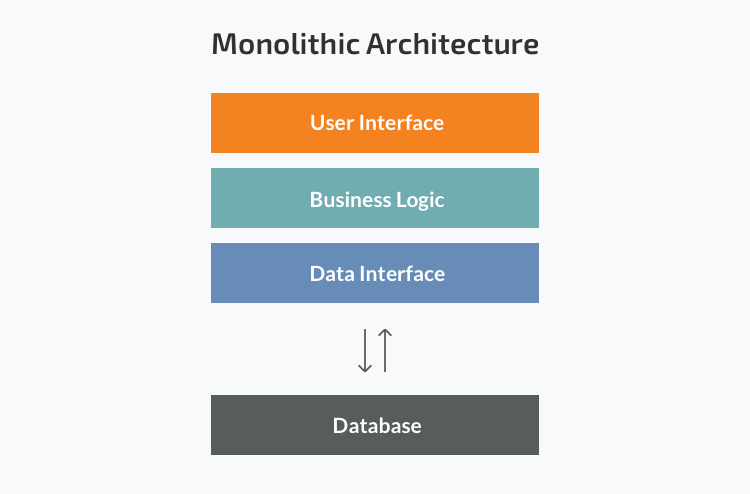
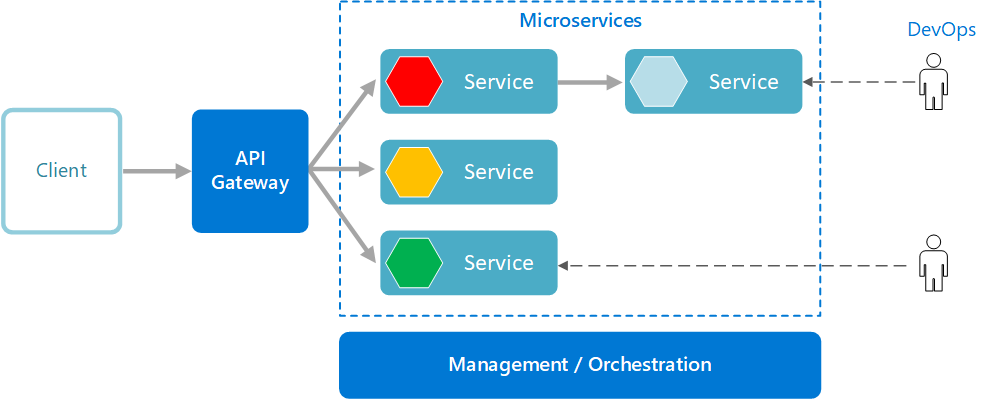
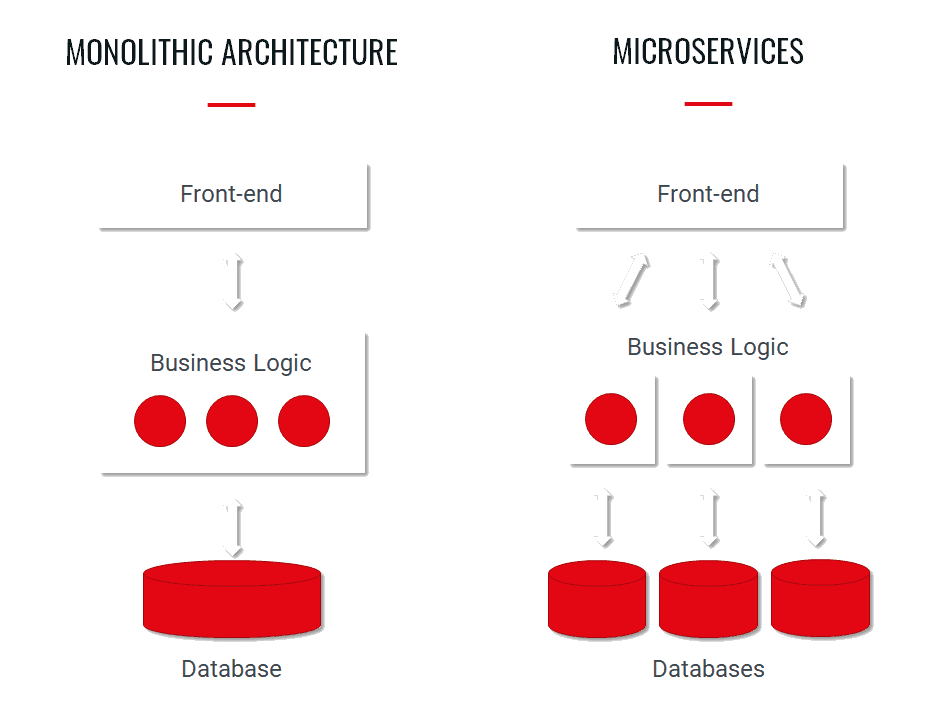
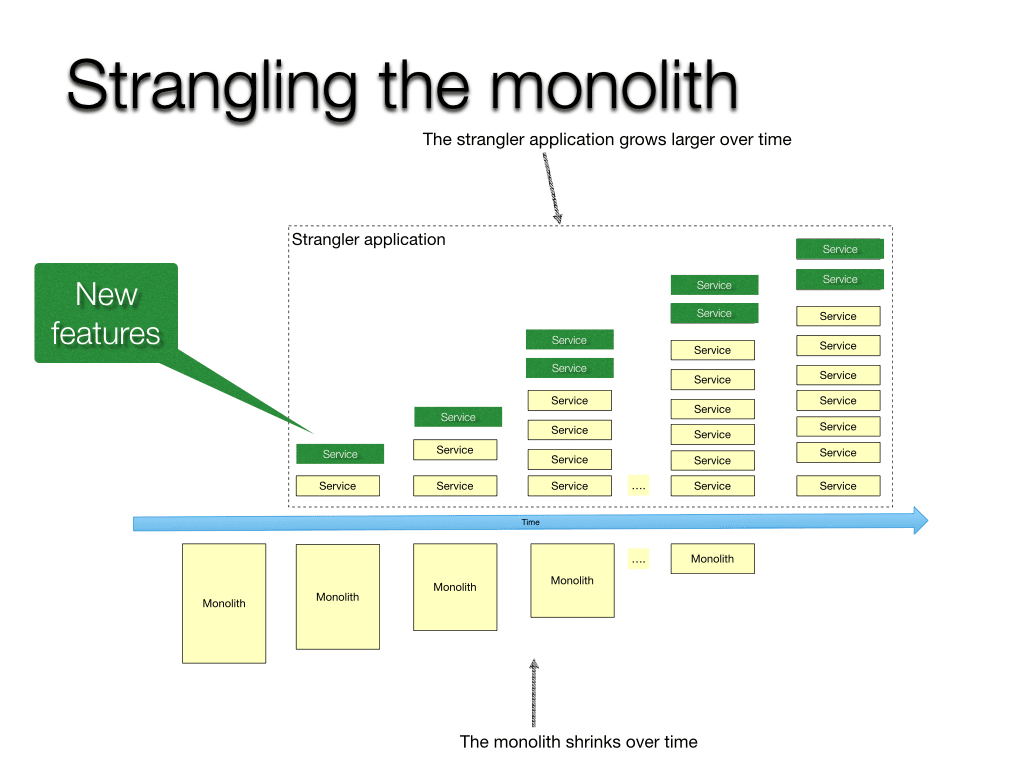
In a rapidly changing world with constantly evolving consumer demands, companies must continuously review their features and products to decide what they need to develop and optimize to remain competitive in their respective markets.
However, it’s not merely developing new features that companies need to think about. They also need to consider what features to retire in order to pave the way for new, more impactful features or to put it simply, to free up resources to develop these new features.
