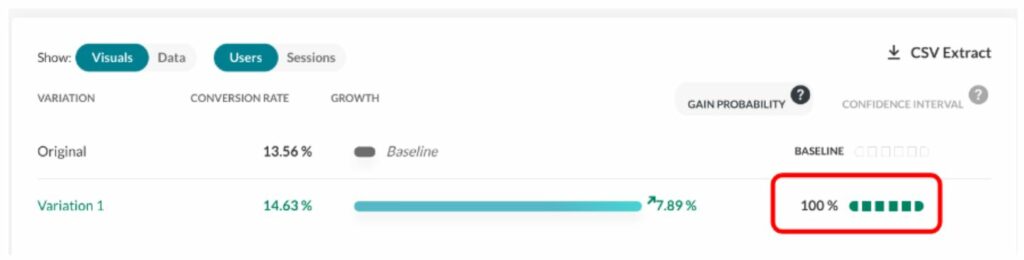
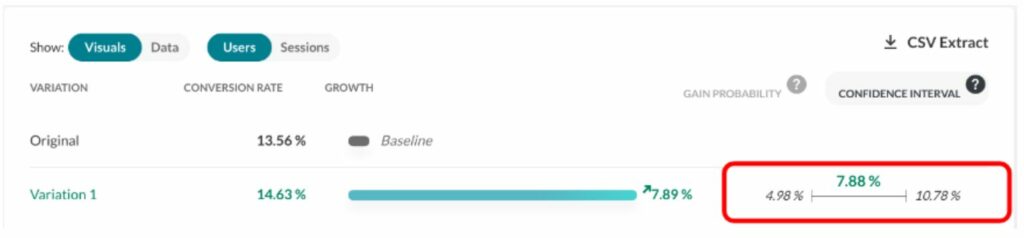
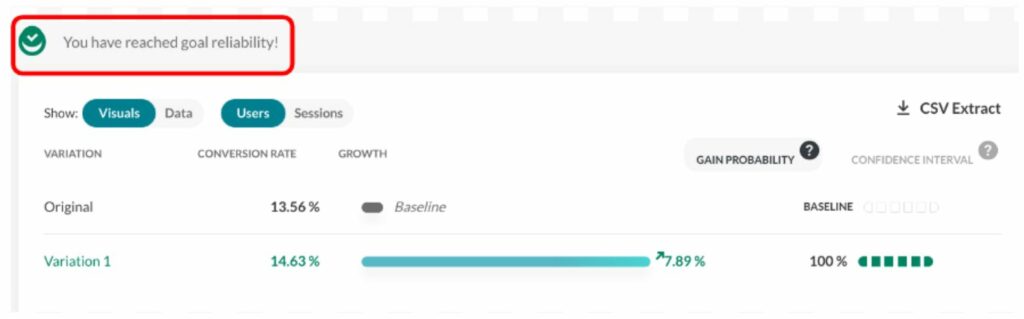
With the end of third-party cookies in sight, first-party data has moved to the forefront of digital marketing.
First-party data is a powerful tool for personalizing your customers’ buying journey. It’s generally more reliable and offers deeper customer insights than third-party data, helping you gain that competitive edge. But these benefits also bring responsibility. It’s essential from both a compliance and customer experience perspective that you practice ethical data collection when it comes to first-party data.
In this article, we take a closer look at first-party data—what it is, how you can collect and use it ethically and the benefits first-party data offers both your customers and your business.
What is first-party data?
First-party data is information about your customers that you collect directly from them via channels you own.
Potential sources of first-party data include your website, social media account, subscriptions, online chat or call center transcripts or customer surveys. Importantly, the first-party data you collect is yours and you have complete control over its usage.
Examples of first-party data include a customer’s
- name, location and email address
- survey responses
- purchase history
- loyalty status
- search history
- email open, click or bounce rates
- interest profile
- website or app navigational behavior, including the page they visit and the time they spend on them
- interactions with paid ads
- feedback
As it comes straight from the customer, first-party data provides you with deep and accurate insights into your audience, their buying behavior and preferences.
These insights are essential for guiding the development of digital marketing strategies that prioritize the human experience, such as personalization. They can also help you create customer personas to help connect with new audiences which may inform key business decisions, including new products or services.
