes à propos de l’échantillon (autrement dit, l’équipe) :
La taille moyenne de l’échantillon
L’étalement de l’échantillon (variance)
Le nombre de personnes en dessous ou au-dessus de la moyenne
Etc.
Cela peut répondre à vos besoins immédiats mais le périmètre est relativement limité. Les statistiques inférentielles vous permettent d’induire des conclusions à des échantillons trop importants pour être étudiés par une approche descriptive. Si vous vouliez connaître la taille moyenne de tous les hommes sur la planète, il serait impossible d’aller collecter toutes ces données. En revanche, vous pouvez utiliser les statistiques inférentielles pour induire cette moyenne à partir de différents échantillons, plus limités.
On peut induire ce type d’information par l’analyse statistique de deux manières : à l’aide des méthodes fréquentiste et bayésienne.
Définition des statistiques fréquentistes
L’approche fréquentiste vous est peut-être plus familière car elle est plus fréquemment utilisée par les logiciels d’A/B testing (sans vouloir faire de mauvais jeu de mot…). Elle est également souvent enseignée dans les cours de statistiques en études suppérieures.
Cette approche vise à prendre une décision à propos d’une expérience unique.
Avec l’approche fréquentiste, vous partez de l’hypothèse selon laquelle il n’y a pas de différence entre la version A et la version B du test. Au terme de votre expérience, vous obtiendrez ce que l’on appelle la P-valeur (valeur de probabilité).
La « pValue » (valeur-p) désigne la probabilité d’obtenir des résultats au moins aussi extrêmes que les résultats observés, en partant du principe qu’il n’y a pas de (réelle) différence entre les expériences.
En pratique, la valeur-p est interprétée pour signifier la probabilité qu’il n’y a aucune différence entre vos deux versions. (C’est pour cela qu’elle est souvent “inversée” en utilisant la formule basique : p = 1-valeur-p, afin d’exprimer la probabilité qu’il existe une différence).
Plus la valeur-p est faible, plus élevées sont les chances qu’il existe effectivement une différence, et donc que votre hypothèse est fausse.
Avantages de l’approche fréquentiste :
Les modèles fréquentistes sont disponibles dans n’importe quelle bibliothèque de statistiques pour tous les langages de programmation.
Le calcul des tests fréquentistes est ultra-rapide.
Inconvénients de l’approche fréquentiste :
La valeur-p est uniquement estimée à l’issue d’un test et non pendant. Regarder régulièrement les données (data peeking) avant la fin d’un test génère des résultats trompeurs car il s’agit alors de plusieurs expériences (une nouvelle à chaque fois que vous examinez les données) quand le test est conçu pour une seule expérience.
Vous ne pouvez pas connaître le réel intervalle de gain d’une variation gagnante.
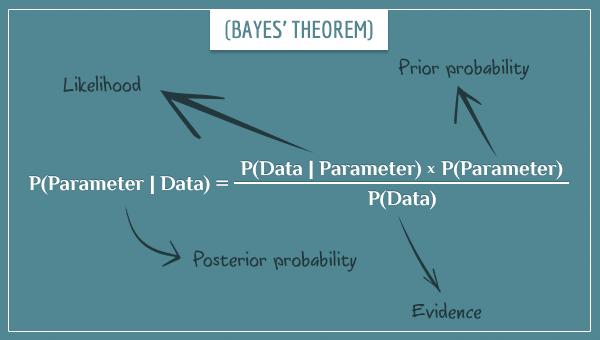
Définition des statistiques bayésiennes
L’approche bayésienne explore les choses sous un angle un peu différent.
Son origine remonte à un charmant mathématicien britannique du nom de Thomas Bayes et à son éponyme théorème de Bayes.
L’approche bayésienne permet d’inclure des informations antérieures (« a priori ») à votre analyse actuelle. Cette méthode fait intervenir trois concepts qui se recoupent :
Un a priori, à savoir une information obtenue d’une expérience précédente. Au début de l’expérience, nous utilisons un a priori « non-informatif » (comprendre « vide »).
Des preuves, c’est à dire les données de l’expérience actuelle.
Un posteriori, soit l’information actualisée obtenue à partir de l’a priori et des preuves. C’est ce que l’on obtient par l’analyse bayésienne.
Par nature, ce test peut être utilisé pour une expérience en cours. Lors du data peeking, les données observées peuvent servir d’a priori, les données à venir seront les preuves, et ainsi de suite. Cela signifie que le « data peeking » s’intègre naturellement à la conception du test. Ainsi, à chaque data peeking, le posteriori calculé par l’analyse bayésienne est valide.
L’approche bayésienne permet aux professionnels du CRO d’estimer le gain d’une variation gagnante : un élément fondamental de l’A/B testing dans un contexte business. Nous reviendrons plus tard sur ce point.
Avantages de l’approche bayésienne :
Elle permet d’observer les données pendant un test. Ainsi, vous pouvez stopper le traffic si une variation échoue ou bien passer plus rapidement à une variation gagnante évidente.
Elle vous permet de connaître le réel intervalle de gain d’un test gagnant.
Par nature, elle élimine souvent l’implémentation de faux positifs.
Inconvénients de l’approche bayésienne :
Elle nécessite une boucle d’échantillonnage qui utilise une charge CPU non-négligeable. Ce n’est pas un problème pour l’utilisateur mais cela peut potentiellement poser problème à plus grande échelle.
Approche bayésienne vs. fréquentiste
Alors, quelle est la « meilleure » méthode ?
Commençons par préciser que ces méthodes statistiques sont toutes les deux parfaitement valables. Mais chez AB Tasty, nous avons une nette préférence pour l’approche bayésienne. Pourquoi ?
La mesure du gain
L’une des raisons principales est que les statistiques bayésiennes vous permettent d’évaluer l’ampleur du gain réel d’une variation gagnante, plutôt que de savoir uniquement qu’il s’agit de la gagnante.
Dans un cadre business, il s’agit d’une distinction cruciale. Lorsque vous effectuez votre test A/B, ce que vous êtes réellement en train de décider, c’est si vous devez passer de la variation A à la variation B. Il ne s’agit pas de choisir A ou B en partant de zéro. Il faut donc prendre en compte :
Le coût de mise en oeuvre du passage à la variation B (temps, ressources, budget)
Les coûts additionnels liés à la variation B (coûts de la solution, licences…)
Prenons un exemple : imaginons que vous commercialisez un logiciel B2B et que vous exécutez un test A/B sur votre page tarifs. La variation B comprenait un chatbot, absent dans la variation A. La variation B a surperformé par rapport à la A mais pour l’implémenter, il faudra deux semaines à un développeur pour intégrer le chatbot à votre workflow de lead nurturing. En outre, il faudra dégager X euros de budget marketing pour payer la licence mensuelle du chatbot.
Il faut être sûr de votre calcul et qu’il est plus rentable d’opter pour la version B en comparant ces coûts avec le gain estimé par le test. C’est exactement ce que permet l’approche bayésienne.
