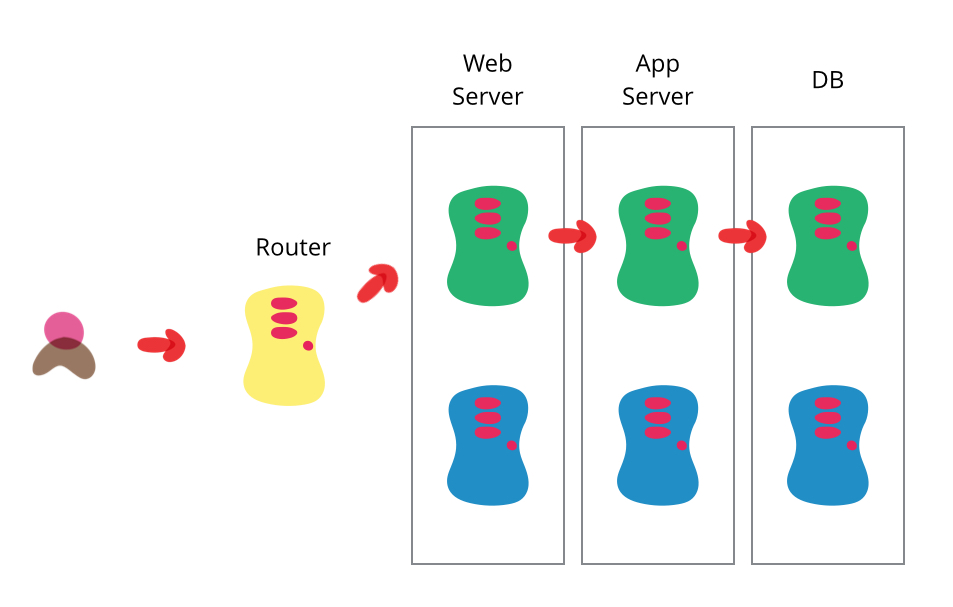
As organizations increasingly adopt an Agile methodology into their software development processes, this means that teams are now releasing more frequently in smaller batches.
Therefore, changes are being merged into the mainline multiple times a day making it difficult to determine when changes are actually being rolled out.
The developers usually aren’t the only ones who need to know about the release of new changes or features. Product teams are also just as involved in the release process.
With such frequent releases, things can become highly stressful. Fortunately, nowadays, teams can automate these processes, freeing them up to focus on more important and less repetitive tasks.
One such software is the Jira platform that can contribute to better, more efficient releases.
In this article, we will look into just how you can incorporate Jira software into your release management process to help improve collaboration and communication between your teams.
Jira software overview
First, we will start with a quick overview of Jira software. Created by Atlassian, this software helps you plan, track and release software in software development projects.
It is one of the most popular tools used by Agile teams to manage their releases by offering all team members full visibility over the release process, enhancing collaboration between engineering and product teams to plan and track releases and increase productivity across the organization.
Initially, this software was developed to track issues and bugs and has since evolved into a work management tool for a wide range of use cases.
When it comes to product management, Jira can be used to build roadmaps for each project allowing teams to track and share their progress for the roadmap.
Jira takes a customer-centric approach when it comes to designing projects and it’s highly customizable making it a popular tool among Agile teams to incorporate into software development processes.
Getting started with Jira
You will start by creating a project, where you will pick a template depending on your team’s requirements. You can choose from scrum, kanban and bug tracking. For every project, Jira creates a board to help you see a visual representation of your work.
Before you create a project, consider how you will organize your projects. The best way to do so is to organize your projects according to how your company runs; whether, for example, you’d rather organize by product if you’re constantly releasing software or if you’d rather organize by team.
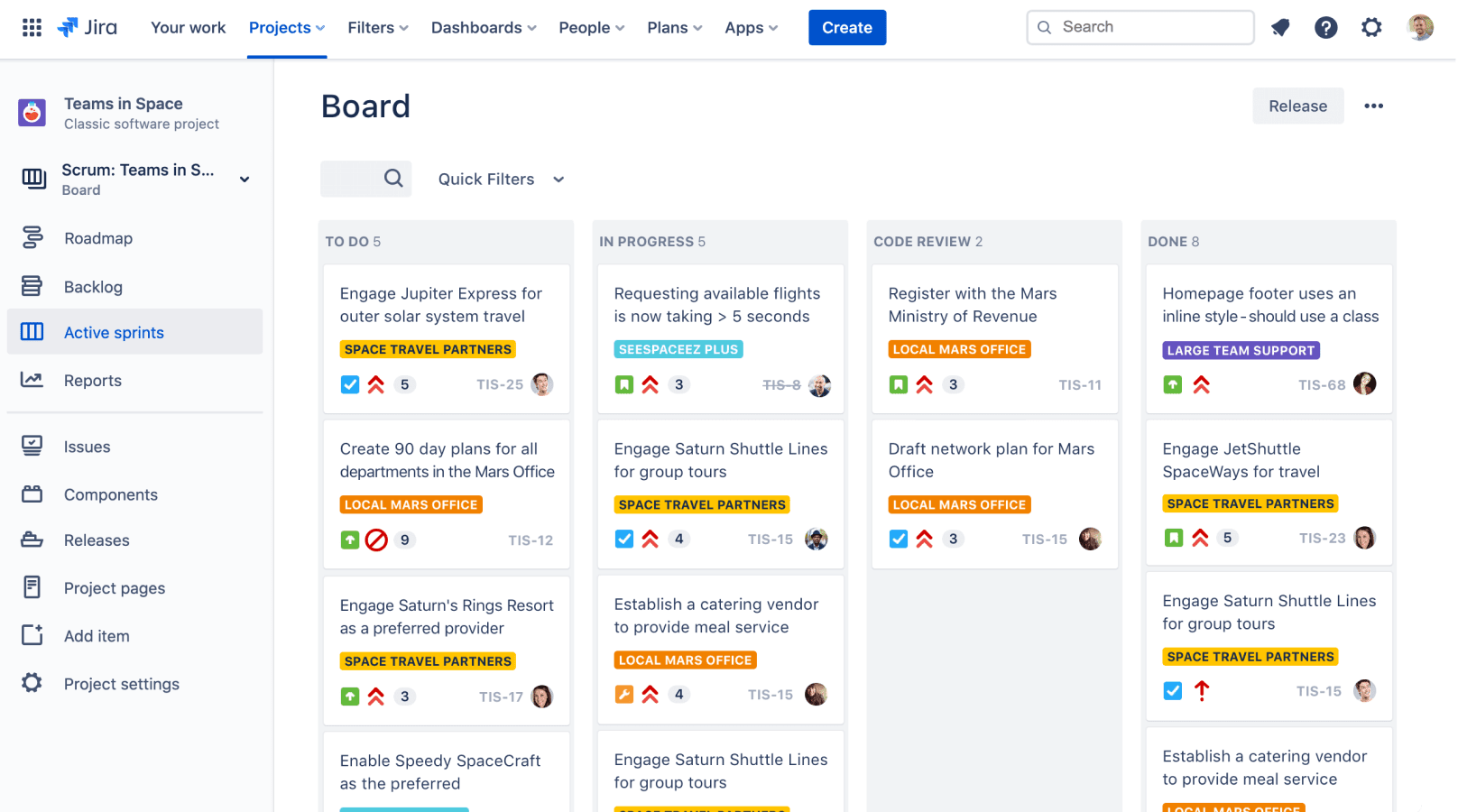
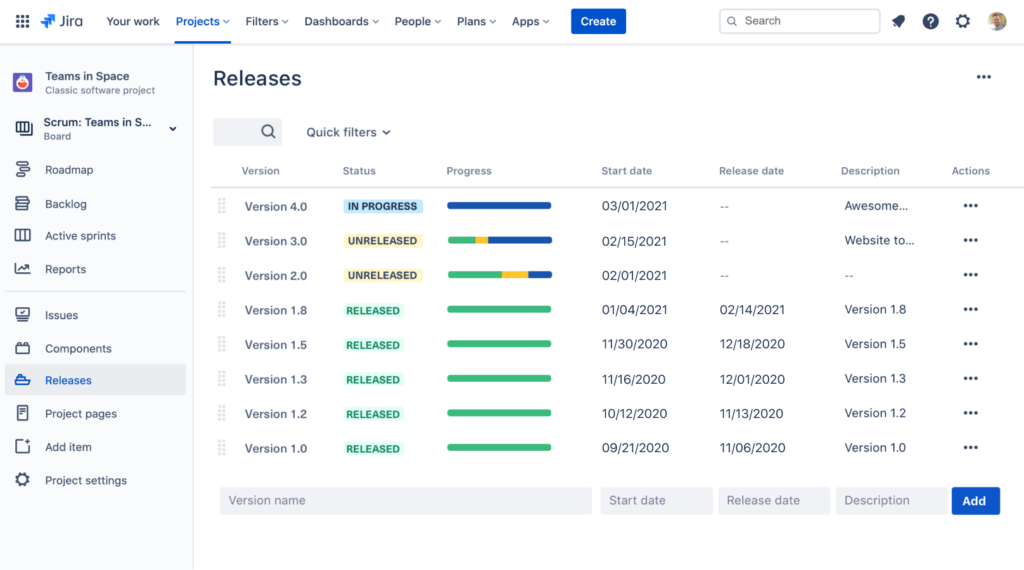
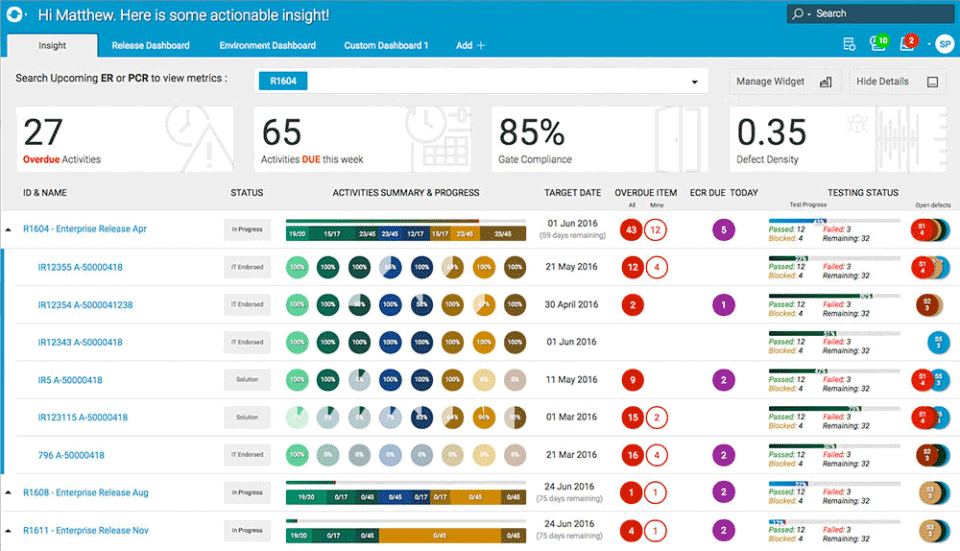
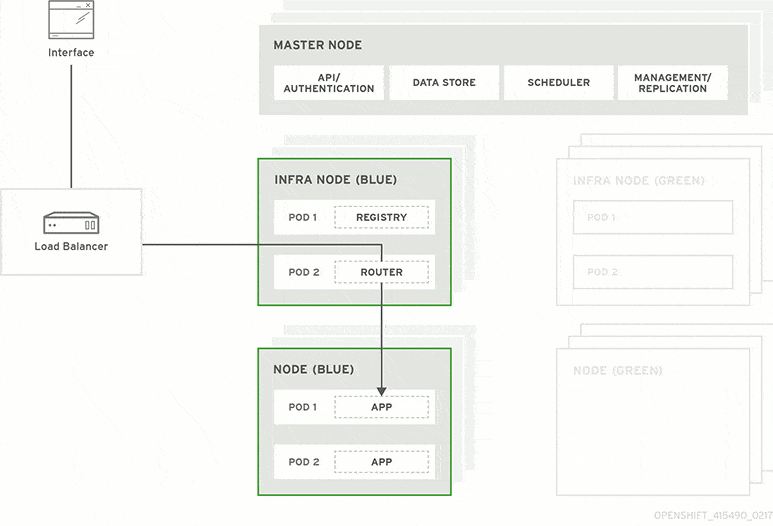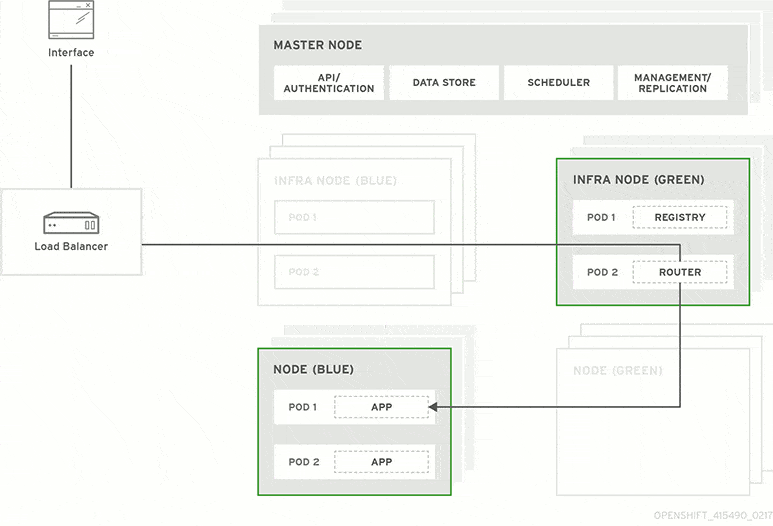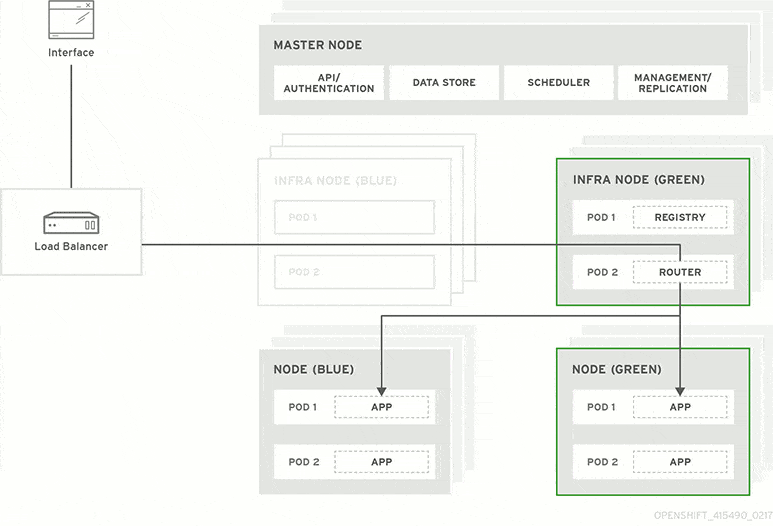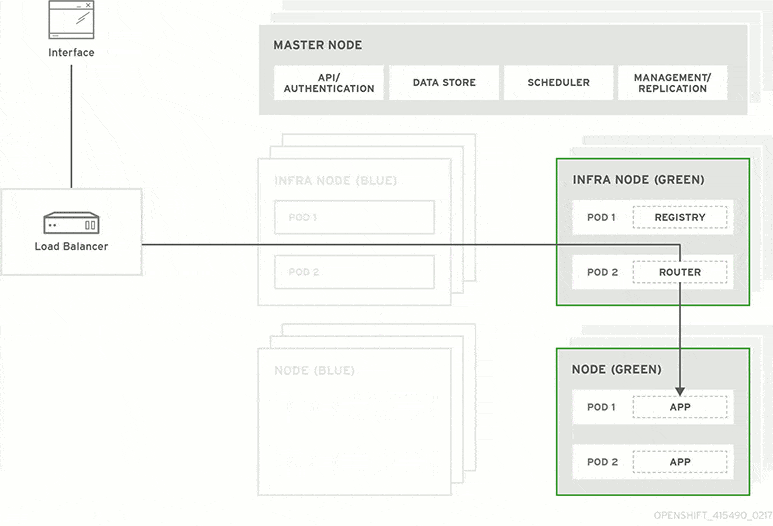
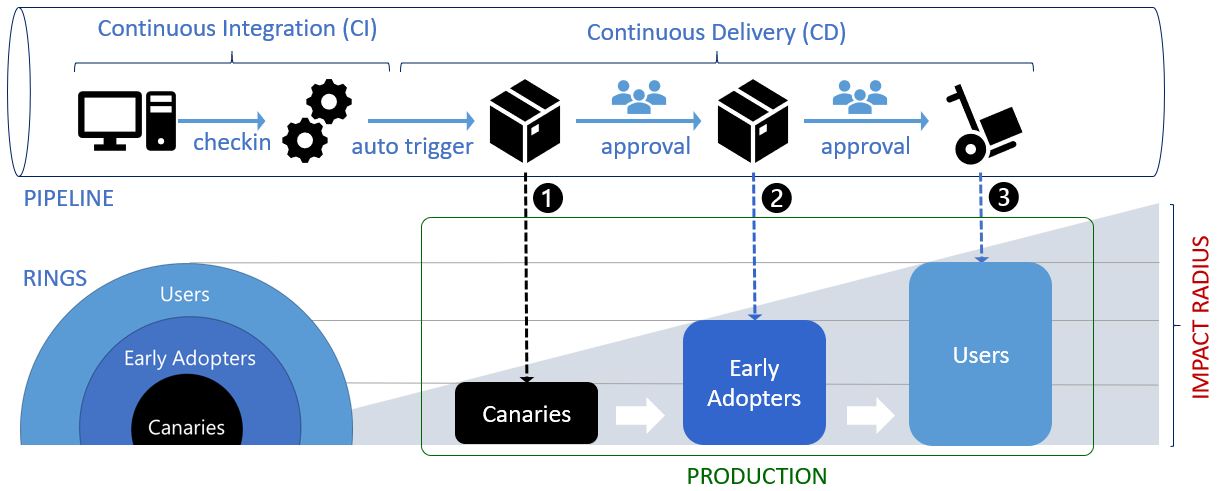
To manage releases in Jira, the first step is to create a version.
To do so, click on ‘Releases’ as can be seen in the image above, where you will be prompted to create name, start & end dates and description.
You can then assign any issue type to the releases to track their statuses throughout their life cycle.
The release could contain tasks with different statuses such as in progress or closed.