How to collect first-party data
Customers may voluntarily provide first-party data. For example, customers submit their email addresses when signing up for a newsletter, offer their responses when completing a survey or leave comments on a social media post. This is often referred to as declarative data—personal information about your customers that comes from them.
Alternatively, first-party data can be collected via tracking pixels or first-party cookies that record customers’ interactions with your site. This produces behavioral data about your customers.
First-party data is typically stored on a Customer Data Platform (CDP) or Customer Relationship Management (CRM) Platform. From this, you can build a database of information that you can later use to generate customer personas and personalize your marketing efforts.
What is third-party data?
Third-party data removes the direct relationship between your business and your customers during the data collection process. While first-party data comes straight from your customers, third-party data is collected by a separate entity that has no connection to your audience or your business.
Unlike first-party data which is free to collect, third-party data is typically aggregated from various sources and then sold to businesses to use for marketing purposes.
From a marketing perspective, third-party data is further removed and therefore offers less accurate customer insights. You don’t know the source of third-party data and it likely comes from sources that have not used or don’t know your business, limiting its utility.
For many years, marketers relied on third-party cookies to provide the data needed to develop digital marketing strategies and campaigns. But over time, concerns around the ethics of third-party data collection grew, especially in relation to data privacy and users’ lack of control over their data. As a result, most of the major search engines have banned—or will soon ban, in the case of Google Chrome—the use of third-party cookies.
Is first-party data ethical?
First-party data is ethical if it’s collected, stored and used according to data privacy laws, regulations and best practices that require responsible and transparent data handling.
The move away from third-party cookies highlights how first-party data is preferable when it comes to ethical considerations. With full control over the data you collect, you can ensure your first-party data strategy protects the data privacy rights of your customers. You can clearly explain to your customers how you handle their data so they can decide whether they agree to it when using your site or service.
Unfortunately, unethical first-party data collection can and does happen. Businesses that collect data from their customers without informed consent or who use the data in a way the customer didn’t agree to—such as selling it to a third party—violate their data privacy. Not only does this carry potential legal consequences, but it also significantly undermines the relationship of trust between a business and its customers.
How do you collect first-party data ethically?
The first step towards ethical data handling is compliance. There is a range of data privacy laws protecting customer rights and placing obligations on businesses in terms of how they collect, store and use personal data, including first-party data.
Confirming which laws apply to your business and developing an understanding of your legal obligations under them is not only essential for compliance, but it also informs your data architecture structure. The application of data privacy laws depends on your business or activities meeting certain criteria. It’s worth noting that some data privacy laws apply based on where your customer is located, not your business.
Data privacy legislation in Europe
European customers’ data privacy is protected by the General Data Protection Regulation (GDPR). The GDPR requires businesses to demonstrate ethics in data collection and use.
This often means customers must provide informed consent, or opt-in, to their data being collected and used. Businesses must also keep records of this consent. Customers can withdraw their consent at any time and request their data be deleted in certain cases. You must implement reasonable security measures to ensure data is stored securely, according to the level of risk. One option is to use air-gap backups to protect data from cyber threats by isolating it from the network. In certain circumstances, you also need to nominate a data protection officer.
Data privacy legislation in the UK
If you have UK-based customers, you need to comply with the provisions of the UK General Data Protection Regulation (UK GDPR) and the Data Protection Act 2018. These include providing a lawful basis for collecting personal data, such as consumer consent via a positive opt-in.
Consumers have the right to request the use of their data be restricted or their data erased, in certain circumstances. Relevant to first-party data, consumers can object to their data being used for profiling, including for direct marketing purposes.
Data privacy legislation in the US
The US doesn’t have a federal data privacy law. Instead, an increasing number of states have introduced their own. The first state to do so was California.
Under the California Consumer Privacy Act (CCPA)*, you can only collect customer data by informed consent—customers need to know how data, including first-party data, is collected and used. Customers also have the right to opt-out of the sale of their personal data and to request their data be deleted. If a data breach occurs where you have failed to use reasonable security measures to store the data, customers have a right of action.