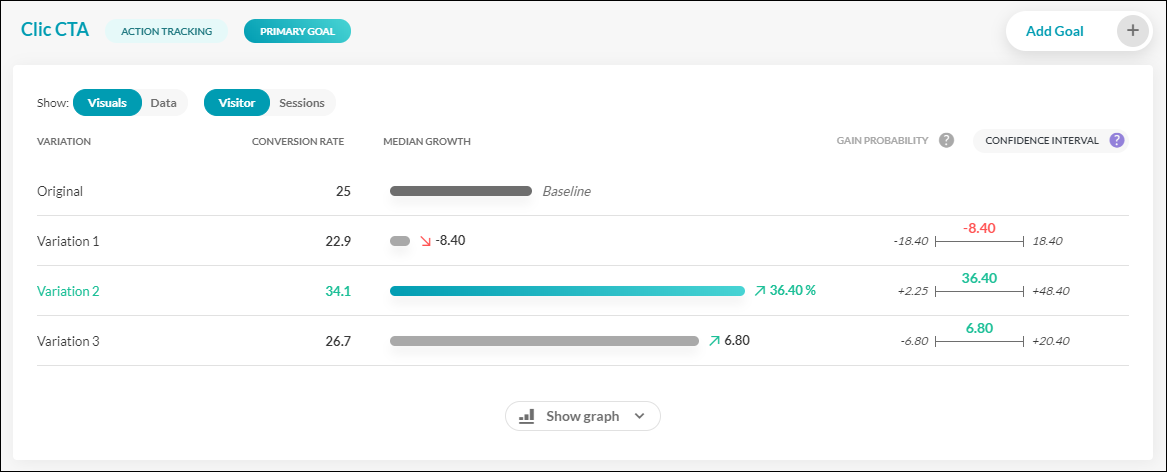
Prenons un exemple en observant l’interface de reporting AB Tasty.
Dans ce test fictif, nous mesurerons trois variations contre une version d’origine en prenant les « Clics CTA » comme KPI.
On peut constater que la grande gagnante semble être la variation 2, avec un taux de conversion de 34,5 %, comparé à 25 % pour la version d’origine. Mais en regardant à droite, nous pouvons aussi voir l’intervalle de confiance de ce gain. Autrement dit, nous tenons compte du meilleur et du pire scénario.
Le gain médian de la variation 2 s’élève à 36,4 %. Ici le gain le plus faible possible est + 2,25 % et le plus élevé, 48,40 %. Il s’agit des bornes de gain les plus faibles et les plus élevés que vous pouvez obtenir dans 95 % des cas. Si l’on décompose les choses davantage :
Il y a 50 % de chances que le pourcentage de gain percentage soit supérieur à 36,4 % (la médiane)
Il y a 50 % de chances qu’il soit inférieur à 36,4 %.
Dans 95 % des cas, le gain sera dans la fourchette entre + 2,25 % et + 48,40 %.
Il reste 2,5 % de chances que le gain soit inférieur à 2,25 % (le fameux cas du faux positif) et 2,5% de chances qu’il soit supérieur à 48,40 %.
Ce niveau de granularité peut vous aider à choisir de déployer ou non la variation gagnante d’un test sur votre site internet. Les extrémités les plus faibles et les plus élevées de vos marqueurs de gain sont positives ? Fantastique ! L’intervalle de confiance est étroit, donc vous êtes convaincu d’un gain élevé ? Implémenter la version gagnante est alors probablement la bonne décision. Votre intervalle est large mais les coûts d’implémentation sont bas ? Là encore, il n’y a pas de mal à se lancer. En revanche, si votre intervalle est large et que les coûts d’implémentation sont conséquents, il vaut sans doute mieux attendre d’avoir davantage de données pour réduire cet intervalle. Chez AB Tasty, nous recommandons généralement :
D’attendre avant d’avoir enregistré au moins 5 000 visiteurs uniques par variation ;
De faire durer le test au moins 14 jours (deux cycles commerciaux) ;
D’attendre d’avoir atteint 300 conversions sur votre objectif principal.
Data peeking
Les statistiques bayésiennes offrent un autre avantage : grâce à elles, vous pouvez jeter un coup d’œil aux résultats de vos données pendant un test (sans en abuser tout de même !).
Imaginons que vous travaillez pour une grande plateforme d’e-commerce et que vous effectuez un test A/B concernant une nouvelle offre promotionnelle. Si vous remarquez que la variation B affiche des résultats pitoyables (vous faisant perdre beaucoup d’argent au passage), vous pouvez stopper le test immédiatement !
A l’inverse, si votre test surperforme, vous pouvez transférer tout le trafic de votre site web vers la version gagnante plus rapidement que si vous employiez la méthode fréquentiste.
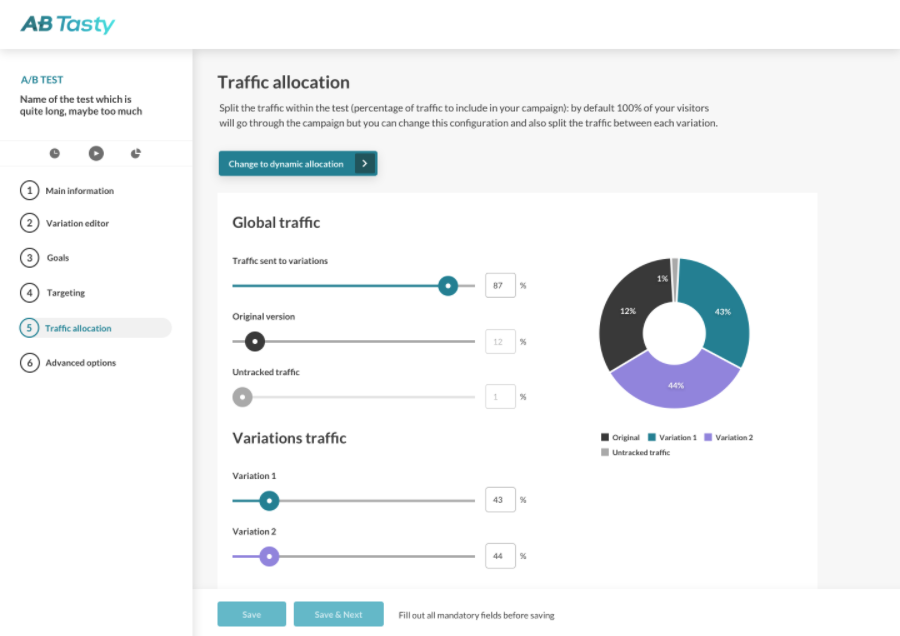
Si nous nous arrêtons rapidement sur le sujet de l’allocation dynamique de trafic, nous verrons qu’elle est particulièrement utile dans un cadre commercial ou dans des contextes instables ou limités en termes de temps.