In other words, as well as developing new features, teams must also consider killing off older features and/or features that are not delivering on their promise. Removing a feature will then allow teams to reprioritize and direct their time and energy towards more profitable pursuits.
Retiring or sunsetting features is not as easy as it sounds. It’s not just waking up one day and deciding that an old feature has run its course and then simply removing it altogether.
The reality is much different. A sunset executed poorly may leave a lot of unhappy customers in its wake and at worst lead you to losing these customers.
Therefore, it requires careful planning and consideration across various teams. Just as you would onboard users to new features, you should consider how to offboard users when killing a feature to allow them to see new value in your product.
In our newest addition to our ‘Feature Experimentation’ series, we will walk you through how to correctly and efficiently sunset a feature with minimal negative impact on your customers and to help you in deciding whether it’s truly time to let a particular feature go.
Read more: To read the first post in our series on feature experimentation best practices, click here. To read the second post on outcome-driven roadmaps, click here.
Why do companies decide to sunset products and/or features?
First, it’s important to address why companies decide to retire some of their features instead of keeping them around indefinitely.
Look at it this way: developers spend a lot of time painstakingly developing features but they may also spend this time working on and maintaining a feature that may be used only by a small percentage of users, time which could be spent working on something which could bring greater value and revenue, such as new, more innovative features.
Any feature that is developed requires ongoing maintenance and support, which may use up resources you could be using to develop new features that satisfies your customers’ current needs rather than holding onto underperforming features.
Therefore, a certain feature might not be generating enough revenue in order to support the costs and resources used to maintain it.
There’s also the major issue of technical debt. When you let all your features pile up in your system, you eventually start to lose track of them and may accumulate into unwanted debt resulting in a breakdown of the software development and maintenance life cycle.
Thus, some reasons which could prompt some companies to retire certain features include:
- Low feature usage over time or feature engages a small number of users
- Based on feedback from users
- New features that replace existing ones
- High costs i.e technical debt and drain of resources
- No longer aligns with overall company strategy and objectives
Steps to follow to effectively sunset a feature
Consider your decision carefully before retiring a feature
Initially, there are a few questions you should be able to answer before retiring any features. These include:
- What percentage of users are actually using the feature?
- How is the feature being used and what kind of customers use it?
- What are the costs and risks of sunsetting the feature compared to the current costs of maintaining the upkeep of this feature?
- Do you have a communication plan in place to inform your customers of your decision before going ahead with the sunset?
Consider how the feature fits into your short- and long-term goals. In terms of long-term goals, look at the bigger picture and consider whether your existing features fit in with your company’s long term goals and vision.
In the short-term, you should think about whether a certain feature still solves a pain point or problem that is still ongoing or whether this problem is no longer relevant.
Most importantly, look into your overall product strategy and use it as the basis for evaluating your features and their value to determine whether to keep or retire some of these features.
Check the data
To be able to answer questions such as the above, you will need to check what the data says.
The first couple of questions raised above focused on product usage. This is because product usage is usually one of the primary reasons why companies decide to retire a feature or product.
For example, if you start to see Monthly Active Users (MAU) numbers going down, this is your first indication that something is amiss with this feature and so you will need to investigate as to why that is.
Thus, at this point, you will want to track feature engagement. There are various tools that could help you do that.
However, be careful when it comes to tracking usage.
If you do happen to see low usage levels, there could be other reasons such as the feature being too complex to use or access rather than a case of your customers not finding a certain feature valuable anymore.
Therefore, take the time to properly evaluate the reasons for the low usage before making the decision to sunset the feature.
It could also be that there is low usage but the users who are using the feature are among your valuable and highest-paying customers, then it could mean that you simply need to market that feature more efficiently.
To address these doubts, you will need to go straight to the source by directly communicating with your customers. More on that in a bit.
Another indication could be if you start to see a downward trend in your sales then this is a clear red flag. For that, you can look at metrics such as churn rate as well as customer acquisition and retention rates.