Better release management with Jira
Jira issues
An issue is a work item that can be tracked throughout its life cycle. It can, for example, be a product feature or software; issues are essentially the building blocks of your Jira software project. It can also be referred to as a task, request or ticket.
Jira issue allows you to track individual pieces of work that should be completed. Thus, it notifies your team of any updates by allowing them to track the issue and lets them know if there are any comments or of any change in update status.
Jira workflows
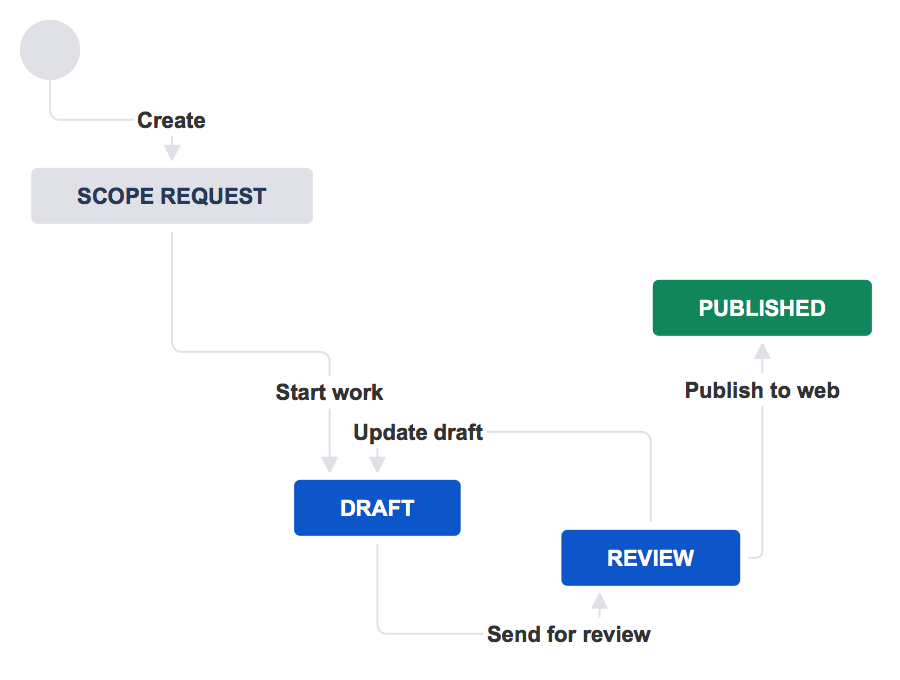
Jira provides a way to customize the way issues transition through the development phases, also referred to as workflows. These can be customized to suit the needs of your project.
Since the Jira platform is flexible, you can add more statuses to track which issues are included in a specific release.
The default Jira platform has three default statuses:
A few more statuses can be added to help teams track the status of their work more precisely. Thus, more statuses can be added such as:
Awaiting release
Ready to merge
Once your team becomes more comfortable with the basic workflow, optimize it by creating statuses for each type of work in the process. Build, design, development, code and test can all, for example, be individual statuses, which can then be shared with the rest of the organization.
Roadmaps in Jira
In our release management guide, we mentioned how essential a product roadmap is to ensure the success of your products.
Roadmaps in Jira help teams see the bigger picture when it comes to their work and how they’re contributing to larger business goals.
Thus, a roadmap will help illustrate your team’s strategic vision to all relevant stakeholders. It gives your team a single, shared source of truth that outlines the direction and progress of a product or team over time to ease cross-team communication and help release more predictably.
Advanced Roadmaps in Jira loads your Jira issues into your plan and suggests releases you can work with, allowing you to track the progress of your releases and determine if they’ll be completed on time.
Tracking releases
You can run a release report in Jira at any time. This report will show you how many total issues there are in the release broken down by how many are in progress or completed.
Jira and feature flags
It is possible to apply feature flags to Jira issues. There, you would be able to monitor your flag’s rollout status from your Jira issue. You would even be able to roll out a feature to a certain subset of users.
Feature flags at their simplest level are if/else statements that allow you to decouple deployment from release giving you more control over the release process so that you can ship changes in code confidently and safely.
Using Jira for feature flags has many advantages, primarily allowing teams full visibility over what features have been released or in the process of being released, all from a single place. Thus, it fosters collaborations so that teams can work together efficiently.
Connecting Jira to feature flags gives your team immediate insight into the status of releases once they are deployed. Teams then would be able to see which feature flag has been turned on and which percentage of users have access to it.