L’option d’allocation dynamique de trafic dans l’interface AB Tasty
L’allocation dynamique de trafic (automatisée) permet essentiellement de trouver l’équilibre entre l’exploration et l’exploitation des données. Les données du test font l’objet d’une « exploration » suffisamment approfondie pour être certain de la conclusion et elles sont « exploitées » suffisamment tôt pour de ne pas perdre inutilement des conversions (ou tout autre KPI). Il faut souligner que ce processus ne se fait pas manuellement : ce n’est pas une personne en chair et en os qui interprète ces résultats et prend la décision. Au lieu de cela, un algorithme va faire ce choix pour vous automatiquement.
Dans la pratique, les clients AB Tasty cochent la case correspondante et choisissent leur KPI principal. L’algorithme de la plateforme déterminera alors s’il faut rediriger la majorité de votre trafic vers une variation gagnante et du moment opportun pour le faire.
Ce type d’approche est particulièrement utile dans les situations suivantes :
Pour optimiser les micro-conversions dans un délai court
Lorsque la durée du test est courte (par exemple, lors d’une promotion pendant les fêtes)
Lorsque votre page cible génère peu de trafic
Lorsque vous testez plus de six variations
S’il faut bien réfléchir au moment opportun pour utiliser cette option, il est particulièrement utile de l’avoir sous le coude.
Les faux positifs
Tout comme les méthodes fréquentistes, les statistiques bayésiennes comportent un risque de ce que l’on appelle le faux positif.
Comme vous pouvez le deviner, un faux positif se produit lorsque le résultat d’un test indique qu’une variation affiche une amélioration, alors que ce n’est pas le cas. En matière de faux positifs, il arrive souvent que la version B donne les mêmes résultats que la version A (et non pas qu’elle soit moins performante que la version A).
Loin d’être inoffensifs, les faux positifs ne sont certainement pas une raison d’abandonner l’A/B testing. Vous pouvez plutôt ajuster votre intervalle de confiance pour l’adapter au risque lié à un potentiel faux positif.
La probabilité de gain par les statistiques bayésiennes
Vous avez probablement déjà entendu parler de la règle de probabilité de gain de 95 %.
Autrement dit, on considère qu’un test est statistiquement significatif lorsque l’on atteint un seuil de certitude de 95 % : vous êtes sûr à 95 % que votre version B performe comme indiqué, mais il existe toujours 5 % de risques que ce ne soit pas le cas.
Pour de nombreuses campagnes marketing, ce seuil de 95 % est probablement suffisant. Mais si vous menez une campagne particulièrement importante dont les enjeux sont considérables, vous pouvez ajuster votre seuil de probabilité de gain pour qu’il soit encore plus précis : 97 %, 98 % ou même 99 %, excluant ainsi pratiquement le moindre risque de faux positif.
Si l’on peut penser qu’il s’agit d’une valeur sûre (et c’est la bonne stratégie pour les campagnes de premier plan), il ne faut pas l’appliquer à tout va.
Voilà pourquoi :
Pour atteindre ce seuil plus élevé, vous devez attendre les résultats plus longtemps, ce qui vous laisse moins de temps pour récolter les bénéfices d’une issue positive.
De manière implicite, vous n’obtiendrez un gagnant qu’avec un gain plus important (ce qui est plus rare), et vous abandonnerez les améliorations mineures qui peuvent quand même changer la donne.
Si vous avez un faible volume de trafic sur votre page web, vous voudrez peut-être envisager une approche différente.
Les tests bayésiens limitent les faux positifs
Il faut également garder en tête que puisque l’approche bayésienne fournit un intervalle de gain et que les faux positifs n’apparaissent virtuellement que légèrement meilleurs qu’en réalité, vous n’avez alors que très peu de chances d’implémenter un faux positif.
Prenons un scénario courant pour illustrer ce propos. Imaginons que vous exécutiez un test A/B pour vérifier si le nouveau design d’une bannière promotionnelle augmente le taux de clics sur le CTA. Votre résultat indique que la version B est plus performante avec une probabilité de gain à 95 % mais le gain est infime (amélioration médiane d’1 %). Même s’il s’agit d’un faux positif, il y a peu de chances que vous déployez la version B de la bannière sur l’ensemble de votre site car les ressources nécessaires à son implémentation n’en vaudraient pas la peine.
Mais, comme l’approche fréquentiste ne fournit pas cet intervalle de gain, vous seriez plus tenté de mettre en place le faux positif. Certes, ce ne serait pas la fin du monde : la version B offre certainement la même performance que la version A. Cependant, vous gaspilleriez du temps et de l’énergie sur une modification qui ne vous apporterait aucune valeur ajoutée.
Ce qu’il faut retenir ? Si vous jouez la carte de la sécurité et que vous attendez un seuil de confiance trop élevé, vous passerez à côté de plusieurs petits gains, ce qui serait également une erreur.
En conclusion
Alors, quelle approche est la meilleure : fréquentiste ou bayésienne ?
Comme nous l’avons déjà évoqué, les deux approches sont des méthodes statistiques parfaitement valables.
Mais chez AB Tasty, nous avons choisi l’approche bayésienne car nous estimons qu’elle aide nos clients à prendre de meilleures décisions commerciales. Elle permet également une plus grande flexibilité et une maximisation des bénéfices (allocation dynamique de trafic). En ce qui concerne les faux positifs, ils peuvent survenir que vous optiez pour l’approche fréquentiste ou bayésienne… mais il y a de moins de risque que vous vous y laissiez prendre avec cette dernière. Au bout du compte, si vous cherchez une plateforme d’A/B testing, l’important est d’en trouver une qui vous fournira des résultats fiables et facilement interprétables.
Nous enrichissons notre plateforme d’optimisation des conversions d’une solution d’A/B testing server-side. Une nouvelle qui réjouira tous les férus d’expérimentation qui peuvent désormais tester n’importe quelle hypothèse, sur n’importe quel device.
Qu’il s’agisse de tester des modifications visuelles envisagées par votre équipe marketing ou des modifications avancées liées à votre back-office et indispensables à la prise de décision de votre équipe produit, nous vous proposons une solution adaptée.
Quelles différences entre A/B testing côté client et côté serveur ?
Les outils d’A/B testing “client-side” vous aident à créer les variations de vos pages en manipulant, dans le navigateur, le contenu qui est envoyé par votre serveur à l’internaute. La magie opère donc au niveau du navigateur (appelé “client” en informatique) grâce au langage JavaScript. A aucun moment, votre serveur n’est sollicité ou n’intervient dans ce processus : il renvoie toujours le même contenu à l’internaute.
Les outils d’A/B testing “server-side”, à l’inverse, déchargent votre navigateur de tout traitement. Dans ce cas, c’est votre serveur qui se charge de renvoyer aléatoirement à l’internaute une version modifiée.
4 raisons pour A/B tester côté serveur
Mener un test A/B côté serveur présente de nombreux avantages.