To have context for all this data, it’s essential to speak to different teams. For example, talk to your sales team to determine whether a certain feature is a ‘hard sell’ and understand how and if they’re closing deals that include this feature.
You can also talk to your development team to gain a deeper understanding of any issues that are being raised with a certain feature and whether fixing these issues are costing them time and money.
In other words, take a look at the number of bugs that are being reported in regards to this feature. If there’s a large quantity of negative feedback then you know that customers are less than happy with it and that there are issues which need to be addressed.
This will help you have a good idea of what this feature is costing your company when it comes to customer support time and resources as well as how much time your development team is devoting to said feature from bug fixes to testing and maintenance.
Aside from your teams, you need to speak to external stakeholders as well- your customers. This brings us to the next point.
Talk to your customers
Looking at numbers gives you a good idea of how the feature is performing but to get to the root cause of the issue, you will need to speak to customers to provide some context to the downward trend you’ve uncovered.
The data will reveal whether a feature is not being used but it will not tell you why it’s not being used by customers.
You can segment your customers into those that use the feature and those that don’t, for example, and conduct customer research to better understand their perspectives.
You can also choose to be more specific in your segmentation to find patterns in feature usage by dividing users based on company, industry, role, etc.
Conducting customer or user research, such as interviews, could further provide you with meaningful insight into your customers’ needs and whether this feature provides the solution to their problem.
Have a communication strategy in place
If you decide to go for the sunsetting route, then you need to make sure you have a communication strategy in place as part of your phase-out plan, both internally with your teams and externally with your customers.
These represent two distinct processes and each should have its own plan.
You’ll need to give notice in advance of the sunset allowing for a grace period and enough time to transition from the feature.
Be sure to also communicate what alternatives there are for your customers to use instead and educate them on how to use them, i.e set up an onboarding process to ease the transition.
However, you will also need to communicate internally with your team first to make sure everyone is aligned and is clear on the sunsetting process and the actions that need to be taken to ensure a smooth transition.
They will need to be carefully briefed so they’re prepared to deal with any fallout and to provide the necessary support for the upcoming changes.
In this scenario, the product marketing team usually takes over to oversee the transition and to assist with any training that may be needed so that the rest of your team knows how to talk to customers and be able to answer their questions and concerns.
Everyone will also need to be clear on the timelines. For example, let your sales and customer success teams know the dates in which you’re planning to retire the feature so they can prepare accordingly.
When it comes to your customers, start putting a plan together of how you will communicate the sunset.
Consider which channels you’ll use and are most appropriate to communicate this information. Some of the information you’ll need to put forward include:
- Why you’re removing the feature
- What are the benefits of sunsetting the feature
- Give a clear timeline of the sunset to give customers ample time to prepare. The timeline chosen will depend on the feature in question and how much impact it will cause by removing it
- As already mentioned, you should be able to provide a substitute and support to help them migrate to it
Buffer, a tool that helps customers build their brands and grow their business on social media, is an example of one company that we think effectively communicated the sunset of one of its features ‘Reply’. In a blog post by the CEO, the company provides its reasons for the sunset then talks about a new solution it’s building that’s better suited for its customers.
The post concludes by giving a list of partners that provide alternatives to ‘Reply’ with offers to ‘make a move more manageable’.
We’ve also talked previously about segmenting your customers when you want to have discussions with them to understand their usage pattern of the feature.
Likewise, during the actual sunsetting process, you can also create different communication strategies according to the types of users for the feature: those that are frequent and hard-core users of the feature and ‘dabblers’, those who have not used the feature much and thus do not rely on it like the hard-core users and, in turn, would not be heavily impacted by the sunset.
You can even create another third segment of ‘disengaged’ users who have either stopped using the feature or never used it in the first place.
Establishing such segmentation will help you to choose the appropriate channels to reach out to them and create more personalized messaging for each group of users according to their usage rate.