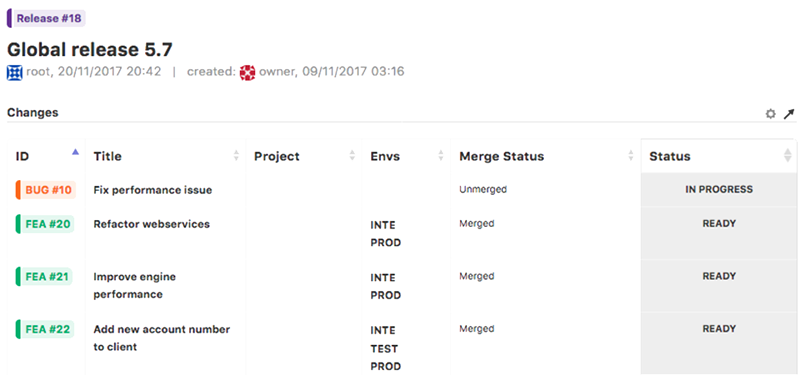
Therefore, you can create a workflow around feature flagging to track the state of each flag. This means that each time a flag is created, an issue in Jira is automatically created and as the flag is rolled out, the issue in Jira automatically moves through the workflow as can be seen in the image below:
Data from Jira issues allows teams to see if there are any bugs in the feature so that they may be immediately fixed before rolling out the feature to the rest of your users.
Additionally, Jira helps reduce technical debt as it enables you to develop rules of governance for feature flags so that your team knows once a flag is rolled out to 100% so that it may be removed from the system.
In other words, whenever a new feature is added to the codebase, you can assign cleanup tickets to engineering or product teams.
Conclusion
The automation capabilities that Jira brings to your releases is essential especially when it comes to managing multiple complex projects.
With feature flags, developers can have even more control over their releases so that they may launch new features quicker than ever before while receiving direct insights from their releases.
Jira as a whole allows you to manage releases according to your unique needs and objectives. It also facilitates an Agile methodology within your organization by creating Agile workflows to help release high quality software faster.
Overall, using releases in Jira significantly improves your tracking and reporting allowing you to have better coordination and planning across your releases.
In this article, we will highlight some release management tools that are essential to the success of your release with heightened velocity. A release manager will need to be familiar with at least some of these tools in order to create automated processes that result in high quality releases.
These tools help to increase speed of software delivery while reducing risk and errors. The following are our top picks to help you deploy faster and more efficiently, some of which are either open source or premium paid tools.
But before we start, here is a quick reminder about what is release management.
Release management process
In our release management guide, we mentioned what release management is, its different phases as well as the different deployment strategies to release new features to production.
As a quick recap, release management basically outlines the different phases involved in the release process of a feature from its inception to its launch. It is the process of planning and controlling software builds throughout its entire life cycle.
As organizations transition from more traditional practices of Waterfall to an Agile methodology, the goal of the release management process is now to move software builds through the various phases quicker and more frequently.
Without further ado, here is the list of our favorite release management tools.
Ansible
Ansible is an open source configuration management and application deployment tool. It has the advantage of being simple and easy to use, hence creating a collaborative environment.
This tool also enhances productivity as it eliminates repetitive tasks so that your team can focus on other more important tasks and strategic work.
Other features:
Comes with an agentless architecture
Allows you to orchestrate your app lifecycle
Doesn’t require any special coding skills
Jenkins
Jenkins is one of the most popular tools currently available. A leading open source automation server, it provides hundreds of plugins to support building, automating and deploying your projects.
This tool is easy to set up and configure and integrates with practically any tool and can be distributed across multiple machines.
Helps organize releases and keep deployments on schedule
Plutora
Plutora, a value stream management platform, improves time-to-value and improves your digital transformation journey by scaling Agile and DevOps across your organization.
The platform also gives you full visibility and control over the release process enhancing productivity and allowing different teams to see what they’re doing.
This transparency over the software delivery process allows you to increase efficiency and reduce time-to-value to deliver better software faster.
Other features:
Increases delivery speed through automation and streamlined processes
Improves collaboration to ensure fast workflows between development and test teams
Provides release insights to make sure high-quality releases are delivered on time
Chef
Chef helps to facilitate a culture of DevSecOps (Development, Security and Operations) by allowing effective collaboration through software automation.
Chef helps teams build, deploy and secure your releases as well as enabling them to scale continuous delivery across different applications.
Other features:
Facilitates cross-team collaboration with actionable insights for configuration
Provides operational visibility for all your teams in one place
Provides a single source of truth for all environments
Clarive
Clarive helps make application delivery easier through a unified workflow. This release management tool drives application changes from development all the way to production.
This tool also allows you to choose a template that fits your organization’s unique workflow and delivery mode.
Other features:
Provides a Kanboard board to create a deployment.
Allows you to track your release progress through the different stages
Provides an end-to-end delivery
Spinnaker
Spinnaker is an open source, multi-cloud continuous delivery platform. Created by Netflix, this platform allows for fast and safe deployments across multiple cloud providers including AWS EC2, Kubernetes and Microsoft Azure.
Its deployment features enable teams to construct and manage continuous delivery workflows.
Other features:
Provides role-based access control so that access can be restricted to projects or accounts leading to heightened security
Allows you to restrict execution of stages to certain times; for example, when the right people are on hand to access the rollout
Requires manual judgements (a manual approval) prior to a release
Ultimately, the release management tool you choose will depend on a number of factors including: company size, amount of projects (i.e. whether you have a large number of simultaneous projects) and ease of use.
In the end, whatever tool you end up choosing, to ensure a smooth release management process, it’s imperative to build consistent workflows and foster an environment of collaboration.
Choosing the right tools will allow teams to efficiently build, manage and deploy new features without much hassle.
Are you on the brink of launching a new feature – one that will affect many of your high-value clients? You’ve worked hard to build it, you’re proud of it and you should be!
You can’t wait to release it for all your users, but wait! What if you’ve missed something? Something that would ruin all your engineering efforts?
There’s nothing worse than starting the day after a release by having to immediately deal with a number of alerts for production issues and spending the day checking a number of logging and monitoring systems for errors and, ultimately, having to rollback the feature you just launched. You would just feel frustrated and unmotivated.
In addition to sapping the morale of your technical teams, NIST has shown that the longer a bug takes to be detected, the more costly it is to fix. This is illustrated by the following graph:
This is explained by the fact that once the feature has been released and is in production, finding bugs is difficult and risky. In addition to preventing users from being affected by problems, it’s critical to ensure service availability.
Are you sure your feature is bug-free?
You might think that this won’t happen to you. That your feature is safe and ready to deploy.
History has shown that it can happen to the biggest companies. Let’s name a few examples.
Facebook, May 7, 2020. An update to Facebook’s SDK rolled out to all users, missed a bug: a server value that was supposed to provide a dictionary of things was changed to provide a simple YES/NO instead. This really tiny change was enough to break Facebook’s authentication system and affect tons of other apps like TikTok, Spotify, Pinterest, Venmo, and other apps that didn’t even use Facebook’s authentication system as it is extremely common for apps to connect to Facebook regardless of whether they use a Facebook-related feature, mainly for ad attribution. The result was unequivocal, the app simply crashed right after launch. Facebook fixed the problem in a hurry, with about two hours for things to get back to normal. But do you have the same resources as Facebook?
Apple, September 19, 2012. Another good example, even though it’s a bit older, would be the replacement of Google Maps with Apple Maps in iOS 6 in 2012 on iOS devices. For many customers and especially fans, Apple always handles the rollout of new features carefully, but this time they messed up. Apple didn’t want to be tied to Google’s app anymore, so they made their own version. However, in their rush to release their map system, Apple made some unforgivable navigational mistakes. Among the many failures of Apple Maps are erased cities, disappearing buildings, flattened landmarks, duplicate islands, distorted graphics, and erroneous location data. A large part of this mess could have been avoided if they had deployed their new map application progressively. They would have been able to spot the bugs and quickly fix them before massive deployment.
And now, thinking about this and seeing that even big companies are impacted, you’re stressed out and may not even want to release it anymore.
But don’t worry! At AB Tasty, we know that building a feature is only half of the story and that to be truly effective, that feature has to be well deployed.
Our feature management service has you covered. You’ll find a set of useful features, such as progressive rollout, to free you from the fear of a release catastrophe and erase feature management frictions, so that you can focus on value-added tasks to get high-quality features into production and apply your energy and innovation in the best way possible, thereby delivering maximum value to your customers.
What’s progressive rollout?
So now you’re curious: what’s progressive rollout? How will this help me monitor the release and make sure everything is okay?
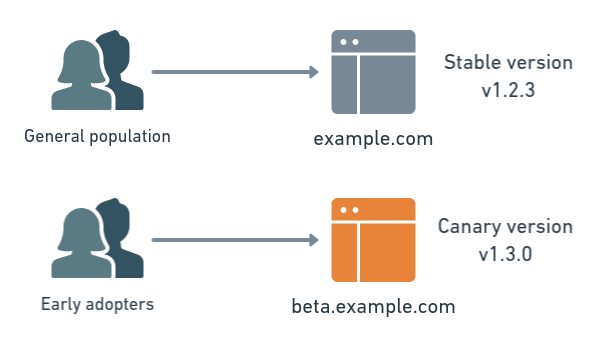
A progressive rollout approach lets you test the waters of a new version with a restricted set of clients. You can set percentages of users to whom your feature will be released and gradually update the percentage to safely deploy your feature. You can also do a canary launch by manually targeting several groups of people at various stages of your rollout.
This is a practice already used by large companies that have realized the significant benefits of a progressive rollout.
Netflix, for example, is one of the most dynamic companies and its developers are constantly releasing updates and new software, but users rarely experience downtime and encounter very few bugs or issues. The company is able to deliver such a smooth experience thanks to sophisticated deployment strategies, such as Canary deployment and progressive deployment, multiple staging environments, blue/green deployments, traffic splitting, and easy rollbacks to help development teams release software changes with confidence that nothing will break.
Disney is another good example of a company that makes the most of progressive deployment. It has taken the phased deployment approach to a whole new level for its “Disney +” and “Star” streaming services by deploying them regionally rather than globally. This delivery method is driven by the needs of the business. The company is making sure that everything is ready at the regional level, in line with its focus on the most important markets. Prior to launching Disney+ in Europe, it spent a lot of time building the local infrastructure needed to deliver a high-quality experience to consumers when launching Disney+ in Europe, including establishing local colocation facilities and beefing up data centers to cache content regionally. After starting to roll it out in Europe, Disney was able to identify that, for some markets, the launch of Disney+ could actually create issues that would have resulted in latency and thus provide a poor experience for affected users. So they took proactive steps to reduce their overall bandwidth usage by at least 25% prior to their march 24 launch and delayed their launch in France by two weeks. Without progressive deployment, they wouldn’t have been able to identify these issues. And that’s why the launching of Disney + was remarkable.
What are the benefits of the progressive rollout?
There are three main benefits to the progressive rollout approach.
Avoiding bugs impacting everyone in production at once
First, by slowly ramping up the load, you can monitor and capture metrics about how the new feature impacts the production environment. If any unanticipated issues come to light, you can pause the full launch, fix the issues, and then smoothly move ahead. This data-driven approach guarantees a release with maximum safety and measurable KPIs.
Validating the “Viable part” in your MVP
You can effectively measure how well your feature is welcomed by your users. If you launch a new feature to 10% of your client base and notice revenue or engagement taking a dip, you can pause the release and investigate. The other major advantage? Anticipating costs. Since margin, profit and revenue are an important part of sustainability, unexpected costs that blow up your projected budgets at the end of the month are almost as bad as the night sweats that come from an unexpected bug! Monitoring your costs during a progressive rollout and immediately pausing the launch if those costs spike is a phenomenal level of control that you will absolutely want to get in on.