1. Dédié aux besoins de votre équipe produit
A/B tester côté client se résume parfois à des modifications de surface. Celles-ci concernent l’aspect visuel, comme l’organisation de la page, l’ajout / suppression de blocs de contenus ou encore la modification de texte. Si vous souhaitez tester des modifications plus profondes qui touchent à votre back office, comme la réorganisation de votre tunnel d’achat, les résultats de votre algorithme de recherche ou de tri produits, les choses se compliquent.
[clickToTweet tweet= »En A/B testant côté serveur, vous étendez le champ des possibles, en agissant sur tous les aspects de votre site, qu’il s’agisse du front ou du back-end. #abtesting #CRO » quote= »En A/B testant côté serveur, vous étendez le champ des possibles, en agissant sur tous les aspects de votre site, qu’il s’agisse du front ou du back-end. »]
Tout cela est possible car vous gardez la maîtrise du contenu retourné par votre serveur au navigateur. Votre équipe produit va se réjouir car elle fait un énorme bond en avant en termes de flexibilité. Elle peut désormais tester tous types de fonctionnalités et se doter d’une vraie approche data-driven pour améliorer sa prise de décision. La contrepartie de cette flexibilité est que le testing côté serveur nécessitera l’implication de votre équipe IT pour implémenter les modifications. Nous y reviendrons par la suite.
Votre équipe produit peut désormais tester tous types de fonctionnalités.
2. De meilleures performances
La dégradation des performances – temps de chargement ou effet flicker – se retrouve souvent en tête des reproches faits aux solutions d’A/B testing côté client.
Dans les cas les plus extrêmes, certains sites limitent l’ajout de tag JavaScript à leur seul pied de page pour éviter un éventuel impact sur leur performance technique. Cette politique exclut automatiquement le recours aux solutions d’A/B testing côté client, car un tag en “footer “ est souvent synonyme d’effet flicker.
En utilisant une solution d’A/B testing server-side, vous n’avez plus de tag JavaScript à insérer sur vos pages et restez maître de tous les goulots d’étranglement potentiels sur les performances de votre site. Vous êtes aussi garant de la politique de sécurité de votre entreprise et du respect des procédures techniques internes.
3. Adapté à vos règles métiers
Dans certains cas de figure, votre test A/B peut se limiter à des modifications de design mais vous êtes confrontés à des contraintes métier qui rendent difficile l’interprétation d’un test A/B classique.
Par exemple, un e-commerçant peut légitimement vouloir prendre en compte dans ses résultats les commandes annulées ou exclure les commandes extrêmes qui faussent ses analyses (notion de “outliers”).
Avec un test A/B côté client, la conversion est enregistrée dès qu’elle se produit côté navigateur, lorsque la page de confirmation d’achat est chargée ou qu’un événement de type transaction est déclenché. Avec un test A/B côté serveur, vous avez la maîtrise totale de ce qui est pris en compte et pouvez, par exemple, exclure en temps réel certaines conversions ou en enregistrer d’autres à posteriori, par lot.
4. De nouvelles opportunités omni-canal
Qui dit solution d’A/B testing server-side dit solution omni-canal et multi-device.
Avec une solution côté client – qui repose sur le langage JavaScript et les cookies – vous limitez votre terrain de jeu aux terminaux qui disposent d’un navigateur web, qu’il s’agisse d’une version desktop, tablette ou mobile. Impossible donc d’A/B tester sur des applications mobiles natives (iOS ou Android) ou sur des objets connectés, existants et à venir.
A l’inverse, avec une solution server-side, dès lors que vous êtes en mesure de réconcilier l’identité d’un consommateur quel que soit le device utilisé, vous pouvez délivrer des tests A/B ou des campagnes de personnalisation omni-canal dans une logique de parcours client unifié. Votre terrain de jeu vient soudain de s’agrandir 😉 et les opportunités sont nombreuses. Pensez objets connectés, applications TV, chatbot, beacon, digital store, …
L’A/B testing server-side, quels cas d’usage ?
Maintenant, vous vous demandez peut-être ce que vous pouvez concrètement tester avec une solution côté serveur que vous ne pouviez pas tester avec un outil côté client ?
Au programme : test de formulaire d’inscription, test de tunnel de commande, test d’algorithme de recherche, test de fonctionnalité…
Comment mettre en place un test A/B côté serveur ?
Pour mettre en place un test A/B côté serveur vous faites appel à notre API. Nous décrivons ici les grandes lignes de son mode de fonctionnement. Pour plus de détails, contactez notre support qui vous fournira une documentation technique complète.
Lorsqu’un internaute arrive sur votre site, vous interrogez notre API en lui passant en paramètre l’ID de visiteur, qui identifie ce dernier de manière unique. AB Tasty vous fournit cet ID que vous stockez (ex: cookie, session storage…). Si un visiteur possède déjà un identifiant lors d’une visite ultérieure, vous utilisez celui-ci.
Sur les pages où un test doit se déclencher, vous interrogez ensuite notre API en lui passant en paramètres l’ID du visiteur et l’ID du test en question. Cet ID de test est accessible depuis notre interface, lorsque vous créez le test. En réponse à votre requête, AB Tasty renvoie l’ID de variation à afficher. Votre serveur doit alors construire sa réponse en se basant sur cette information.
Vous devez également informer nos serveurs de collecte dès qu’une conversion a lieu, en passant un appel API avec l’ID de visiteur et des données relatives à cette conversion comme son type (action tracking, transaction, custom event…) et/ou sa valeur.
Nous mettons à votre disposition tout notre savoir faire pour l’analyse des résultats et l’optimisation de vos tests grâce à nos algorithmes d’allocation dynamique de trafic, qui répondent à la problématique dite du multi-armed bandit.
Vous l’aurez compris, mettre en place un test A/B côté serveur requiert l’intervention de votre équipe technique et implique un changement de mode organisationnel.
[clickToTweet tweet= »Alors que l’A/B testing côté client est géré et centralisé par votre équipe marketing, l’A/B testing côté serveur est décentralisé au niveau de chacune de vos équipes produits ou projets. » quote= »Alors que l’A/B testing côté client est géré et centralisé par votre équipe marketing, l’A/B testing côté serveur est décentralisé au niveau de chacune de vos équipes produits ou projets. »]
Faut-il se passer des tests A/B côté client ?
La réponse est non. L’A/B testing côté client et côté serveur ne sont pas antinomiques mais complémentaires. Les entreprises les plus performantes utilisent les deux conjointement selon leurs besoins et les équipes impliquées.
L’A/B testing côté client est facile d’accès, idéal pour les équipes marketing qui veulent agir en toute autonomie, sans avoir à solliciter leur DSI. Le maître mot ici est AGILITE. Vous pouvez tester rapidement beaucoup d’hypothèses.
L’A/B testing côté serveur s’adresse davantage aux équipes produits dont les besoins impliquent davantage de règles métier et sont étroitement liés aux fonctionnalités produits. Le maître mot ici est FLEXIBILITE.
En vous proposant le meilleur des deux mondes, AB Tasty confirme son rôle de partenaire incontournable pour tous vos besoins de testing et de prises de décision data-driven.
