What is the experience economy?
Let’s say you have an online shop and in that online shop you have a product. Your product is designer eyewear and prescription glasses. A customer visits your online shop to learn about your product. That customer needs to determine which frames will suit their face and what size to order. A similar shop that sells similar products to yours offers free shipping and free returns of up to 3 pairs at no charge, or the use of a virtual reality assistant, via their mobile app, to help their customers make purchasing decisions without needing to visit a store. Your shop, though well-intentioned and bug-free, does not. The customer’s experience researching and selecting their product is what ultimately drives their decision-making process, and they purchase from the other shop. And the next time they need glasses, they purchase from that other shop again. That’s the experience economy.

In the experience economy, finding a differentiating edge is crucial for brands (Source)
Expressed in more academic terms, the experience economy is the packaging of goods and services into a bundle such that the experience of acquiring or consuming is the key selling point – it’s the reason the customer came into your shop in the first place.
In 1998, two Harvard researchers published an article detailing the concept of the experience economy for the first time, using a birthday cake analogy to eventually draw out the definition we see above. These days, the concept is more important than ever, as the rapidly evolving digital transformation of the way we consume information and goods creates a never-ending, multi-channel interaction between brands and consumers. And it’s key to your overall business success.
How e-commerce brands can succeed in the experience economy
In the age of digitalization, not only do all brands have websites, incorporating an e-commerce platform for online sales, but they also have Facebook, Instagram, TikTok and Snapchat accounts, more than likely a YouTube channel, a web browser adapted to mobile devices and an app to sit alongside it. In short, multiple channels and touchpoints for their customers to interact and engage with them, and multiple opportunities to create experiences to acquire new customers and drive sales. This all makes for a non-linear shopping experience, and requires careful examination of what customers expect on which channel and at which time.

A customer-first mindset is crucial for businesses that are looking to win the digital CX game (Source)
How can brands adapt to shifting consumer preferences
At AB Tasty, we’re convinced that the brands opting for a “business as usual” approach will quickly be left in the dust. Customers expect better servicing, more meaningful interactions and suggest that they’ll spend more when brands deliver. This means having a strategy that considers multiple channels, across physical, digital and social touch points, and adapts to the preferences of each individual so that interactions remain authentic and personal. If you’re engaging with customers without being able to have in-person contact, experience matters even more, because consumers still want to be seen as individuals with their own unique needs. Ultimately, their experience will influence their buying decisions and according to Salesforce, 66% of consumers expect companies to understand their unique needs and preferences.

Create a personalized, relevant shopping experience for each customer (Source)
Figuring out what your customers want doesn’t just need to be a guessing game, experimentation is standard practice for the experience economy. In B2C environments, marketing teams test website performance using a range of experiments that examine layout, colors, purchase journeys, product information and visual features to ensure no stone is left unturned in maximizing transactions and revenue. And adopting an experimentation mindset really is a win-win. On the one hand, you’re identifying the best way to interact with your customers – identifying what they respond to and what they want – and on the other, you’re maximizing every opportunity to drive purchases and serve your bottom line.
Why prioritizing customer experiences matters
That’s all very well and good, you might say, but what difference does it really make? Plenty, in fact. Relevant and personalized consumer experiences are key to keeping your brand ahead of its competitors. Let’s explore some of the reasons for this.
- Loyalty is hard-earned and easily lost
PWC’s 2021 Global Consumer Insights Survey found that 84% of shoppers trust brands that provide exceptional customer service, but one in three will walk away after just one negative shopping experience. In a similar vein, Qualtrics’ 2022 Global Consumer Trends survey reported that 60% of consumers would buy more if businesses treated them better, and also determined that 9.5% of your overall revenue is at risk from negative shopping experiences. These statistics still haven’t convinced you? Read on!
ㅤ
- Seamlessness is synonymous with success
You can design any number of gimmicks to attract attention, but it’s the seamless ones that stick. Take the Clarins Singles Day Wheel of Fortune promotion, where any customer landing on the brand’s desktop or mobile site in EMEA saw a pop-up to spin the wheel. They were then rewarded with one of six special offers, which was automatically added to their basket via a promo code at the checkout. This automatic add proved crucial: Results were strong across all key territories, with Ireland particularly notable, seeing a 495% increase in orders and a 585% increase in revenue. Clarins uncovered a clever, engaging offer and coupled it with a seamless UX process for their shoppers, delivering simply stunning results.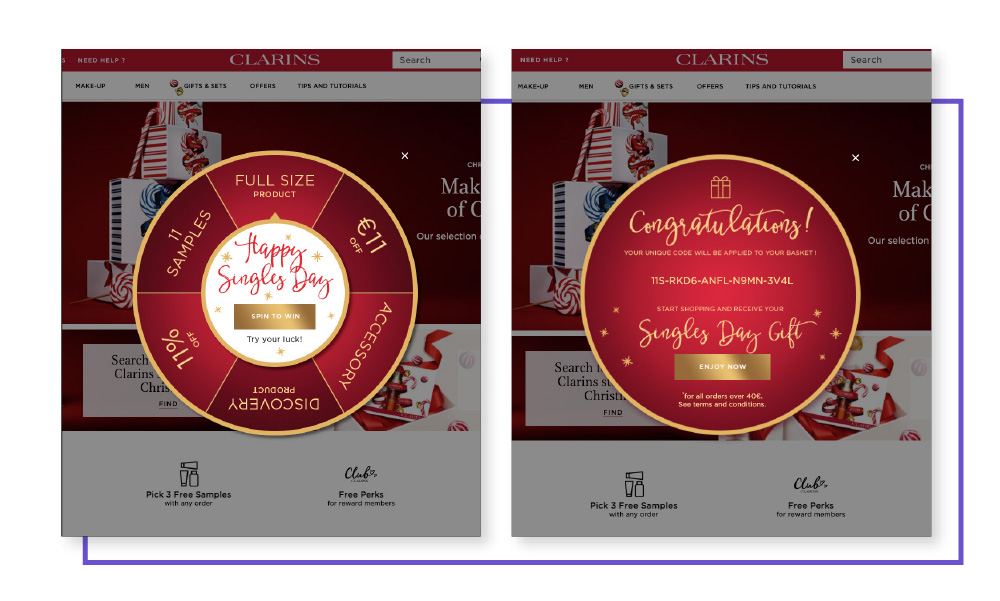 Clarins delivered a customer experience on par with their clients’ expectations (Source)
Clarins delivered a customer experience on par with their clients’ expectations (Source)
ㅤ - Stagnate and you’ll be left behind
To innovate or not to innovate, is it even a question? If you’re thinking about it, then your competitors almost certainly are too. And if you’re not trying something new, you almost certainly risk falling behind. While bug-free websites and a smooth journey through the purchase funnel is great, it’s also the bare minimum that you should be doing. Salesforce found that 91% of customers are more likely to make a repeat purchase from a company after a positive customer experience. Delivering a seamless, multichannel experience across all business interactions is integral to staying ahead and it’s clear there is still scope for brands to optimize.
4 examples of brands that are excelling in the experience economy
As we’ve seen in the above section, brands that embrace the experience economy are best-positioned to see increased loyalty, repeat business, and convert their customers into advocates for their products. Pushing beyond experiences into memorable interactions for their consumers has allowed some of the best-known brands in the world to gain further ground on their direct competitors, all while staying true to their core values. Let’s take a look at the best-in-class trends and examples of the experience economy model.
Nike
Nike is driven by delivering innovative products, services and experiences to inspire athletes. One such experience is their Nike Fit solution: an AI-driven app that allows you to virtually measure and fit your foot to ensure you choose the right pair of Nike shoes, no matter the style nor the shape of your foot, and without having to leave your living room.