Progressively deploying services based upon business drivers
Finally, deploying a service or product progressively can also be seen as a way of prioritizing specific markets based on data-driven business plans. Disney, for example, decided not to launch the service in the U.S. when it launched “Star,” its new channel available in the Disney+ catalog for international audiences, which will feature more mature R-rated movies, FX TV shows, and other shows and movies that Disney owns the rights to but that do not fit the Disney+ family image. Ironically: U.S. customers will have to pay extra on their Disney+ subscription to access the same content on the other streaming service, Hulu.
The decision was made following a complex matrix of rights agreements and revenue streams. Disney found that subscribers are willing to pay for the separate Hulu and Disney+ libraries in the U.S., but that Star’s more limited lineup was enough to justify a standalone paid purchase for international customers, who will have to add $2 to their initial $6.99 subscription to access it. When the content library for Star is enough to justify not going through Hulu anymore, the U.S. customers will have access to it by paying just 1$ more. This progressive rollout approach has enabled Disney to make sure that once they launch Star in the U.S., everything will be ready and they will achieve good results.
In other words, the progressive rollout approach helps you ensure that your functionality meets the criteria of usability, viability, and desirability in accordance with your business plan.
How to act fast when you identify bugs while progressively deploying a feature?
Now that you know more about the progressive rollout of your features/products, you may be wondering how to take action if you identify bugs or if things aren’t going well. Lucky for you, we’ve thought of that part too. In addition to progressive rollout, you’ll also find automatic rollback on KPIs and feature flagging in the AB Tasty toolkit.
Feature flagging will let you set up flags on your feature, that work as simply as a switch on/off button. If for any reason you identify threats in your rollout or if the engagement of your users is not really convincing, you can simply toggle your feature off and take time to fix any issues.
This implies that you are aware and that someone from the product team is available to turn it off. But what if something happens overnight and no one can check on the progress of the deployment? Well, for that eventuality, you can set up automatic rollbacks (also called Rollback Threshold) linked to key performance indicators. Our algorithm will check the performance of your deployment and, based on the KPIs you set, if something goes wrong, it will automatically roll back the deployment and inform you that a problem has occurred. This way, in the morning, your engineers will be able to fix the problems without having to deal with the rollback themselves.
Conclusion
Downtime incidents are stressful for both you and your customers. To resolve them quickly and efficiently, you need to have access to the right tools and make the most of them. The progressive rollout, automatic rollback, and feature flagging are great levers to relieve your product teams of stress and let them focus on innovating your product to create a wonderful experience for your users. Highly effective organizations have already realized the importance of having the right approach to deployment with the right tools. What about your organization?
AB Tasty minimizes risk and maximizes results to make the lives of Product teams a whole lot easier. Create a free account today!
One of the most critical metrics in DevOps is the speed with which you deliver new features. Aligning developers, ops teams, and support staff together, they quickly get new software into production that generates value sooner and can often be the deciding factor in whether your company gains an edge on the competition.
Quick delivery also shortens the time between software development and user feedback, which is essential for teams practicing CI/CD.
One practice you should consider adding to your CI/CD toolkit is the blue-green deployment. This process helps reduce both technical and business risks associated with software releases.
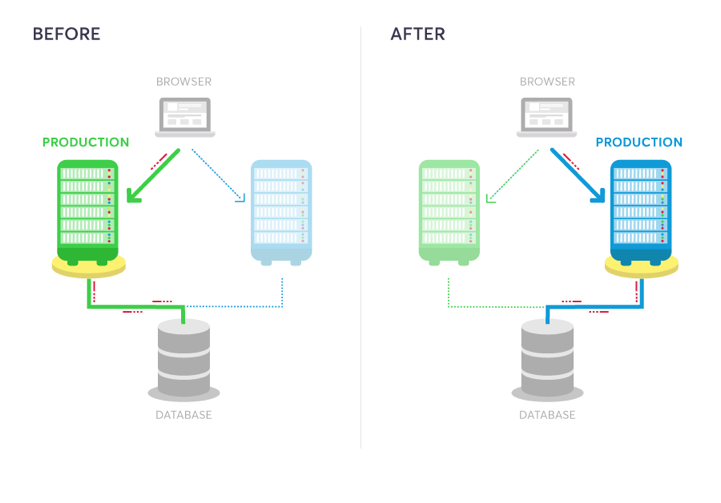
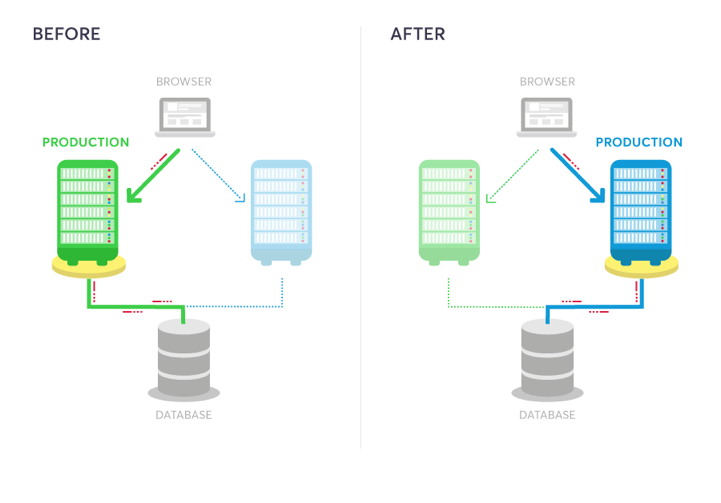
In this model, two identical production environments nicknamed “blue” and “green” are running side-by-side, but only one is live, receiving user transactions. The other is up but idle.
In this article, we’ll go over how blue-green deployments work. We’ll discuss the pros and cons of using this approach to release software. We’ll also compare how they stack up against other deployment methodologies and give you some of our recommended best practices for ensuring your blue-green deployments go smoothly.
[toc]
How do blue-green deployments work?
One of the most challenging steps in a deployment process is the cutover from testing to production. It must happen quickly and smoothly to minimize downtime.
A blue-green deployment methodology addresses this challenge by utilizing two parallel production environments. At any given time, only one of them is the live environment receiving user transactions. In the image below, that would be green. The blue idle system is a near-identical copy.
Your team will use the idle blue system as your test or staging environment to conduct the final round of testing when preparing to release a new feature. Once the new software is working correctly on blue, your ops team can switch routing to make blue the live system. You can then implement the feature on green, which is now idle, to get both systems resynchronized.
Generally speaking, that is all there is to a blue-green deployment. You have a great deal of flexibility in how the parallel systems and cut-overs are structured. For example, you might not want to maintain parallel databases, in which case all you will change is routing to web and app servers. For another project, you may use a blue-green deployment to release an untested feature on the live system, but set it behind a feature flag for A/B user testing.
Example
Let’s say you’re in charge of the DevOps team at a niche e-commerce company. You sell clothing and accessories popular in a small but high-value market. On your site, customers can customize and order products on-demand.
Your site’s backend consists of many microservices in a few different containers. You have microservices for inventory management, order management, customization apps, and a built-in social network to support your customers’ niche community.
Your team will release early and often as you credit your CI/CD model for your continued popularity. But this niche community is global, so your site sees fairly steady traffic throughout any given day. Finding a lull in which to update your production system is always tricky.
When one of your teams announces that their updated customization interface is ready for final testing in production, you decide to release it using a blue-green deployment so it can go out right away.
Animation of load balancer adjusting traffic from blue to green (Source)
The next day before lunch, your team decides they’re ready to launch the new customizer. At that moment, all traffic routes to your blue production system. You update the software on your idle green system and ask testers to put it through Q/A. Everything looks good, so your ops team uses a load balancer to redirect user sessions from blue to green.
Once traffic is completely filtered over to green, you make it the official production environment and set blue to idle. Your dev team pushes the updated customizer code to blue, puts in their lunch order, and takes a look at your backlog.
Pros: Benefits & use cases
One of the primary advantages of blue-green deployments over other software release strategies is how flexible they are. They can be beneficial in a wide range of environments and many use cases.
Rapid releasing
For product owners working within CI/CD frameworks, blue-green deployments are an excellent method to get your software into production. You can release software practically any time. You don’t need to schedule a weekend or off-hours release because, in most cases, all that is necessary to go live is a routing change. Because there is no associated downtime, these deployments have no negative impact on users.
They’re less disruptive for DevOps teams too. They don’t need to rush updates during a set outage window, leading to deployment errors and unnecessary stress. Executive teams will be happier too. They won’t have to watch the clock during downtime, tallying up lost revenue.
Simple rollbacks
The reverse process is equally fast. Because blue-green deployments utilize two parallel production environments, you can quickly flip back to the stable one should any issues arise in your live environment.
This reduces the risks inherent in experimenting in production. Your team can easily remove any issues with a simple routing change back to the stable production environment. There is a risk of losing user transactions cutting back—which we’ll get into a little further down—but many strategies for managing that situation are available.
You can temporarily set your app to be read-only during cutovers. Or you could do rolling cutovers with a load balancer while you wait for transactions to complete in the live environment.
Built-in disaster recovery
Because blue-green deployments use two production environments, they implicitly offer disaster recovery for your business systems. A dual production environment is its own hot backup.
Load balancing
Blue-green parallel production environments also make load balancing easy. When the two environments are functionally identical, you can use a load balancer or feature toggle in your software to route traffic to different environments as needed.
Easier A/B testing
Another use case for parallel production environments is A/B testing. You can load new features onto your idle environment and then split traffic with a feature toggle between your blue and green systems.
Collect data from those split user sessions, monitor your KPIs, and then, if analyses of the new feature look good in your management system, you can flip traffic over to the updated environment.
Cons: Challenges to be aware of
Blue-green deployments offer a great deal of value, but integrating the infrastructure and practices required to carry them out creates challenges for DevOps teams. Before integrating blue-green deployments into your CI/CD pipeline, it is worth understanding these challenges.
Resource-intensive
As is evident by now, to perform a blue-green deployment, you will need to resource and maintain two production environments. The costs of this, in money and sysadmin time, might be too high for some organizations.
For others, they may only be able to commit such resources for their highest value products. If that is the case, does the DevOps team release software in a CI/CD model for some products but not others? That may not be sustainable.
Extra database management
Managing your database—or multiple databases—when you have parallel production environments can be complicated. You need to account for anything downstream of the software update you’re making needs in both your blue and green environments, such as any external services you’re invoking.
For example, what if your feature change requires you to rename a database column? As soon as you change the name to blue, the green environment with old code won’t function with that database anymore.
Can your entire production environment even function with two separate databases? That’s often not the case if you’re using your blue and green systems for load balancing, testing, or any function other than as a hot backup.
A blue-green deployment diagram with a single database (Source)
Product management
Aside from system administration, managing a product that runs on two near-identical environments also requires more resources. Product Managers need reliable tools for tracking how their software is performing, which services different teams are updating, and ways to monitor the KPIs associated with each. A reliable product and feature management dashboard to monitor and coordinate all of these activities becomes essential.
Blue-green deployments vs. rolling deployments
Blue-green deployments are, of course, not the only option for performing rapid software releases. Another popular approach is to conduct a rolling deployment.