Remember, deprioritizing and phasing out certain features will likely involve cross-team and company-wide feedback so you need to decide how and who is involved in the final decision.
The important thing is to be transparent with all the relevant stakeholders so they’re all clear on why and how this change is in the works.
Remove the feature
When you decide to sunset or phase out a feature, make sure to remove all mentions of the feature from all marketing and sales material. If relevant, replace it with the alternative.
You can keep providing support for it in the phase-out period but make sure to let new users know this feature will be retired and will no longer be supported.
You may even consider removing access to the feature altogether for new users and users who have never used it before so the number of affected users remains low.
By the time you retire the feature, you should have a clear idea of where the resources and budget dedicated to the retired feature will be allocated so your team has a clear plan of action in terms of the direction the company is heading towards and what kind of features are on the horizon that they’ll be working on.
However, the work doesn’t end when you sunset the feature. You need to think of the impact of this sunset.
This means you’ll need to monitor the results of your change by tracking some key metrics to understand better how your customers are reacting to the sunset.
If, for example, the old feature had many bug incidents that were reported, you can compare it to the number of support tickets being raised for development teams after feature removal, whether they’ve decreased.
If you’re offering an alternative, you’ll need to track its usage and how many users are turning to this alternative feature.
Sunsetting with feature flags
You’ve probably heard of feature flags. They basically reduce risk of new releases by decoupling deployment from release allowing you to enable or disable features or enable them for certain users.
Consequently, feature flags play a valuable role in launching new functionalities but they’re also great for retiring old features. In fact, feature flags are a fool-proof way to manage a feature along its entire lifecycle from launch to retirement or sunsetting.
In other words, feature flags give teams the ability to sunset features that are no longer necessary.
Product teams can use feature flags to remove old features gradually in order to give customers time to wean off the feature so the process is not abrupt and to help ease the transition from the old feature.
Feature flags, therefore, allow you to track the usage of features to determine their usage by customers and then efficiently sunset any old, unused features to keep your code base clean and running smoothly.
We mentioned previously how you can prevent new users from accessing old features that you want to retire or users who had not used these features before.
Feature flags essentially provide a switch to toggle off about-to-be retired features for these users and, if relevant, slowly transition current users to the new, alternative feature.
You should also have a sunsetting process in place to not only remove old features but also to remove old flags in your system.
If you use feature flags extensively across several use cases and teams, you need to make sure that you keep track of all the flags you’re using with the help of a feature management tool and then sunset those flags once they’re no longer needed to avoid the accumulation of technical debt.
To bring it all together
As we’ve seen, the process behind sunsetting a feature may be long and delicate so tread carefully.
What it all comes down to is you basically need to make sure you have a solid plan in place when you make a sunsetting decision so that the process is clear to everyone in the organization. One way to help you do that is to create a ‘sunsetting roadmap’.
In a previous post in the ‘Feature Experimentation’ series, we discussed how to build an outcome-driven roadmap for feature experimentation. It might also help to consider building a specific roadmap for sunsetting your features to allow you to visualize and map out your plan for phasing out your feature.
It will not only give you a clear step-by-step plan of the sunsetting process but it will also allow you to look at the bigger picture and see if going ahead with the sunset is the right move in the first place by enabling you to see how and if this feature still fits in with your long-term organizational goals.
It will also help you when it comes to discussing your sunsetting decision with other members of your organization and the key decision-makers within it.
The sun will surely rise again
Think about when you develop a new feature. A lot of hard work goes into thinking about what kind of features to build and then into the development and release processes.
The same kind of careful planning should also occur when deciding to remove a feature.
Yes, there might be some slight bumps along the road to sunsetting but if you’ve thought it through and you have valid reasons to phase out a feature backed by solid data and feedback, you’ll start to see more of a positive impact in the long-term.
The key to effective sunsetting is to prepare everyone, internally and externally, for the change and to guide them so that they may see new value in your product and features. That way, you’ll be able to retain and even increase user engagement among existing and new customers alike.