

A/A tests are a legacy from the early days of A/B testing. It’s basically creating an A/B test where two identical versions of a web page or element are tested against each other. Variation B is just a copy of A without any modification.
One of the goals of A/A tests is to check the effectiveness and accuracy of testing tools. The expectation is that, if no winner is declared, the test is a success. Whereas detecting a statistical difference would mean a failure, indicating a problem somewhere in the pipeline.
But it’s not always that simple. We’ll dive into this type of testing and the statistics and tech behind the scenes. We’ll look at why a failed A/A test is not a proof of pipeline failure, and that a successful A/A test isn’t a foolproof sanity check.
What is tested during an A/A test?
Why is there so much buzz around A/A testing? An A/A test can be a way to verify two components of an experimentation platform:
- The statistical tool: It may be possible that the formulas chosen don’t fit the real nature of the data, or may contain bugs.
- The traffic allocation: The split between variations must be random and respect the proportions it has been given. When a problem occurs, we talk about Sample Ratio Mismatch (SRM); that is, the observed traffic does not match the allocation setting. This means that the split has some bias impacting the analysis quality.
Let’s explore this in more detail.
Statistical tool test
Let’s talk about a “failed” A/A test
The most common idea behind A/A tests is that the statistical tool should yield no significant difference. It is considered a “failed” A/A test if you detect a difference in performance during an A/A test.
However, to understand how weak this conclusion is, you need to understand how statistical tests work. Let’s say that your significance threshold is 95%. This means that there is still a 5% chance that the difference you see is a statistical fluke and no real difference exists between the variations. So even with a perfectly working statistical tool, you still have one chance in twenty (1/20=5%) that you will have a “failed” A/A test and you might start looking for a problem that may not exist.
With that in mind, an acceptable statistical procedure would be to perform 20 A/A tests and expect to have 19 that yield no statistical difference, and one that does detect a significant difference. And even in this case, if 2 tests show significant results, it’s a sign of a real problem. In other words, having 1 successful A/A test is in fact not enough to validate a statistical tool. To validate it fully, you need to show that the tests are successful 95% of the time (=19/20).
Therefore, a meaningful approach would be to perform hundreds of A/A tests and expect ~5% of them to “fail”. It’s worth noting that if it “fails” less than 5% of the time it’s also a problem, maybe indicating that the statistical test simply says “no” too often, leading to a strategy that never detects any winning variation. So one A/A “failed” test doesn’t tell much in reality.
What if it’s a “successful A/A test”?
A “successful” A/A test (yielding no difference) is not proof that everything is working as it should. To understand why, you need to check another important tool in an A/B test: the sample size calculator.
In the following example, we see that from a 5% conversion rate, you need around 30k visitors per variation to reach the 95% significance level if a variation yields a 10% MDE (Minimal Detectable Effect).
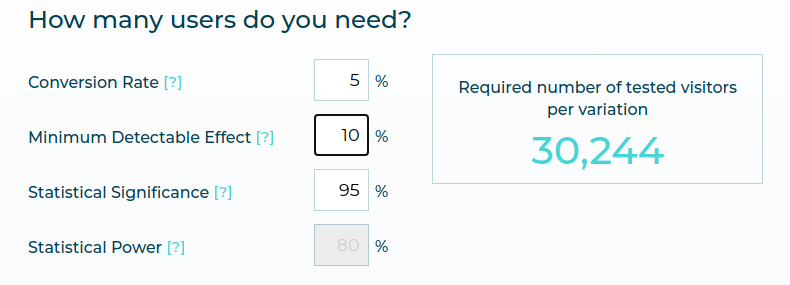
But in the context of an A/A test, the Minimal Detectable Effect (MDE) is in fact 0%. Using the same formula, we’ll plug 0% as MDE.
At this point, you will discover that the form does not let you put a 0% here, so let’s try a very small number then. In this case, you get almost 300M visitors, as seen below.
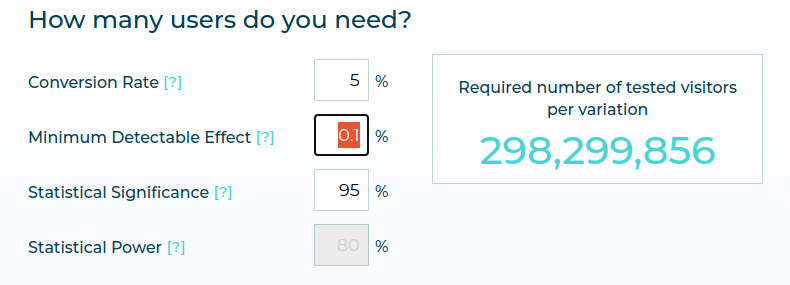
In fact, to be confident that there is exactly no difference between two variations, you need an infinite number of visitors, which is why the form does not let you set 0% as MDE.
Therefore, a successful A/A test only tells you that the difference between the two variations is smaller than a given number but not that the two variations perform exactly the same.
This problem comes from another principle in statistical tests: the power.
The power of a test is the chance that you discover a difference if there is any. In the context of an A/A test, this refers to the chance you discover a statistically significant discrepancy between the two variations’ performance.
The more power, the more chance you will discover a difference. To raise the power of a test you simply raise the number of visitors.