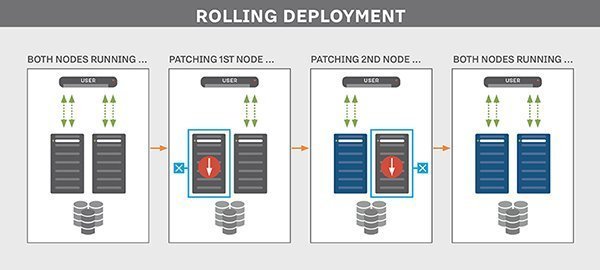
Rolling deployments also require a production environment that consists of multiple servers hosting an application, often, but not always, with a load balancer in front of them for routing traffic. When the DevOps team is ready to update their application, they configure a staggered release, pushing to one server after another.
While the release is rolling out, some live servers will be running the updated application, while others have the older version. This contrasts with a blue-green deployment, where the updated software is either live or not for all users.
As users initiate sessions with the application, they might either reach the old copy of the app or the new one, depending on how the load balancer routes them. When the rollout is complete, every new user session that comes in will reach the software’s updated version. If an error occurs during rollout, the DevOps team can halt updates and route all traffic to the remaining known-good servers until they resolve the error.
Rolling deployments are a viable option for organizations with the resources to host such a large production environment. For those organizations, they are an effective method for releasing small, gradual updates, as you would in agile development methodologies.
There are other use cases where blue-green deployments may be a better fit. For example, if you’re making a significant update where you don’t want any users to access the old version of your software, you would want to take an “all or nothing” approach, like a blue-green deployment.
Suppose your application requires a high degree of technical or customer support. In that case, the support burden is magnified during rolling deployment windows when support staff can’t tell which version of an application users are running.
Blue-green deployments vs. canary releasing
Rolling and blue-green deployments aren’t the only release strategies out there. Canary deployments are another alternative. At first, only a subset of all production environments receives a software update in a canary release. But instead of continuing to roll deploy to the rest, this partial release is held in place for testing purposes. A subset of users is then directed to the new software by a load balancer or a feature flag.
Canary releasing makes sense when you want to collect data and feedback from an identifiable set of users about updated software. Practicing canary releases dovetails nicely with broader rolling deployments, as you can gradually roll the updated software out to larger and larger segments of your user base until you’ve finished updating all production servers.
Best practices
You have many options for releasing software quickly. If you’re considering blue-green deployments as your new software release strategy, we recommend you adopt some of these best practices.
Automate as much as possible
Scripting and automating as much of the release process as possible has many benefits. Not only will the cutover happen faster, but there’s less room for human error. A dev can’t accidentally forget a checklist item if a script or a management platform handles the checklist. If everything is packaged in a script, then any developer or non-developer can carry out the deployment. You don’t need to wait for your system expert to get back to the office.
Monitor your systems
Always make sure to monitor both blue and green environments. For a blue-green deployment to go smoothly, you need to know what is going on in both your live and idle systems.
Both systems will likely need the same set ofmonitoring alerts, but set to different priorities. For example, you’ll want to know the second there is an error in your live system. But the same error in the idle system may need to be addressed sometime that business day.
In some cases, new and old versions of your software won’t be able to run simultaneously during a cutover. For example, if you need to alter your database schema, it would help if you structured your updates so that both blue and green systems will be functional throughout the cutover.
One way to handle these situations is to break your releases down into a series of even smaller release packages. Let’s say our e-commerce company is deepening its inventory and needs to update its database by changing a field name from “shirt” to “longsleeve_shirt” for clarity.
They might break this update down by:
Releasing a feature flag-enabled intermediary version of their code that can interpret results from both “shirt” and “longsleeve_shirt”;
Running a rename migration across their entire database to rename the field;
Releasing the final version of the code—or flip their feature flag—so the software only uses “longsleeve_shirt.”
Do more, smaller deployments
Smaller, more frequent updates are already an integral practice in agile development and CI/CD. It is even more important to follow this practice if you’re going to conduct blue-green deployments. Reducing deployment times shortens feedback loops, informing the next release, making each incremental upgrade more effective and more valuable for your organization.
Restructure your applications into microservices
This approach goes hand-in-hand with conducting smaller deployments. Restructuring application code into sets of microservices allows you to manage updates and changes more easily. Different features are compartmentalized in a way that makes them easier to update in isolation.
Use feature flags to reduce risk further
By themselves, blue-green deployments create a single, short window of risk. You’re updating everything, all-or-nothing, but you can cut back if needed should an issue arise.
Blue-green deployments also have a pretty consistent amount of administrative overhead that comes with each cutover. You can reduce this overhead through automation, but still, you’re going to follow the same process no matter whether you’re updating a single line of code or you’re overhauling your entire e-commerce suite.
Those conditions can be simple “yes/no” checks, or they can be complex decision trees. Feature flags help make software releases more manageable by controlling what is turned on or off at a feature-by-feature level.
For example, our e-commerce company can perform a blue-green deployment of their customizer microservice but leave the new code turned off behind a feature flag in the live system. Then, the DevOps team can turn on that feature according to whatever condition they wish, whenever it is convenient.
The team might want to do some further A/B testing in production. Or maybe they want to conduct some further fitness tests. Or it might make more sense for the team to do a canary release of the customizer for an identified set of early adopters.
Your feature flags can work in conjunction with a load balancer to manage which users see which application and feature subsets while performing a blue-green deployment. Instead of switching over entire applications all at once, you can cut over to the new application and then gradually turn individual features on and off on the live and idle systems until you’ve completely upgraded. This gradual process reduces risk and helps you track down any bugs as individual features go live one-by-one.
You can manually control feature flags in your codebase, or you can use feature flag services for more robust control. These platforms offer detailed reporting and KPI tracking along with a deep set of DevOps management tools.
We recommend using feature flags in any major application release when you’re doing a blue-green deployment. They’re valuable even in smaller deployments where you’re not necessarily switching environments. You can enable features gradually one at a time on blue, leaving green on standby as a hot backup if a major problem arises. Combining feature flags with blue-green deployments is an excellent way to perform continuous delivery at any scale.
Consider adding blue-green deployments to your DevOps arsenal
Blue-green deployments are an excellent method for managing software releases of any size, no matter whether they’re a whole application, major updates, a single microservice, or a small feature update.
It is essential to consider how well blue-green deployments will integrate into your existing delivery process before adopting them. This article detailed how blue-green deployments work, the pros and cons of using them in your delivery process, and how they stack up against other possible deployment methods. You should now have a better sense of whether blue-green deployments might be a viable option for your organization.
Picking an effective deployment strategy is an important decision for every DevOps team. Many options exist, and you want to find the strategy that best aligns with how you work. Today, we’ll go over canary deployments.
Are you an agile organization? Are you performing continuous integration and continuous delivery (CI/CD)? Are you developing a web app? Mobile app? Local desktop or cloud-based app? These factors, and many others, will determine how effective any given deployment strategy will be.
But no matter which strategy you use, remember that deployment issues will be inevitable. A merge may go wrong, bugs may appear, human error may cause a problem in production. The point is, don’t wear yourself out trying to find a deployment strategy that will be perfect. That strategy doesn’t exist.
Instead, try to find a strategy that is highly resilient and adaptive to the way you work. Instead of trying to prevent inevitable errors, deploy code in a way that minimizes errors and allows you to respond when they do occur quickly.
Canary deployments can help you put your best code into production as efficiently as possible. In this article, we’ll go over what they are and what they aren’t. We’ll go over the pros and cons, compare them to other deployment strategies, and show you how you can easily begin performing such deployments with your team.
In this article, we’ll go over:
[toc]
What is a canary deployment?
Canary deployments are a best practice for teams who’ve adopted a continuous delivery process. With this strategy, a new feature is first made available to a small subset of users. The new feature is monitored for several minutes to several hours, depending on the traffic volume, or just long enough to collect meaningful data. If the team identifies an issue, the new feature is quickly pulled. If no problems are found, the feature is made available to the entire user base.
The term “canary deployment” has a fascinating history. It comes from the phrase “canary in a coal mine,” which refers to the historical use of canaries and other small songbirds as living early-warning systems in mines. Miners would bring caged birds with them underground. If the birds fell ill or died, it was a warning that odorless toxic gases, like carbon monoxide, were present. While inhumane, it was an effective process used in Britain and the US until 1986, when electronic sensors replaced canaries.
A canary deployment turns a subset of your users —ideally a bug-tolerant subset— into your own early warning system. That user group identifies bugs, broken features, and unintuitive features before your software gets wider exposure.
Your canary users could be self-identified early adopters, a demographically targeted segment, or a random sampling. Whichever mix of users makes the most sense for verifying your new feature in production.
One helpful way to think about canary deployments is risk management. You are free to push new, exciting features more regularly without having to worry that any one new feature will harm the experience of your entire user base.
Canary releases vs. canary deployments
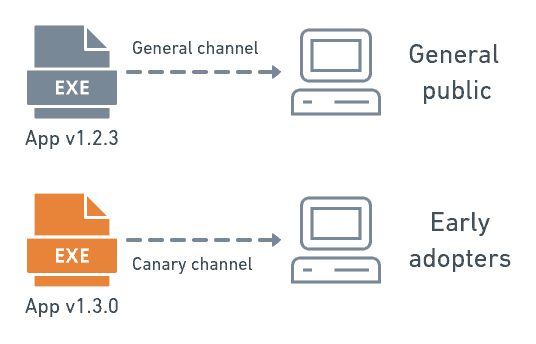
The phrases “canary release” and “canary deployment” are sometimes used interchangeably, but in DevOps, they really should be thought of as separate. A canary release is a test build of a complete application. It could be a nightly release or a beta, for example.
Teams will often distribute canary releases hoping that early adopters and power users, who are more familiar with development processes, will download the new application for real-world testing. The browser teams at Mozilla and Google, and many other open-source projects, are fond of this release strategy.
On the other hand, canary deployments are what we described earlier. A team will release new features into production with early adopters or different user subsets, routed to the new software by a load balancer or feature flag. Most of the user base still sees the current, stable software.
Canary deployment pros and cons
Canary deployments can be a powerful and effective release strategy. But they’re not the correct strategy in every possible scenario. Let’s run through some of the pros and cons so you can better determine whether they make sense for your DevOps team.
Pros
Support for CI/CD processes
Canary deployments shorten feedback loops on new features delivered to production. DevOps teams get real-world usage data faster, which allows them to refine and integrate the next round of features faster and more effectively. Shorter development loops like this are one of the hallmarks of continuous integration/continuous delivery processes.
Granular control over feature deployments
If your team conducts smaller, regular feature deployments, you reduce the risk of errors disrupting your workflow. If you catch a mistake in the deployment, you won’t have exposed many users to it, and it will be a minor matter to resolve. You won’t have exposed your entire user population and needed to pull colleagues off planned work to fix a major production issue.
Real-world testing
Internal testing has its place, but it is no substitute for putting your application in front of real-world users. Canary deployments are an excellent strategy for conducting small-scale real-world testing without imposing the significant risks of pushing an entirely new application to production.
Quickly improve engagement
Besides offering better technical testing, canary deployments allow you to quickly see how users engage with your new features. Are session lengths increasing? Are engagement metrics rising in the canary? If no bugs are found, get that feature in front of everyone.
There is no need to wait for a more extensive test deployment to complete. Engage those users and get iterating on your next feature.
More data to make business cases
Developers may see the value in their code, but DevOps teams still need to make business cases to leadership and the broader organization when they need more resources.