Nike introduces innovative solutions to their clients’ biggest point of friction (Source)
Sephora
In 2019, Sephora pioneered their intelligent digital mirror in the brand’s Madrid flagship, using the power of AI to deliver hyper-personalized experiences and product recommendations to shoppers. The mirror not only allows consumers to “test” products by displaying how they’ll render when applied, it also provides personalized product recommendations and suggestions based on an analysis of the customer’s features.

Sephora develops new ways to offer their customers personalized recommendations (Source)
Starbucks
Starbucks has revolutionized their physical footprint by opening pickup-only stores in key, high-traffic locations where rental space is at a premium and busy lives mean in-and-out transactions are the order of the day. This store concept allows coffee lovers to order and pay ahead of time, via the Starbucks mobile app, and nominate the pickup location, for a speedy service that saves tedious, peak-hour queues. Not to mention a boost to sales per square foot, a key metric in the brick-and-mortar retail space.

Starbucks identifies their customers’ needs and delivers an optimal shopping experience (Source)
Asos
This online fashion retailer was founded in London in 2000, and now sells over 850 brands around the world. In identifying one of the key barriers to online shopping for clothes – choosing the correct size – Asos developed their Fit Assistant tool to ensure customers could navigate the online shopping experience hassle-free. Available on both desktop and mobile, Fit Assistant delivers personalized recommendations according to shoppers’ individual shapes and sizes.
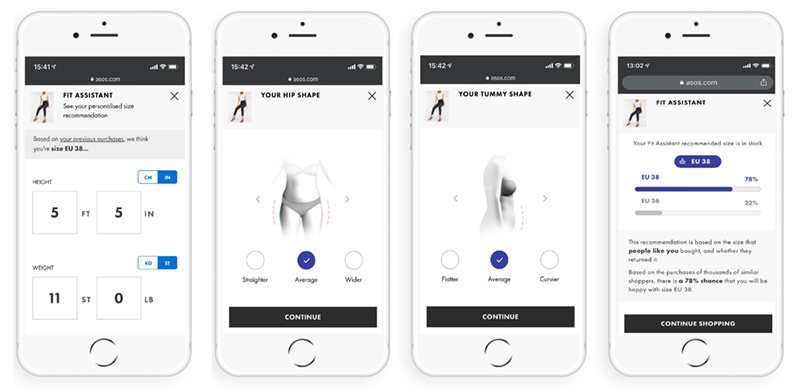
Asos optimizes their customers’ online shopping experience (Source)
Why the experience economy is here to stay
Through a combination of rapid digital transformation, technological innovation of smart devices (phones, tablets, watches and more), and the increasing pace of our daily lives, the manner in which we consume products has evolved beyond mere acquisition. How we consume the product matters. How we feel about how we consume the product matters. How the brand ensures we enjoy our consumption of the product matters. And if your brand is not up for the challenge and staying ahead of the game, consumers will find one that is. It’s as simple as that. Evolve, innovate, and deliver seamless brand experiences, and you’ll lead the competition, win market share and generate growth.
If you’re looking for some guidance on how to deliver impactful brand experiences that will “wow” your customers, draw inspiration from the first-ever digital customer journey that maps out how to drive optimization and innovation to take your customer experience to the next level.