You may have noticed that in the previous screenshots, tests are usually powered at 80%. This means that even if a difference exists between the variations in performance, 20% of the time you will miss it. So one “successful” A/A test (yielding no statistical difference) may just be an occurrence of this 20%. In other words, having just one successful A/A test doesn’t ensure the efficiency of your experimentation tool. You may have a problem and there is a 20% chance that you missed it. Additionally, reaching 100% of power will need an infinite number of visitors, making it impractical.
How do we make sure we can trust the statistical tool then? If you are using a platform that is used by thousands of other customers, chances are that the problem would have already been discovered.
Because statistical software does not change very often and it is not affected by the variation content (whereas the traffic allocation might change, as we will see later), the best option is to trust your provider, or you can double-check the results with an independent provider. You can find a lot of independent calculators on the web. They only need the number of visitors and the number of conversions for each variation to provide the results making it quick to implement.
Traffic allocation test
In this part, we only focus on traffic, not conversions.
The question is: does the splitting operation work as it should? We call this kind of failure a SRM or Sample Ratio Mismatch. You may ask yourself how a simple random choice could fail. In fact, the failure happens either before or after the random choice.
The following demonstrates two examples where that can happen:
- The variation contains a bug that may crash some navigators. In this case, the corresponding variation will lose visitors. The bug might depend on the navigator and then you will end up with bias in your data.
- If the variation gives a discount coupon (or any other advantage), and some users find a way to force their navigator to run the variation (to get the coupon), then you will have an excess of visitors for that variation that is not due to random chance, which results in biased data.
It’s hard to detect with the naked eye because the allocation is random, so you never get sharp numbers.
For instance, a 50/50 allocation never precisely splits the traffic in groups with the exact same size. As a result, we would need statistical tools to check if the split observed corresponds with the desired allocation.
SRM tests exist. They work more or less the same way as an A/B test except that the SRM formula indicates whether there is a difference between the desired allocation and what really happened. If there is indeed an SRM, then there is a chance that this difference is not due to pure randomness. This means that some data is lost or bias occurred during the experiment entailing trust for future (real) experiments.
On the one hand, detecting an SRM during an A/A test sounds like a good idea. On the other hand, if you think operationally it might not be that useful because the chance of a SRM is low.
Even if some reports say that they are more frequent than you may think, most of the time it happens on complex tests. In that sense, checking SRM within an A/A test will not help you to prevent having one on a more complex experiment later.
If you find a Sample Ration Mismatch on a real experiment or in an A/A test, the following actions remain the same: find the cause, fix it, and restart the experiment. So why waste time and traffic on an A/A test that will give you no information? A real experiment would have given you real information if it worked fine on the first try. If a problem does occur, we would detect it even in a real experiment since we only consider traffic and not conversions.
A/A tests are also unnecessary since most trustworthy A/B testing platforms (like AB Tasty) do SRM checks on an automated basis. So if an SRM occurs, you will be notified anyway.
So where does this “habit” of practicing A/A tests come from?
Over the years, it’s something that engineers building A/B testing platforms have done. It makes sense in this case because they can run a lot of automated experiments, and even simulate users if they don’t have enough at hand, performing a sound statistical approach to A/A tests.
They have reasons to doubt the platform in the works and they have the programming skills to automatically create hundreds of A/A tests to test it properly. Since these people can be seen as pioneers, their voice on the web is loud when they explain what an A/A test is and why it’s important (from an engineering perspective).
However, for a platform user/customer, the context is different as they’ve paid for a ready-to- use and trusted platform and can start a real experiment as soon as possible to get a return on investment. Therefore, it makes little sense to waste time and traffic on an A/A test that won’t provide any valuable information.
Why sometimes it might be better to skip A/A tests
We can conclude that a failed A/A test is not a problem and that a successful one is not proof of sanity.
In order to gain valuable insights from A/A tests, you would need to perform hundreds of them with an infinite number of visitors. Moreover, an efficient platform like AB Tasty does the corresponding checks for you.
That’s why, unless you are developing your own A/B testing platform, running an A/A test may not give you the insights you’re looking for. A/A tests require a considerable amount of time and traffic that could otherwise be used to conduct A/B tests that could give you valuable insights on how to optimize your user experience and increase conversions.
When it makes sense to run an A/A test
It may seem that running A/A tests may not be the right call after all. However, there may be a couple of reasons why it might still be useful to perform A/A tests.
First is when you want to check the data you are collecting and compare it to data already collected with other analytics tools but keep in mind that you will never get the exact same results. The reason is that most of the metric definitions vary on different tools. Nonetheless this comparison is an important onboarding step to ensure that the data is properly collected.
The other reason to perform an A/A test is to know the reference value for your main metrics so you can establish a baseline to analyze your future campaigns more accurately. For example, what is your base conversion rate and/or bounce rate? Which of these metrics need to be improved and are, therefore, a good candidate for your first real A/B test?
This is why AB Tasty has a feature that helps users build A/A tests dedicated to reach these goals and avoids the pitfalls of “old school” methods that are not useful anymore. With our new A/A test feature, A/A test data is collected in one variant (not two); let’s call this an “A test”.
This allows you to have a more accurate estimation of these important metrics as the more data you have, the more accurate the measurements are. Meanwhile, in a classic A/A test, data is collected in two different variants which provides less accurate estimates since you have less data for each variant.
With this approach, AB Tasty enables users to automatically set up A/A tests, which gives better insights than classic “handmade” A/A tests.