Canary deployments can quickly show you what demand might be for new features. Conduct a deployment for a compelling new feature on a small group of influencer users to get them talking. Use engagement and publicity metrics to make the case why you want to push a major new initiative tied to that feature.
Stronger risk management
Canary deployments are effectively a series of microtests. Rolling out new features incrementally and verifying them one at a time with canary testing can significantly reduce the total cost of errors or more significant system issues. You’ll never need to roll back a major release, suffer a PR hit, and need to rework a large and unwieldy codebase.
Cons
More overhead
Like any complex process, canary deployments come with some downsides. If you’re going to use a load balancer to partition users, you will need additional infrastructure and need to take on some additional administration.
In this scenario, you create a second production environment and backend that will run alongside your primary environment. You will have two codebases, two app servers, potentially two web servers, and networking infrastructure to maintain.
Alternatively, many DevOps teams use feature flags to manage their canary deployments on a single system. A feature flag can partition users into a canary test at runtime within a single code base. Canary users see the new feature, and everyone else runs the existing code.
Deploying local applications is hard
If you’re developing a locally installed application, you run the risk of users needing to initiate a manual update to get the latest version of your software. If your canary deployment sits in that latest update, your new feature may not get installed on as many client systems as you need to get good test results.
In other words, the more your software runs client-side, the less amenable it is to canary deployments. A full canary release might be a more suitable approach to get real-world test results in this scenario.
Users are still exposed to software issues
While the whole point of a canary deployment is to expose only a few users to a new feature to spare the broader user base, you will still expose end users to less-tested code. If the fallout from even a few users encountering a problem with a particular feature is too significant, then consider skipping this kind of deployment in favor of more rigorous internal testing.
How to perform a canary deployment
Planning out a canary deployment takes a few simple steps:
Identify your canary group
There are several different ways you can select a user group to be your canary.
Random subset
Pick a truly random sampling of different users. While you can do this with a load balancer, feature flag management software can easily route a certain percentage of total traffic to a canary test using a simple modulo.
Early adopters
If you run an early adopter program for highly engaged users, consider using them as your canary group. Make it a perk of their program. In exchange for tolerating bugs they might encounter in a canary deployment, you can offer them loyalty rewards.
By region
You might want to assign a specific region to be your canary. For example, you could set European IPs during late evening hours to go to your canary deployment. You would avoid exposing daytime users to your new features but still get a handful of off-hours user sessions to use as a test.
Internal testers
You can always configure sessions from your internal subnets to be the canary.
Decide on your canary metrics
The purpose of conducting a canary deployment is to get a firm “yes” or “no” answer to the question of whether your feature is safe to push into wider production. To answer that question, you first need to decide what metrics you’re going to use and install the means for monitoring performance.
For example, you may decide you want to monitor:
Internal error counts
CPU utilization
Memory utilization
Latency
You can customize feature management software quickly and easily to monitor performance analytics. These platforms can be excellent tools for encouraging a culture of experimentation.
Decide how to transition from canary to full deployment
As discussed, canary releases should only last on the order of several minutes to several hours. They are not intended to be overly long experiments. Because the timeframe is so short, your team should decide up front how many users or sessions you want in the canary and how you’re going to move to full deployment once your metrics hit positive benchmarks.
For example, you could go with a 5/95 random canary deployment. Configure a feature flag to move a random 5 percent of your users to the canary test while the remaining 95 percent stay on the stable production release. If you see positive results, remove the flag and deploy the feature completely.
Or you might want to take a more conservative approach. Another popular canary strategy is to deploy a canary test logarithmically, going from a 1 percent random sample to 10 percent to see how the new feature stands up to a larger load, then up to a full 100 percent.
Determine what infrastructure you need
Once your team is on the same page about the approach you’ll take, you’ll need to make sure you have all the proper infrastructure in place to make your canary deployment go off without a hitch.
You need a system for partitioning the user base and for monitoring performance. You can use a router or load balancer for the partitioning, but you can also do it right in your code with a feature flag. Feature flags are often more cost-effective and quick to set up, and they can be the more powerful solution.
Canary vs. blue/green deployments
Canary deployments are also sometimes confused with blue/green deployments. Both can use parallel production environments —managed with a load balancer or feature flag— to mitigate the risk of software issues.
In a blue/green deployment, those environments start identical, but only one receives traffic (the blue server). Your team releases a new feature onto the hot backup environment (the green server). Then the router, feature flag, or however you’re managing traffic, gradually shifts new user sessions from blue to green until 100 percent of all traffic goes to green. Once the cutover is complete, the team updates the now-old blue server with the new feature, and then it becomes the hot backup environment.
The way the switchover is handled in these two strategies differs because of the desired outcome. Blue/green deployments are used to eliminate downtime. Canary deployments are used to test a new feature in a production environment with minimal risk and are much more targeted.
Use feature flags for better deployments
When you boil it right down, a feature flag is nothing more than an “if” statement from which users take different code paths at runtime depending on a condition or conditions you set. In a canary deployment, that condition is whether the user is in the canary group or not.
Let’s say we’re running a fledgling social networking site for esports fans. Our DevOps team has been hard at work on a content recommender that gives users real-time recommendations based on livestreams they’re watching. The team has refined the recommendation feature to be significantly faster. It has performed well in internal testing, and now they want to see how it performs under real-world conditions.
The team doesn’t want to invest time and money into installing new physical infrastructure to conduct a canary deployment. Instead, the team decides to use a feature flag to expose the new recommendation engine to a random 5 percent sample of the user base.
The feature flag splits users into two groups with a simple modulo when users load a live stream. Within minutes your team gets results back from a few thousand user sessions with the new code. It does, in fact, load faster and improves user engagement, but there is an unanticipated spike in CPU utilization on the production server. Ops staff realize it is about to degrade performance, so they kill the canary flag.
The team agrees not to proceed with rollout until they can debug why the new code caused the unexpected server CPU spike. Thanks to the real-world test results provided by the canary deployment, they have a pretty good idea of what was going on and get back to work.
Features flags streamline and simplify canary deployments. They mitigate the need for a second production environment. Using feature flag management software like AB Tasty allows sophisticated testing and analysis.
Everyone hates tests. Ever since our school days, just hearing the word ‘test’ puts us on high alert and brings nothing but dread.
It seems we cannot escape the word even in software development. And it’s not just any test but a ‘test in production’.
Yes, it is the dreaded phrase that leaves you sweating and your heart pounding. Just reading the phrase may make you envision apocalyptic images of the inevitable disaster that could occur in its wake…
“Test in production” they said. “What could go wrong.” they said
We, too, hate tests but even we have to admit that testing in production is a pretty big deal now. Let us tell you why before you run away in horror…
I don’t always test my code. But when I do, I do it in production.
If it helps, think of it more as an essential part of your software development process and less as an actual ‘test’ where the only two options are pass or fail but for the sake of consistency and clarity, we’ll refer to it here as testing in production and who knows? Maybe by the end of this article, it won’t be so scary anymore!
There is no TEST. PRODUCTION only there is.
So here’s the low-down…
First things first, what is testing in production? Testing in production is when you test new code changes on live users rather than a staging or testing environment.
It may sound downright terrifying when you think about it. So what? You have a feature that is brand new and you’re supposed to unleash it to the wild just like that?
Let us break it down for you with the help of our finest selection of memes about test in production…
At this point, you’re probably vehemently shaking your head. The risks are simply too high for you to consider, especially in this day and age of fickle customers who might leave you at the drop of a hat if you make any simple mistake.
I see you test your code in production. I too like to live dangerously.
You may have a well-established product and you cannot risk upsetting your customers, especially your most loyal customers, and damaging your well-crafted reputation by releasing a potentially buggy feature.
Or you might even just be starting out and you simply cannot afford to make any amateur mistakes.
One does not simply test in production!
Why, oh why, should I test in production?
We’re here to tell you that you should absolutely test in production and here’s your answer as to why:
Testing in production allows you to generate feedback from your most relevant users so that you can adjust and improve your releases accordingly. This means that the end-result is a high-quality product that your customers are satisfied with.
There are no finer QA testers than the clients themselves
Additionally, when you test in production, you have the opportunity to test your ideas and even uncover new features that you had not considered before. Plus, it’s not just engineers who get to do this but your product teams can test out their ideas leading to increased productivity.
I’m just a project manager but sure, I’ll do QA
So now you’re thinking, great but there’s still the issue of it all leading to disaster and disgruntled customers.
But really, it’s not as terrifying as it sounds.
Stand back, we’re trying this in production
Wrap up in a feature flag
When you use feature flags while testing in production, you can expose your new features to a certain segment of your users. That way, not everyone will see your feature and in case anything goes wrong, you can roll back the feature with a kill switch.
What if I told you, you could have both speed and safety
Therefore, you have a quick, easy, and low-risk way to roll out your features and roll back any buggy features to fix them before releasing them to everybody else, lessening any negative impact on your user base if any issues arise.
Be the king (or queen) of your software development jungle
With feature flags, you are invincible. You are in complete control of your releases. All you need to do is wrap up your features in a feature flag and you can toggle them on and off like a light switch!
Gave that switch a flick. Switches love flicks
Still confused? Still feeling a bit wary? If you want to find out more about testing in production, read our blog article and let us show you why it’s very much a relevant process and a growing trend that you need to capitalize on today.
We’ll do it live
With AB Tasty’s flagging functionality, it’s easier than ever to manage testing in production. All you need to do is sit back and reap the benefits.
When it comes to feature testing, you’re in a bind.
On the one hand, you need real-world data and feedback from real-world users. You know that every new feature you develop is, at best, an educated guess about what your real-world users want from you. No matter how educated that guess might be, and no matter much internal validation you perform, you can only generate meaningful data and feedback on each new feature you develop by releasing it to real-world users to test out in their real-world environments.
On the other hand, it’s risky to give real-world users an unproven feature. You know that every new feature you release might have something wrong with it. Maybe there’s a technical issue you missed during development. Maybe it just doesn’t align to user expectations as closely as you hoped. No matter the issue, releasing an unproven feature can cause real harm to your brand’s user relationships.
This is a tricky problem and one that is never going to be fully solved. But, thankfully, there are methods you can follow to minimize the problem, and collect real-world data and feedback while mitigating the impact when something (inevitably) goes wrong.
In this piece, we’ll explore one of these methods— rollbacks.
What is a Feature Rollback?
It’s a simple practice, with powerful implications.
When you perform a rollback, you take some code out of a live environment. Back in the day rollbacks could be truly massive. Software products used to be updated in giant new releases that could include a wide range of changes— including multiple new features and significant changes to existing features. If one of these huge releases had some fatal bugs in it, or just wasn’t well-received by users, then the entire thing might need to be rolled back (even if the issues were contained within just a few elements of the release).
All of this has changed with the adoption of Agile methodology. Releases keep getting smaller and more incremental, and so do rollbacks. Most modern Product Managers have adopted phased release plans, where they only release a single new or upgraded feature at a time— and often only to individual segments. And when modern Product Managers do release multiple new or upgraded features at once, the different features are separate from each other.
This evolution has changed the way rollbacks happen. After a new release, Product Managers can now isolate the individual feature(s) that have proven unfit for live usage and perform a targeted rollback on them, and them alone. The whole rollback process is now much faster, much nimbler, much more precise— and delivers much greater benefits.
Why Should Product Managers Perform Rollbacks?
When a Product Manager properly structures and deploys rollbacks, they improve their ability to test new features in a real-world environment with real-world users with a minimal level of risk. An imperfect feature is no longer the end of the world. If a feature has development issues or poor alignment with user requirements, you can perform a rollback and remove it from a live environment in real-time with just one click.