Qu’est-ce que la méthode d’A/B testing ? Il s’agit de comparer deux versions d’une même page web ou d’une application entre elles dans le but de déterminer la plus performante. Le principe de fonctionnement repose sur l’analyse statistique qui permet alors de définir quelle version est plus efficace selon l’objectif de conversion fixé. À quoi sert précisément l’A/B testing ? Dans quels cas particuliers l’appliquer ? Et pour quels résultats ? Tour d’horizon.
À qui s’adresse plus particulièrement l’A/B testing ? La méthode est principalement utilisée au sein des directions marketing des entreprises de toutes tailles, et de tous secteurs, en tant que technique d’optimisation du taux de conversion (Conversion Rate Optimization – CRO). Toutefois, la méthodologie n’est pas sans poser problème : en effet, les limites des analyses statistiques utilisées se retranscrivent sous forme de limites marketing.
Pour mieux comprendre, il est important de plonger dans les subtilités de l’A/B testing.
Le graal des spécialistes marketing : les décisions business basées sur l’A/B testing
Pour les directeurs Marketing, la prise de décisions a pour objectif d’accroître le chiffre d’affaires. Résultat, une majorité d’entre eux se creusent la tête pour répondre à ces questions :
Est-il nécessaire de diminuer le prix pour vendre plus ?
Ou, au contraire, les augmenter pour améliorer le panier moyen, au risque d’obtenir un taux de conversion inférieur ?
Les produits doivent-ils être classés par ordre de prix croissants ? Ou décroissants ?
Devez-vous élargir votre gamme de produits ou la restreindre ? Ou les deux ? Ou ne rien changer ?
Les promos de type « 3 produits achetés pour le prix de 2 » sont-elles un bon moyen d’augmenter votre panier moyen ?
Est-il préférable de proposer la livraison gratuite sans condition de dépenses ou à partir d’une certaine valeur de panier ?
Et si vous pouviez tester vos hypothèses business pour prendre la bonne décision ?
Malheureusement, les analyses statistiques utilisées aujourd’hui sont très limitées en termes d’interprétation des résultats.
Le principe de base de l’A/B testing
Pour rappel, le test consiste à exposer deux variantes de la même page (nommées A et B) à deux populations homogènes en séparant de façon aléatoire les visiteurs du site. Pour chaque variation, les donnés suivantes sont collectées :
Le nombre de visiteurs
Le nombre d’achats
La valeur du panier d’achat
Sur le papier, il devrait être relativement simple de définir quelle variation a généré le plus de revenus et, par conséquent, de déterminer quelle version est la plus performante. Néanmoins, comme n’importe quelle expérience sur le comportement humain, les données sont soumises au hasard. Résultat : si la variation B génère un panier moyen plus important que la variation A, cela ne signifie pas pour autant que B sera toujours meilleur que A.
La raison ? Difficile d’affirmer que la différence observée pendant un test sera répétée dans le futur. Voilà pourquoi les outils d’A/B testing utilisent des analyses statistiques pour qualifier les différences observées et identifier la variation la plus pertinente. Objectif : aider à séparer les données significatives des fluctuations aléatoires et imprévisibles qui ne sont pas corrélées aux différences entre les variations.
« Le problème, c’est le choix »
En e-commerce, la variation B peut être considérée comme la meilleure si elle génère :
Un gain de conversions : la variation amène à convertir plus d’achats
Un gain au niveau du panier d’achat moyen : le panier moyen de la variation B est supérieur à celui de la variation A
Un gain « mixte » : la variation B génère à la fois plus de conversions et un panier moyen plus élevé
Le gain de conversions
C’est la donnée la plus simple à analyser dans la méthode d’A/B testing. L’outil statistique utilisé : le test Bayésien. La caractéristique fonctionnelle la plus importante de ce test repose sur l’intervalle de confiance du gain de conversion mesuré.
Par exemple : on peut dire que la variation B produit un gain de 5 à 10 % – ce qui signifie que la variation B générerait entre 5 et 10 % d’achats supplémentaires par rapport à la variation A. Dans ce cas, il est facile de déterminer que la variation B est plus performante. Vous pouvez alors la valider en tant que « meilleure variation » et la proposer à l’ensemble de votre audience…
… Mais est-ce vraiment suffisant pour définir de façon définitive quelle est la variation la plus pertinente ? C’est ce que nous allons voir dans la suite de cet article.
Le gain de panier moyen
Cet indicateur est bien plus complexe à analyser. Les outils d’A/B testing utilisent le test Mann-Whitney U, également appelé Wilcoxon. Contrairement au test Bayésien, cette analyse ne fournit qu’une simple probabilité de gain sans préciser l’importance du gain. Par exemple, vous mesurez une différence de +5€ dans le panier moyen relatif à la variation B, ainsi qu’une probabilité de gain (donné par le test Mann-Whitney) à 98 %. Vous pourriez croire que ce gain de 5€ est sûr à 98 %, mais en réalité, il se peut que vous n’obteniez qu’un gain de +0,1€. L’analyse statistique a toujours raison : c’est un gain ! C’est simplement que le test Mann-Whitney ne prédit que l’existence du gain, pas de quel montant il sera !
Mais le pire est qu’une variation « gagnante » en termes de taille de panier moyen selon le test de Mann-Whitney pourrait en réalité générer moins de revenus, en raison de la présence de valeurs extrêmes qui faussent l’analyse. Comment l’éviter ? Une option pourrait être de supprimer ces valeurs avant d’analyser les résultats. Toutefois, il est à noter que cette solution n’en reste pas moins inévitablement biaisée : la variation la plus performante ne dépend que de la ligne « valeurs extrêmes » que vous aurez artificiellement définies.
Le gain mixte
Le moyen le plus efficace d’identifier la meilleure variation est de déterminer un gain significatif à la fois en termes de conversion et de panier moyen. En réalité, c’est même le seul cas où une décision peut être prise sans le moindre doute !
Vous observez un certain gain de conversion mais une perte de panier moyen → impossible de prendre une décision avisée car vous ne connaissez pas le montant de la perte, et ignorez si le gain obtenu va compenser cette perte.
L’analyse démontre une perte de conversions et un gain dans le panier d’achat moyen → même constat.
Perte ou gain indéfini dans le panier moyen → si vous ne connaissez pas l’évolution du panier moyen, impossible d’être sûr de la pertinence de la variation.
Ce dernier scénario représente la situation le plus courante. En effet, les statistiques liées au panier moyen nécessitent généralement plus d’informations que le taux de conversion afin de proposer une analyse pertinente.
Comme vous pouvez le constater, la majorité de tests A/B concluent à la certitude d’un gain de conversion. Mais sans information sur l’évolution du panier moyen, ces conclusions doivent être remises en question. On pourrait alors argumenter que c’est la raison pour laquelle on parle « d’optimisation du taux de conversion » plutôt que « d’optimisation business ».