2023 looks to be a big year for the data privacy landscape in America. In Virginia, the Consumer Data Protection Act (VCDPA) is due to commence on January 1. The VCDPA includes a provision for customers to opt-out of data collection for profiling or targeted advertising processes. Colorado, Connecticut and Utah have introduced similar laws, also ready to commence next year.
Beyond compliance
As you can see, some general principles emerge across the different pieces of data privacy legislation:
- Customer consent — customers should consent to the collection and use of their data
- Transparency — you should explain to customers what data you collect, how you collect it and what you do with it, typically via a privacy policy or statement
- Control — customers should be able to control the use of their data, including requesting its deletion.
From a consumer perspective, compliance is the bare minimum. While the design of your data architecture structure should be guided by the above principles and comply with any relevant data privacy laws, you can also take extra steps to demonstrate your business’s commitment to ethical data handling. This may include appointing a data protection officer to oversee compliance and provide a point of contact for complaints or providing your employees with training, even where it isn’t required by law.
How to use first-party data
In a crowded online marketplace, it’s hard to make yourself heard over the noise. Arming yourself with accurate and reliable first-party data, however, helps you stand out from the crowd and communicate your message to both current and potential customers.
Firstly, you can use the first-party data you collect to create an exceptional customer journey through personas—fictional representations of your customers’ broad wants and needs. Building a series of personas can help you tailor your product or service and business practices to better serve your general customer base.
First-party data is also a crucial ingredient for more specific 1:1 personalization. With it, you can craft a unique user experience for your customers by delivering individual recommendations, messages, ads, content and offers to improve their purchasing journey.
In addition to serving a marketing purpose, first-party data is also essential for retargeting customers, for example, by sending abandoned cart emails. It can also help you identify and address gaps in your customers’ buying experience or your current offerings.

Want to get started with 1:1 personalization or personal recommendations?
AB Tasty and Epoq is the complete platform for experimentation, content personalization, and AI-powered recommendations equipped with the tools you need to create a richer digital experience for your customers — fast. With embedded AI and automation, this platform can help you achieve omnichannel personalization and revolutionize your brand and product experiences.

Benefits of first-party data
Personalization
First-party data provides deeper insights than second or third-party data, allowing you to incorporate a higher degree of personalization in your marketing. In turn, this improves the buying experience for your customers, gaining their loyalty.
Reduces costs
Engaging a third party to aggregate data costs money. First-party data, on the other hand, doesn’t cost you anything to collect.
Increases accuracy
Collecting data from your specific customer base and their interactions with your company produces tailored insights, rather than generic information. First-party data comes directly from the source, increasing its reliability.
Gives you control over data
You own first-party data collected from your customers. This puts you in full control of how it is collected, stored and used.
Transparency
As you have full control over how you collect and use first-party data, you can clearly explain this to your customers to obtain their informed consent. This transparency builds trust and loyalty with your customer base.
Strengthens customer relationships
In a recent Ipsos poll, 84% of Americans report being at least somewhat concerned about the safety of the personal data they provide on the internet. At the same time, Salesforce found that 61% of consumers are comfortable with businesses using their personal data in a beneficial and transparent way. First-party data builds better customer relationships by balancing customers’ desire for data privacy with their preference for personalized advertising.
Compliance with regional privacy laws
Most countries are strengthening their legislative framework around data privacy and prioritizing users’ rights. With first-party data, you can design your data architecture structure to ensure it complies with any relevant laws.
Ethical first-party data handling benefits both you and your customers
First-party data is the key to accurate and sharp customer insights that help you shape effective, targeted marketing strategies. But with the demand for ethical data collection at an all-time high, it’s important you treat your customers’ first-party data with care.
First-party data should be collected responsibly and transparently, with the customer’s fully informed consent. Your first-party data strategy also needs to comply with any relevant data privacy laws, regulations and best practices. This approach achieves a happy medium between addressing customers’ data privacy concerns with their desire for personalization during the purchasing journey. It also helps you optimize your customer’s experience with your business and, in turn, your profits.
Interested in learning more about how you can use first-party data to benefit your business? Check out our customer-centric data series for more insights from the experts.
*Amendments to the CCPA are due to be introduced in 2023, via the California Privacy Rights Act. Many of the related regulations are still being updated.