For Product Managers, this changes the game. The more mature your rollback capability, the more you can afford to make mistakes. Your risk shrinks, giving you the freedom to test more features with more users earlier in the development cycle, ultimately leading you to iterate your products faster and faster.
Now, rollbacks are not a silver bullet. They don’t absolve you from doing everything you can to develop the highest-quality features possible before you test them. But rollbacks allow you to test new features with greater confidence and reduced concerns about creating problems for your users.
When Should You Perform a Rollback? Two Common Use Cases
For most Product Managers, there are two common use cases why you might need to perform a rollback.
Rollback Use Case 1: Your Feature has a Bug
This first use case is pretty self-explanatory.
You might have the most robust and thorough QA and testing processes in the world. It’s still highly likely your new features will still have one or more bugs in them when you release them into a live environment. Maybe they’re issues you just didn’t think to search for or didn’t know how to search. Maybe they’re issues that only show up in live environment after hundreds of real-world users tool around with the feature.
Regardless of the reason, if significant technical issues pop up in your new feature, then you’ll likely want to perform a rollback on that feature to fix it. With the right rollback process, you can react to these errors in near-real-time and remove the feature—and maybe even fix it—in minutes before it impacts too many users.
Rollback Use Case 2: Your Feature is Poorly Received
This second use case is a little more sophisticated.
Essentially, after you release a new feature you monitor how users respond to it, and how well it’s hitting your business KPIs. If your new feature is not performing as expected, and is generating negative usage data and user feedback, then you can perform a rollback to remove it from its live environment. If it isn’t hitting—or at least tracking towards—its business goals, then it might not be worth keeping live.
After you roll back your feature, you can either utilize the data and feedback you collected to fix the feature and help it better align to user expectations and business requirements, or you can decide that the feature was fundamentally misguided and just needs to be retired.
With the right rollback process, you can also review and respond to the usage data and user feedback you receive in near-real-time, and prevent too many users from getting too disgruntled about receiving a feature that misses the mark.
What Do These Two Use Cases Have in Common?
In one word: speed.
In both use cases, rollbacks are most effective—and mitigate the most risk—when you are able to first monitor feature performance in real-time, to then translate that performance into a quick “yes/no” decision to rollback (or not), and finally to execute on that rollback decision as rapidly as possible.
The faster you can go through this entire process, the lower the chance that you will create a prolonged negative user experience. In some scenarios, the decision to perform a rollback and the execution of that rollback need to happen in minutes.
It’s a daunting mandate, but here are a few tips to help you meet it.
How to Make Faster Rollback Decisions
It’s challenging to decide—in the moment—whether or not to rollback a feature. Even the best feature release can be complex and chaotic.
There are multiple moving parts to monitor…
There are many different data and feedback points to take into consideration…
And there’s a lot of emotion at play…
You and your team just spent weeks, maybe even months, pouring your blood, sweat, and tears into designing and developing the new feature that you’re testing. If your users love it, then you get that sugar high of knowing you just completed a job well done, and you can just sit back and watch the good data and feedback roll in. But if your users don’t immediately respond as positively as you hoped, then it’s easy to experience an emotional crash and to want to rollback the feature before you even know if the bad response is consistent, let alone what you should do to fix your errors in the next iteration.
For these reasons, and many more, it’s hard to make the right rollback decision in the moment during a feature release test. Instead, it’s better to make your rollback decisions before you release your new features into the wild.
Here’s what we mean.
Basically, before you release any new features to any real-world users, you first decide what success and failure looks like for this feature in objective, data-driven terms.
Then, you decide how much data your release will need to generate before you can make an accurate call about whether the feature is a success or a failure.
Finally, you use these parameters during your release to make objective “yes/no” decisions about whether or not you should rollback your feature at any point. Instead of getting caught up in the moment, you just monitor the performance metrics that you decided were most important, and once they hit the thresholds you set prior to release you simply follow the plan and you either rollback the feature or you don’t— no real-time agonizing required.
How to Execute Rollbacks Faster
In the past, it was near-impossible to perform a rollback quickly from a technical perspective. You needed to have a technical team standing by, waiting to dig into the code to turn off live features, or to revert to a prior state of the entire platform. The entire process was slow, it was labor-intensive, and it took your technical teams away from their valuable development work.
Software has solved all of these problems. With our own feature management platform, you can rollback a feature in real-time by just toggling a single field with just one click. You don’t need any technical expertise to do so. You don’t need to develop and test a complex rollback process prior to feature release. You don’t even need to think about the technical details— you can save all of that thinking to create the right strategic decision trees that we outlined in the prior section.
AB Tasty also gives you—or any non-technical user—the ability to perform sophisticated feature releases and rollbacks. You can release multiple features at once, monitor how each feature is performing individually, and only rollback the features that aren’t delivering. You can roll out a feature to multiple user segments and only rollback that feature to the individual segments that aren’t responding well to it. We designed our server-side solution to make the execution of rollbacks faster, easier, and far more intuitive than they ever were before.
In a perfect world, you release a product that is bug-free and works exactly as it should and so there is no need for further testing.
However, both product managers and developers know that it’s not as simple as that. They need a way to make sure that there is a process in place that reveals any issues in code in a live production environment.
This is where testing in production comes in.
But it’s also one of the highly debated topics out there with those who say you should always test in production, and those who are more wary of the concept and say you never should.
In this article, we’ll look into these two different perspectives and share our own point of view on this controversial topic and we’ll guide you through the best ways to reap the benefits of this type of testing.
What is testing in production?
To keep it short and simple, testing in production is a software development practice of running different tests on your product when it’s in a live environment in real time.
This type of testing is not meant to be a replacement for your QA team or eliminating a unit test or integration test. In other words, it is not supposed to replace testing before production but to complement these tests.
To do or not to do: That is the real question
These are big benefits, and they are enough to create consensus among many developers and product managers who say “Yes, always!” to the practice.
But there’s also another group of developers and product managers who say “No, never!” to testing in production.
On the one hand, they admit all of the great benefits that testing in production can deliver. On the other hand, they also believe that the practice carries too many potential downsides and that its benefits just aren’t worth taking on the risks the practice can bring.
Which side are we on?
We believe testing in production is a cornerstone practice for anyone in the software development world. And we believe it is particularly important for Product Managers, as it gives them a powerful method to generate real-world feedback and performance data they need to make sure they are always building a viable pipeline of products.
But even though we are great advocates of this practice, we still want to consider the point of view of those who are “No, never!” when it comes to this type of testing.
Once we acknowledge these issues, we can start to map out some ways to mitigate the practice’s potential downsides and focus on its benefits instead.
What are the big risks of testing in production?
To be blunt: a lot of things can go wrong when you test in production.
You risk deploying bad code
You may accidentally leak sensitive data
It can possibly cause system overload
You can mess up your tracking and analytics
You risk releasing a poorly designed product or feature
The list goes on and on. Anything that can go wrong, could go wrong.
Worst of all— if something does go wrong when you are testing in production, your mistake will have real-world consequences. Your product might crash at a critical moment of real-time usage.
You might also end up collecting inaccurate KPIs and creating issues with your business stakeholders.
Worse case scenario: your poorly designed product or feature might result in multiple paying customers leaving your product for a competitor instead.
Those who say “No, never!” to testing in production are correct to consider the practice highly risky, and we understand why they stay away from it.
And yet, while we acknowledge these concerns, when it comes down to it, we believe that this form of testing is an essential aspect of modern software development.
Why should you still test in production?
When done properly, testing in production gives you some great benefits that you just can’t get through any other method.
Collect real-world data and feedback
Testing in production allows you to collect user data in terms of users’ engagement with your new features. This enables the collection of valuable feedback from the customers that matters the most, which in turn would allow you to optimize the user experience based on this feedback.
This will also allow you to brainstorm ideas for features that you may not have considered before.
Uncover bugs
Since you’re testing on live users, you would be able to discover any bugs or issues that you may have otherwise missed in the development stage. Thus, you can ensure your new products and features are stable and capable of handling a high volume of real-world usage.
It is worth noting that there are certain technical issues that will never show up until you put your product or feature in front of real-world users.
Therefore, you can monitor the performance of your releases in real life so that developers can analyze performance and optimize the releases accordingly.
Higher quality releases
Because you’re receiving continuous feedback from your users, developers can improve the products resulting in high quality releases that meet your customers’ needs and expectations.
Additionally, you can verify the scalability of your product or feature through load testing in production.
Support a larger strategy of incremental release
Testing in production helps facilitate an environment of continuous delivery.
This is especially true when you roll out your releases to a certain percentage of users so that they may no longer have to wait long periods of time before they have access to your brand new features.
This way, you can limit the blast radius as with incremental releases, you would not have affected all of your users.
Perhaps, most importantly: you already are testing in production, even if you didn’t know it!
Most of Agile development and product management’s best practices are forms of testing in development. We’re talking about very common practices like:
If you are following any of these practices—and many more like them—then you are already running tests with real-world users in a live production environment.
You are already testing in production, whether you call it that or not, even if you thought you were in the “No, never!” camp this whole time.
Testing in production done right
If testing in development is inevitable these days, then you should spend less time debating its pros and cons, and more time finding the most effective and responsible way to follow the practice.
We believe in this perspective so strongly that we’ve built an entire product suite around helping product developers gain all of the benefits of the practice while minimizing their risks.
Feature flags – a software development practice that allows you to enable or disable functionality without deploying code – are at the core of this new platform.
By wrapping your features in a flag and deploying them into production without making them visible to all users, you can safely perform all of the testing in production that you need.
With feature flags—combined with the rest of AB Tasty— you can:
Deploy smaller releases that minimize the impact of failure.
Only test your new features on your most loyal and understanding users.
Personalize their tests so they know to expect a few hiccups with the release.
Immediately toggle off underperforming features with a single click.
With feature flags and a little planning, you can dramatically reduce the risk and increase the sophistication of the testing in production you are already performing.
This means more real-world user data, more reliable products & features, and less worry about seeing how your hard work performs outside of the safe confines of development and staging environments.
You’ve heard all about the surface-level benefits of rapid product releases. They let you explore, experiment with, and test features faster. They create a more collaborative development process. And they let you run an efficient high-output team.
All of these benefits are true, but the biggest benefits you’ll enjoy from driving rapid releases lie even deeper than is commonly acknowledged…
Rapid releases do create better products. Rapid releases create a short feedback loop between you and your users. You learn very quickly what’s working and what isn’t, and you can quickly adjust.
But even more important, rapid releases get you and your team out of your own heads. Rapid releases force you to get your product and feature ideas out of the lab and into the real world. This constant contact with reality leads you to create products that simply and directly deliver the actual functions your users need most, while leaving the nice-to-have fluff on the whiteboard.
Rapid releases do create happier users. Rapid releases let you provide new features, and fix bugs, as quickly as possible. You constantly give your users a better and better product.
But on an even deeper level, rapid releases demonstrate that you care about your users. It shows them that you are listening to their feedback, and that you are taking it seriously. It tells your users that you care about them so much that you have structured the heart of your product management strategy around doing whatever it takes to make them happy and loyal.
Rapid releases do create better businesses. Rapid releases—when properly executed—can create a lot of excitement and enthusiasm throughout your entire organization. They create a culture of progress and forward momentum, where everyone feels that they are contributing to real outcomes and not just spinning their wheels.