Faut-il alors en conclure que l’A/B testing ne sert à rien ? Heureusement non ! Aujourd’hui, la plupart des tests A/B se concentrent sur l’expérience utilisateur, l’interface utilisateur et le design : couleurs, formulation, visuels, mise en pages d’un produit… En marketing, on parle de « réduire la friction du parcours d’achat », en d’autres termes, limiter le nombre de visiteurs insatisfaits et qui quittent le site sans avoir effectué le moindre achat.
Mais pour pouvoir aller plus loin que les tests basés sur l’ergonomie et s’attaquer aux vraies questions de marketing, nous avons besoin d’inventer le prochain test Mann-Whitney qui sera capable d’estimer la taille du gain ou de la perte générée par l’expérimentation. Voilà qui donnera définitivement un second souffle à l’A/B testing.
Revoir l’intervention de notre Chief Data Scientist, Hubert Wassner, et d’Aurélie Bastian, Manager Web Analytics et Conversion de Sutter Mills, à l’occasion de Digital Innovation 2019.
Quels tests lancer ? Dans quel ordre ? Comment éviter les conflits entre plusieurs tests ? Quels sont les risques et comment les minimiser ? Avant de vous lancer, voilà les questions qu’il faut se poser ! Suivez nos conseils pour établir votre roadmap de test.
Avant de commencer votre testing, il faut baliser votre chemin. Pour être au clair sur vos objectifs, définir vos priorités et anticiper les risques mais aussi fixer un calendrier, la feuille de route est un outil indispensable. Elle vous permettra de suivre l’avancement de votre projet et de tenir l’ensemble de vos contributeurs informés et impliqués (nous vous proposons un modèle en format Excel, prêt à l’utilisation).
Votre feuille de route doit (notamment) comprendre les 8 éléments suivants :
1 – Nom des tests
Veillez à donner des noms précis et explicites à vos tests (de préférence identiques à ceux utilisés dans l’outil AB Tasty). On préfèrera par exemple un titre court et explicite « [HP]wordingCTA » à une phrase entière : « Test sur le wording du CTA de la Page d’Accueil ».
2 – Description des tests
Afin que l’ensemble des contributeurs soient associés à la démarche de testing et puissent suivre l’évolution du processus, une description courte mais explicite est à privilégier. Par exemple, la formulation « Modification du wording du CTA ‘Je m’inscris’ par ‘Je m’abonne’ » permet à n’importe qui de comprendre la teneur et les enjeux du test.
3 – Niveau de priorité des tests
Il est indispensable de hiérarchiser vos tests par degré d’importance afin de déterminer leur ordre de développement et de lancement. Pour cela, à vous d’apprécier :
les bénéfices espérés pour le test
la difficulté technique du test
Après les premiers résultats des tests, vous pourrez ajuster votre hiérarchisation pour plus d’efficacité et optimiser votre testing.
4 – Périmètre testé
Autre information essentielle à consigner dans votre feuille de route : le périmètre testé. Cela vous permettra d’éviter les conflits (plusieurs tests lancés au même moment sur la même page) ou les possibles effets de bords. Pour cela, nous vous conseillons de découper l’architecture de votre site en grands ensembles et de leur associer une couleur dans votre feuille de route. Par exemple : bleu pour la page d’accueil, orange pour les pages listes, vert pour les pages produits, jaune pour le tunnel, etc.
5 – KPI primaires et secondaires
Pour chaque test, il convient de définir a priori un indicateur clé de performance (KPI) primaire (ou objectif de macro conversion). Cet indicateur, qui a motivé la création du test, vous permettra d’en évaluer les bénéfices. Il peut s’agir du nombre de clics sur le bouton d’ajout au panier, du nombre d’inscriptions à la newsletter, du chiffre d’affaire généré…
Il faut également définir des KPIs secondaires (ou objectifs de micro conversion), des indicateurs apportant des compléments d’analyses et permettant d’affiner l’information apportée par les résultats du KPI primaire récoltés durant le test. On peut citer à titre d’exemple le temps passé sur le site, le nombre de pages vues, le taux de rebonds…
6 – Ressources nécessaires
L’implémentation de certains tests peut nécessiter…
des développements techniques
des développements ergonomiques
un lancement à une date spécifique
qu’il est important de préciser dans votre feuille de route.
7 – Date de lancement et de fin estimée du test
Cette information permet de donner de la lisibilité aux équipes quant aux retours qu’ils pourront faire à leur hiérarchie ainsi qu’aux éventuels prochains lancements de tests. Parallèlement cela permet également de mettre en place un rétroplanning précis de l’activité testing.
8 – Possibles effets de bord / Personnes à contacter / Alertes
Il s’agit ici d’aménager un espace d’annotation et de commentaires, qui vous sera utile en cas de problèmes. Notez les contacts et informations utiles, les personnes à alerter, des points d’attention à ne pas oublier… cela vous permettra de gagner beaucoup de temps (et de vous éviter quelques frayeurs !)
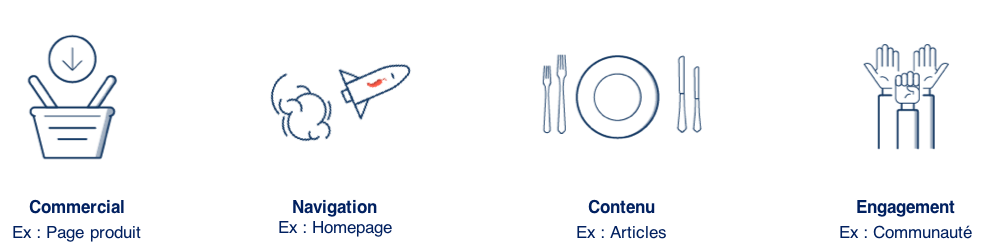
Nous avons vu comment trouver des hypothèses de tests grâce à vos données, puis grâce à l’UX et l’UI. Voyons maintenant comment trouver des idées par typologie de pages.
Au quotidien, nous réfléchissons toujours à des hypothèses de tests en travaillant méthodiquement par type de page. Chaque page a son propre objectif, ses enjeux et ses codes. En tant qu’expert du CRO, nous nous appuyons sur les meilleures techniques pour trouver des hypothèses de tests toujours plus pertinentes. Voyons comment procéder avec la méthode par typologie de pages !
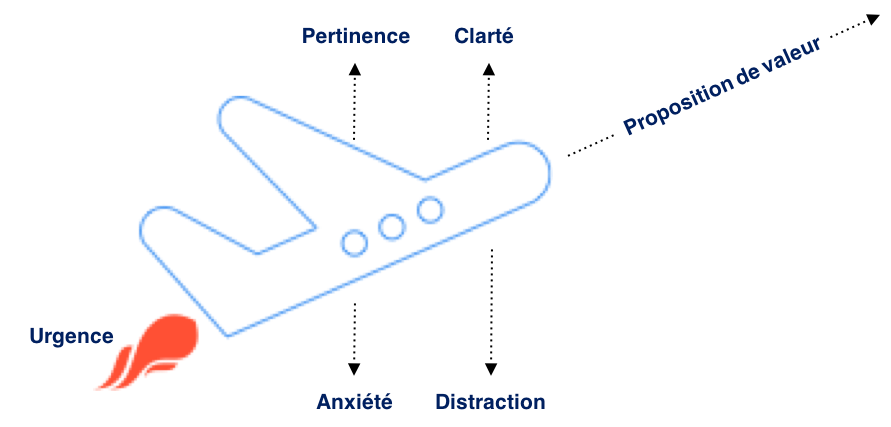
Qu’est-ce que la proposition de valeur ?
Votre proposition de valeur est une formule coût / avantages évaluée inconsciemment et automatiquement dans l’esprit de votre client potentiel lorsqu’ils rencontrent votre interface digitale (site web, landing page, etc). C’est un élément crucial. Considérez-la comme une équation entre les avantages et le coût : si les avantages perçus l’emportent sur le coût perçu, alors vos prospects seront prêts à convertir !
En moins de 5 secondes, l’utilisateur doit être capable de comprendre votre proposition de valeur. Elle doit être claire, compréhensible et pertinente sur vos pages.
Le Modèle LIFT (Landing Page Influence Function for Tests) est un modèle d’optimisation des conversions basé sur 6 facteurs de conversion qui vous permettent d’évaluer les pages de votre interface du point de vue du visiteur.
“Le Modèle LIFT consiste à vous mettre dans la peau du client potentiel et à proposer des idées qui répondront à leurs besoins.”
– Chris Goward, Founder & CEO, WiderFunnel
Ce schéma représente bien cette méthode. Pour atteindre le niveau supérieur – les conversions – c’est le travail d’un ensemble de facteurs et une proposition de valeur forte. Chris Goward décrit la proposition de valeur comme « l’ensemble des avantages et des coûts perçus, dans l’esprit du client potentiel, au moment de mener une action ». Lorsque la proposition de valeur dépasse les coûts, les utilisateurs sont prêts à convertir.
Mais avoir une bonne proposition de valeur ne suffit pas. Elle doit être pertinente et clairement énoncée, sans distractions ou éléments anxiogènes.
Votre travail consiste donc à améliorer les aspects positifs tout en réduisant les points négatifs.
Léa Benquet, CSM chez AB Tasty
Maintenant que nous avons vu ce qu’est la proposition de valeur d’une page, voyons comment activer méthodiquement les autres leviers pour élaborer des hypothèses de tests pertinentes.
En pratique
Pertinence
Etat Pur a souhaité mettre en avant la pertinence de sa proposition de valeur en proposant du contenu à forte valeur ajoutée. Sur la version originale, nous pouvons distinguer deux blocs : le premier présente la formule personnalisée avec une offre de 20% sur les premiers soins, le second présente l’innovation et les bénéfices d’avoir des produits personnalisés en fonction de sa peau.
L’équipe digital d’Etat Pur a testé une variation en inversant les deux blocs pour une lecture plus logique : d’abord l’explication, ensuite l’offre.
L’inversion des blocs sur la homepage a permis d’augmenter les transactions de 9%.
Clarté
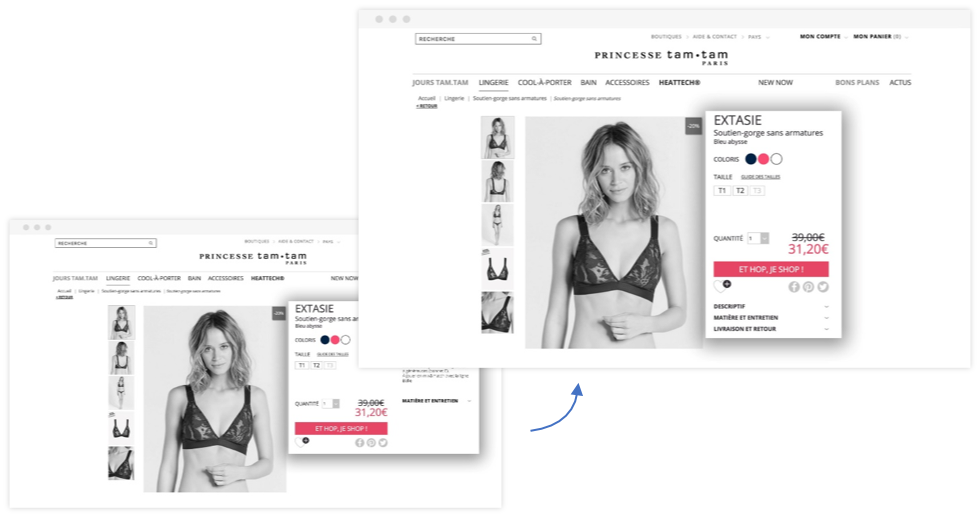
Bien que la page produit sur le site web de Princesse TamTam soit déjà épurée et compréhensible, l’équipe digitale de la marque savait qu’il était possible de donner encore plus de lisibilité à ces pages.
Pour plus de clarté, elle a opté pour la simplification de la page produit. En cachant la description du produit (passée au format onglet), la fiche produit n’affiche que l’essentiel et rend ainsi le CTA plus visible.
Ces améliorations ont permis de maximiser les clics sur le CTA de + 12%.
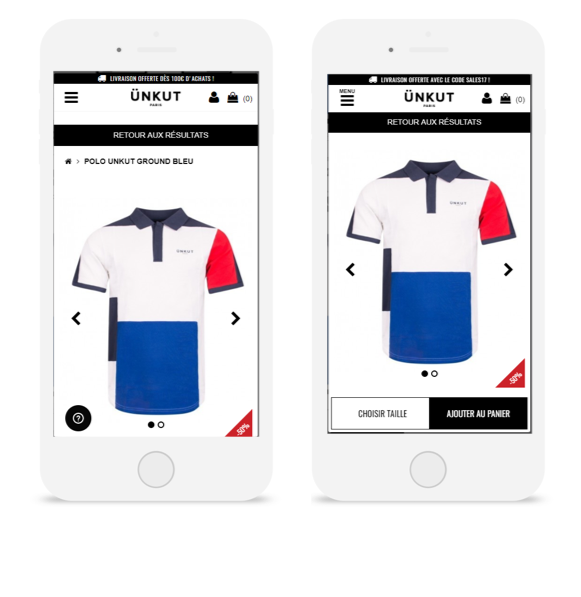
Distraction
Quand nous passons d’un écran d’ordinateur à celui d’un smartphone, les informations sont perçues autrement.Ünkut l’a bien compris et a voulu tester l’optimisation du CTA selon le device.
Sur mobile, l’internaute était obligé de scroller pour découvrir le CTA sur les fiches produits – et donc passer à l’action. De plus, beaucoup d’informations sont disponibles avant le CTA, ce qui peut être source de distraction pour le visiteur.
L’équipe digitale de la marque a déployé une variation avec un CTA fixe au scroll, ce qui a permis d’augmenter de 55% les clics sur ce CTA et de manière générale les transactions de 7%.