But rapid releases also improve your organization’s culture through an even subtler mechanism. Each release can act as a touchpoint that connects the product team with everyone else in the organization. It gives you a common reason to celebrate, to collaborate, and to realign groups that are too often siloed.
Now, we don’t want to oversell rapid releases here. They are not a cure-all, and they are not even appropriate for every single situation. But if you are operating in a context where you can accelerate your product and feature release cycle, you’ll experience a whole lot of upside with little-to-no downside.
To help you drive rapid releases in your organization, we’ll use this piece to explore why rapid releases can be challenging to pull off (even in an agile product development framework), what is the key ingredient you can adopt to overcome all of these challenges, and how to bring that ingredient to life in your organization.
The Biggest Challenges to Driving Rapid Releases
Let’s be clear about one thing— not every organization is well set up to deliver rapid releases. Product managers at big, legacy corporations tend to have a hard time getting anything out in a timely manner. This is almost never their fault. They just have so many layers of review and approval for everything they do that it can take months to push out a small feature that a smaller, nimbler organization could release in weeks or days.
If this is your context, then the best thing you can do is attempt to establish the core principles of lean product development in your organization. This will represent a huge win, and speed things up significantly for you, all by itself.
Now for the rest of you— Let’s assume you are working at one of those smaller, nimbler organizations. And you are already following an agile product development process. And you still are not releasing new products and features as quickly as you’d like. Chances are, you’re being bottlenecked by one or more of these subtle challenges:
You are completing sprint after sprint but you never seem to get any closer to having something to release. Your entire development process feels like it’s focused on completing code, and not completing products and features.
You are getting products and features close to release, but they get trapped in the testing and QA process. This delays their release significantly—sometimes indefinitely.
You are able to complete new features and products, but release gets delayed because it’s such a miserable process. It’s always a big, chaotic scramble. And everyone—from your product team to your business stakeholders—gets stressed and worried about what’s going to happen when you publish the changes and delay the process.
None of these issues are solved by the fundamentals of agile product development. It’s easy to focus agile workflows on development and never give much thought to release. It’s easy to put off testing and QA until the last minute for the sake of velocity, and wind up with a huge backlog to deal with at the end. And agile products and features have developed a reputation (deserved or not) for being buggy, broken, and more aligned with what the product team thinks is right, and not what the customer actually wants.
It’s clear that agile in and of itself will not solve these problems, nor ensure rapid releases. But a small tweak to agile will.
How Progressive Rollouts Unlock Rapid Releases in Agile Product Development
You’ve heard of progressive rollouts before. They are considered an optional subset of agile methodology that restructure the entire release process.
Traditionally, a product manager would release a new product or feature in its full form, to every user, at the exact same time. But a product manager that follows progressive rollouts would release that same new product or feature in smaller forms, to a few user groups at a time, and in staged intervals.
Essentially, progressive rollouts let you break up “big bang” releases into smaller chunks. And along the way, you end up solving a lot of the challenges that prevent rapid releases. For example:
Progressive rollouts shift the product team’s focus off developing new code, and onto driving releases.
Progressive rollouts force you to focus on code quality, and readiness to deploy, instead of code volume.
Progressive rollouts remove most of the risks—and resulting stress—from releases by shrinking them into smaller, easier-to-control stages.
Progressive rollouts are the key ingredient that takes the solid foundation of lean product management, and ensures it’s properly lined up to deliver rapid releases. Here’s how you can bring it to life in your organization.
7 Steps to Ensuring Rapid Releases with Progressive Rollouts
Structure Your Release Phases: Don’t let them be hurried, disorganized dashes at the end of a development cycle. Give them the same time, attention, and care as you give every other element of your product management framework. Create formalized processes, and adopt the tools you need to make those processes automatic habits.
Decide Which Products and Features to Release. Review your current queue. Identify the highest impact products and features that you can drive to completion soonest. Employ feature flags to hide features in products that aren’t ready yet, and focus your users on one small subset of new functionality at a time.
Establish Your Personas and User Groups. Identify your highest-value users, and the opportunities they represent. Leverage these groups to test the new products and features they will love most. Personalize and customize their experience to let them know they’re getting early access because of just how valuable they are to you.
Plan Your Progressive Rollouts: Define the features and products you are going to release. Define who they are going to be released to. Define when they are going to be released, and what the stages look like. And then organize your sprints to deliver to these requirements.
Define the Impact of Each Rollout. Establish the exact, measurable, accountable business metrics you plan to improve with each of your rollouts. Define the hard and soft impact each release will have on every function in your business— and tell each function about the release before it happens.
Communicate Your Release. Loop your business stakeholders in on each element of your release plans that might give them pause or concern. Show them how progressive rollouts mitigate their risk around product and feature quality and alignment. And update them on the progress of each release at each stage of your rollout.
Automate as Much of Your Rollout as Possible. Remove yourself and your team as the bottleneck. Automate your QA and testing. Set your deployment intervals and parameters, and then let your software execute it for you. Monitor your release’s performance at each stage. A/B test as much as possible. And intervene ASAP when an issue is identified. But otherwise, let the right tools make rapid releases through progressive rollouts a smooth element of your agile product development process.
With a little bit of intentional planning, with a shift in the focus of your agile product development, and with the right tools, you can easily bring progressive rollouts to your organization, and rapidly increase the rate of your releases.
When you adopt continuous deployment, you take everything that you love about Agile Product Management— the rapid iterative processes, the increased product quality and market viability, the accelerated rate of collecting and incorporating customer feedback into products—and you supercharge it.
For example: If you follow a traditional Agile framework, then you are going to aim to release new product iterations every 1-2 weeks. When you upgrade to Continuous Deployment, you will start to iterate your product a few times per day by releasing code as soon as it’s been thoroughly tested and deemed ready to commit.
You get to A/B test new features in real-world environments even faster than before.
You can incorporate customer feedback into your live product in near-real-time.
You are able to create reliable products with few (if any) code-level faults.
All of these benefits directly translate into the thing you care about most— releasing high-quality products and features that align tightly to your customer’s deepest needs.
Evolving Your Agile Product Management Seems Like an Easy Sell, Right?
Well, as great as Continuous Development appears for the core work of Product Managers, there is this other thing to keep in mind before you rush to try to adopt the framework…
For better or worse, there’s a lot more to your job than just creating great products for your customers. You also need to lead your Features Team to get them to actually create those great products and features. You need to get (and keep) your Business Analysts onboard with every product and feature you want to make. And you need to give Marketing a suite of products and features that they understand and know how to share with the world.
As much as Continuous Deployment can make your life easier when it comes to releasing all those great products you manage, it can also create a lot of friction between you and all of those other people who you also need to manage as a big part of your job.
So let’s take a quick look at why you will likely face some pushback from your stakeholders if you try to evolve towards a Continuous Development framework, why the conventional wisdom for disarming their concerns doesn’t really work, and how you might actually get them to adopt Continuous Deployment alongside you.
Let’s start by taking a look at each of their concerns, one at a time.
Why Your Marketing Department Might Push Back on Continuous Deployment
Marketing departments traditionally follow a Waterfall approach to collaborating with Product Managers. They like to perform a lot of market research upfront. They like to get involved in a predefined project planning phase to incorporate their single round of customer research. And then they like to have a well-defined product with static features, benefits, and value propositions that they can easily understand and push.
Continuous Deployment dissolves all of these structures, and forces Marketing departments to become nimble, responsive, and adaptable to daily changes in the products and features they are selling. It’s a big adjustment in approach, and it’s natural for Marketing departments to feel unwilling to throw out everything they know and relearn their profession.
Why Your Business Analysts Might Push Back on Continuous Deployment
Business Analysts operate pretty similar to traditional Marketing departments. BAs like to have a lengthy discovery phase upfront. They like to extract a clean set of product requirements, and to enshrine them into a fixed document that acts as a binding agreement between “the business” and the developers. This document gives them some control over the whole process, including a fixed set of outcomes to track project success against.
Continuous Deployment blows away the concepts of fixed requirements, static product descriptions, and project success being linked to checking boxes on an internal contract. It takes control of the project away from the BAs, and places it into the hands of the product team— who are themselves being directed by the direct feedback of users. It makes sense that BAs might be reluctant to give up their control over product development.
Why Your Own Features Team Might Push Back on Continuous Deployment
If anyone should embrace Continuous Deployment with open arms, it’s your Features Team. But often they will push back more than anyone else when you try to make the shift to Continuous Deployment— even if the team already operates from a traditional Agile framework!
Some of this pushback is just inertia. Your Features Team has refined a set of workflows over the years, and they don’t see the point in adopting new tools and processes just to fix a way of doing their job that (from their perspective) isn’t broken.
But some of it runs much deeper. Continuous Deployment changes the Feature Team’s job description. Instead of building towards well-defined product milestones—and defining success by how quickly and accurately they hit those milestones—Continuous Deployment shifts Feature Teams off development and onto testing and bug fixes, while forcing them to adapt to a much more ambiguous definition of whether or not they are excelling at their jobs.
Disarming Each of These Objections (It’s Not as Simple as It Might Look)
If you’re going to adopt Continuous Deployment as a Product Manager, then you’re going to need to convince each of your stakeholder groups that it’s a worthwhile change. And—contrary to the advice you’ll find if you search through the development community’s discussions on this topic—convincing these three stakeholder groups to toss their old way of doing things and adopt Continuous Deployment is not as simple as:
“Explaining the pros-and-cons of Continuous Development.”
“Changing your organization’s culture.”
“Communicating more.”
We don’t mean to be flip here, or to poke fun at anyone who is offering genuine advice. We’d just like to point one thing out— while these actions are necessary elements of any change management program, they don’t really address the deep concerns your stakeholders feel about adopting this new Product Management methodology. No amount of pros-and-cons lists that outline why Continuous Development is great for you will address the fact that:
Your Marketing department is worried because they don’t know if they are selling a product or feature set that has already dramatically changed since you last spoke.
Your Business Analysts are worried that you are going to waste a lot of time, money, and manpower building products with no clear use case.
Your Features Team are worried that 90% of their job is going to become fixing bugs and cleaning code instead of hitting targets that they can point to during a performance review.
These are not shallow concerns that you can paper over with platitudes or educational sessions on the value of Continuous Deployment. These are deep, material issues that you need to find a way to address for your stakeholders before you can evolve your Agile Product Management with scrum and reap the benefits of Continuous Deployment.
How to Disarm Your Stakeholders’ Concerns About Continuous Deployment
The answer is simple, but not easy. You have to really dig into each of their concerns, and proactively find a way to solve their problems for them.
You need to fold Marketing into your day-to-day work so they are aware of what you are developing, what changes you have planned, and how soon you will be giving them new products and features to place their campaigns behind. You need to share the customer experience feedback that is informing your decisions, so it can inform Marketing’s messages too.
You need to bring your Business Analysts in too. You must justify the expense of adopting new tools, team members, and training protocols to develop a Continuous Deployment capability. You must then proactively quantify and report on the ways your faster iterations will create a more viable and profitable product suite that remains aligned to the business, its strategy, and its regulatory frameworks.
Most important, you need to take care of your Features Team. You must make sure they don’t miss their development milestones because they are constantly cleaning code. You must make sure they still build and deploy new features and not just new test cases. And you must give them both the training they need to adapt to Continuous Deployment methodologies, and a centralized platform that automates, streamlines, and accelerates their most critical new workflows.
Continuous Deployment represents a big leap forward in Product Management. There were growing pains when the field moved from Waterfall to Agile, and it’s wise to expect—and proactively handle—this new set of obstacles as you evolve to the next stage of Agile product lifecycle management.