Anxiété
La marque agnès b. avait identifié un point de friction chez les consommateurs d’agnès b. durant leur parcours d’achat. Supprimer l’anxiété dans le parcours d’un acheteur permettrait-il réellement d’augmenter les ventes ?
C’est ce que l’équipe digitale a voulu tester en maximisant la visibilité des éléments de réassurance dès la page produit.
En précisant que la livraison est offerte dès 250 € et que les retours sont gratuits sur la fiche produit, les internautes se sentent rassurés. Et grâce à ça, les transactions ont doublé.
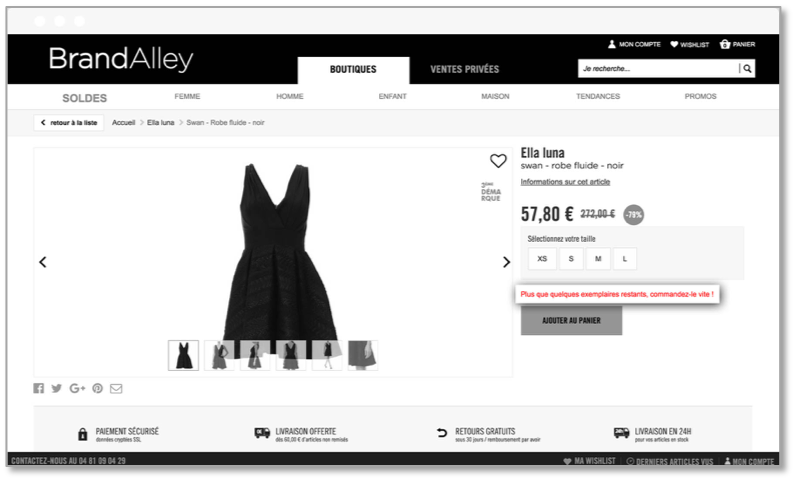
Urgence
Les techniques de stress marketing peuvent être très utiles, à condition qu’elles soient bien utilisées. Attention, trop de messages d’urgence peuvent rapidement créer un contexte anxieux!
BrandAlley a utilisé cette technique pour inciter l’internaute à prendre une décision plus rapidement. En affichant que le produit consulté n’est bientôt plus disponible, le produit devient alors rare et donc encore plus désirable. Il faut agir vite !
Une technique efficace qui a augmenté le taux de transactions de 4% sur le site de BrandAlley.
Le modèle LIFT est aussi simple que puissant : une fois que vous aurez maîtrisé ces 6 facteurs, vous serez en mesure de les appliquer dans un contexte précis et ainsi maximiser vos conversions. Ce modèle nous permet de mettre en lumière une chose très importante : se mettre à la place de l’internaute. C’est uniquement en voyant votre site, vos pages ou vos landing pages sous un autre oeil que vous serez en mesure de les optimiser davantage.
De nombreux clients nous demandent ce qui ne va pas dans leurs tests précédents, pourquoi ils n’ont pas fonctionné autant qu’ils espéraient ? Dans chaque cas, nous utilisons cette méthode pour évaluer les différents types de pages et ainsi, développer des hypothèses de tests fiables et adaptées à un contexte très précis. Conversions garanties 😉






 Chad Sanderson (Convoy)
Chad Sanderson (Convoy) Jonny Longden (Journey Further)
Jonny Longden (Journey Further)
 Léa Benquet, CSM chez AB Tasty
Léa Benquet, CSM chez AB Tasty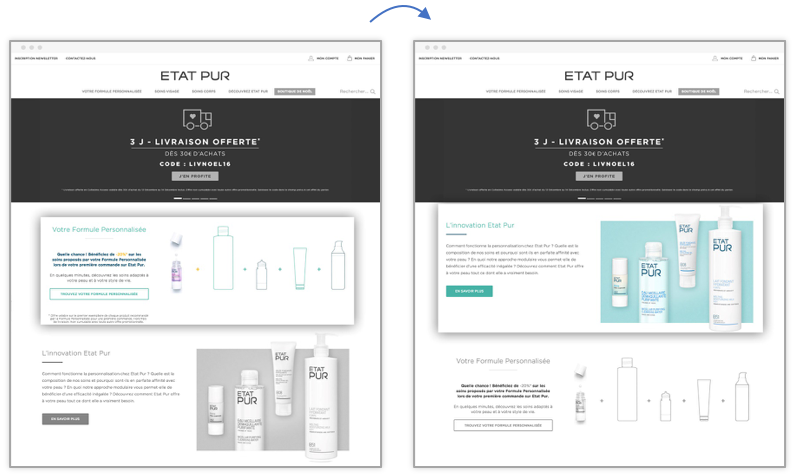
 L’équipe digitale de la marque a déployé une variation avec un CTA fixe au scroll, ce qui a permis d’augmenter de 55% les clics sur ce CTA et de manière générale les transactions de 7%.
L’équipe digitale de la marque a déployé une variation avec un CTA fixe au scroll, ce qui a permis d’augmenter de 55% les clics sur ce CTA et de manière générale les transactions de 7%.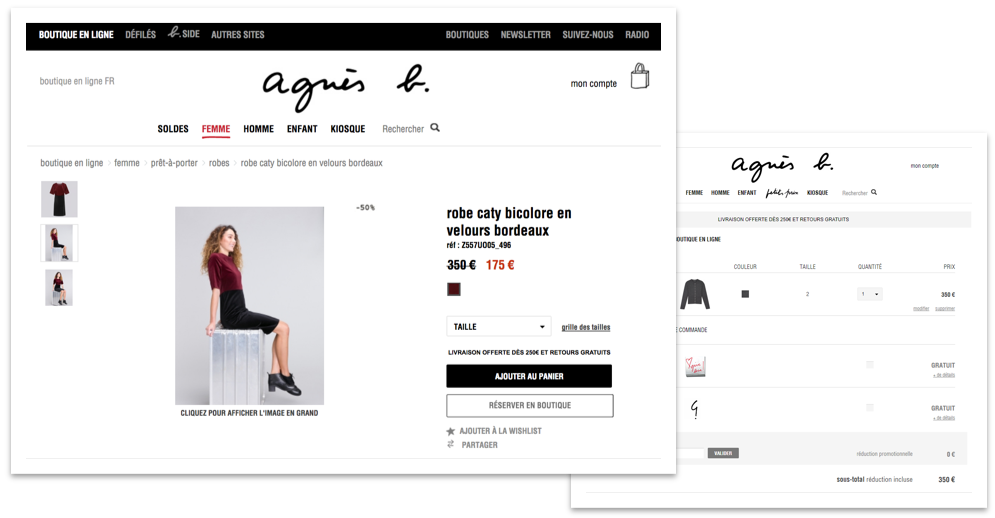
 Guillaume Le Roux, CSM chez AB Tasty
Guillaume Le Roux, CSM chez AB Tasty