Feature flags are an indispensable tool to have when it comes to software development and release that can be used for a wide range of use-cases.
You know the saying ‘you can never have too much of a good thing’? In this case, the opposite is true. While feature flags can bring a lot of value to your processes, they can also pose some problems particularly if mismanaged. Such problems particularly come about when using an in-house feature flagging platform.
In this series of posts of ‘Fun with Flags’, we will be introducing some essential best practices when it comes to using and implementing feature flags.
In this first post, we will focus on an important best practice when it comes to keeping your flags organized: naming your flags.
What are feature flags?
First things first, let’s start with a brief overview of feature flags.
Feature flags are a software development practice that allows you to turn certain functionalities on and off to safely test new features without changing code.
Feature flags mitigate risks of new releases by decoupling code deployment from release. Therefore, any new changes that are ready can be released while features that are still a work-in-progress can be toggled off making them invisible to users.
There are many types of feature flags, categorized based on their dynamism and longevity that serve different purposes.
As the number of flags within your system grows, the harder it becomes to manage your flags. Therefore, you need to establish some practices in order to mitigate any negative impact on your system.
It is because of these different categories of flags that establishing a naming convention becomes especially important.
Click here for our definitive guide on feature flags.
What’s in a name?
Defining a name or naming convention for your flags is one essential way to keep all the different flags you have in your system organized.
Before creating your first flag, you will need to establish a naming convention that your teams could adhere to when the time comes to start your feature flag journey. Thus, you need to be organized from the very beginning so as not to lose sight of any flags you use now and in the future.
The most important rule when naming your flags is to try to be as detailed and descriptive as possible. This will make it easier for people in your organization to determine what this flag is for and what it does. The more detailed, the less the margin for confusion and error.
We suggest the following when coming up with a naming convention:
Include your team name– this is especially important if you come from a big organization with many different teams who will be using these flags.
Include the date of creating the flag– this helps when it comes to cleaning up flags, especially ones that have been in your system for so long that they’re no longer necessary and have out-served their purpose.
Include a description of the flag’s behavior.
Include the flag’s category– i.e. whether it’s permanent or temporary.
Include information about the test environment and scope as in which part of the system the flag affects.
Let’s consider an example…
Let’s say you want to create a kill switch that would allow you to roll back or turn off any buggy features.
Kill switches are usually long-lived so they may stay in a codebase for a long time, meaning it is essential the name is clear and detailed enough to keep track of this flag since its use can extend across many contexts over a long period of time.
The name of such a flag could look something like this:
algteam_20-07-2021_Ops_Configurator-killswitch
Following the naming convention mentioned above, the first part is the name of the team followed by the date of creation then the category and behavior of the flag. In this case, a kill switch comes under the category of operational (ops) toggles.
Using such a naming convention allows the rest of your teams across your organization to see exactly who created the flag, for what purpose and how long it has been in the codebase.
Why is this important?
Sticking with such naming conventions will help differentiate such long-lived flags from shorter-lived ones.
This is important to remember because an operational toggle such as a kill switch serves a vastly different purpose than, for example, an experiment toggle.
Experiment toggles are created in order to measure the impact of a feature flag on users. Over the course of your feature flag journey, you may create numerous flags such as these to test different features.
Without an established and well-thought out naming convention, you’ll end up with something like ‘new-flag’ and after some time and several flags later, this naming system becomes tedious and repetitive to the point when you cannot determine which flag is actually new.
In this case, you might want to opt for something more specific. For example, if you want to test out a new chat option within your application, you’ll want to name it something akin to:
Markteam_21-07-2021_chatbox-temp
Such a name will clue you into who created it and what this flag was created for, which is to test the new chat box option and of course, you will know it’s a temporary flag.
This way, there will be no more panic from trying to figure out what one flag out of hundreds is doing in your system or ending up with duplicate flags.
Or even worse, someone on your team could accidentally trigger the wrong flag, inciting chaos and disruption in your system and ending up with very angry users.
Don’t drown in debt
Making a clear distinction between the categories of flags is crucial as short-lived, temporary flags are not meant to stay in your system for long.
This will help you clean up those ‘stale’ flags, otherwise they may end up clogging your system giving rise to the dreaded technical debt.
To avoid an accumulation of this type of debt, you will need to frequently review the flags you have in your system, especially the short-lived ones.
This would be no easy task if your flags had names like ‘new flag 1’, ‘new flag 2’, and well, you get the gist.
A wise man once said…
…“the beginning of wisdom is to call things by their proper name” (Confucius). In the case of feature flags, this rings more true than ever.
Whatever naming convention you choose that suits your organization best, make sure that everyone across all your teams stick to them.
Feature flags can bring you a world of benefits but you need to use them with caution to harness their full potential.
With AB Tasty’s flagging functionality, you can remotely manage your flags and keep technical debt at bay by providing you with dedicated features to help you keep your feature flags under control.
For example, the Flag Tracking dashboard within the AB Tasty platform lists all the flags that are set up in your system so you can easily keep track of every single flag and its purpose.
One of the most critical metrics in DevOps is the speed with which you deliver new features. Aligning developers, ops teams, and support staff together, they quickly get new software into production that generates value sooner and can often be the deciding factor in whether your company gains an edge on the competition.
Quick delivery also shortens the time between software development and user feedback, which is essential for teams practicing CI/CD.
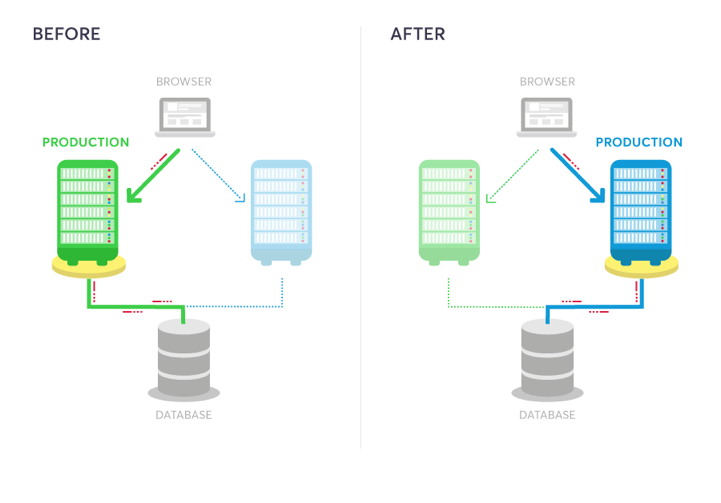
One practice you should consider adding to your CI/CD toolkit is the blue-green deployment. This process helps reduce both technical and business risks associated with software releases.
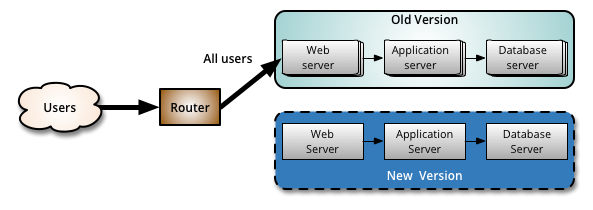
In this model, two identical production environments nicknamed “blue” and “green” are running side-by-side, but only one is live, receiving user transactions. The other is up but idle.
In this article, we’ll go over how blue-green deployments work. We’ll discuss the pros and cons of using this approach to release software. We’ll also compare how they stack up against other deployment methodologies and give you some of our recommended best practices for ensuring your blue-green deployments go smoothly.
[toc]
How do blue-green deployments work?
One of the most challenging steps in a deployment process is the cutover from testing to production. It must happen quickly and smoothly to minimize downtime.
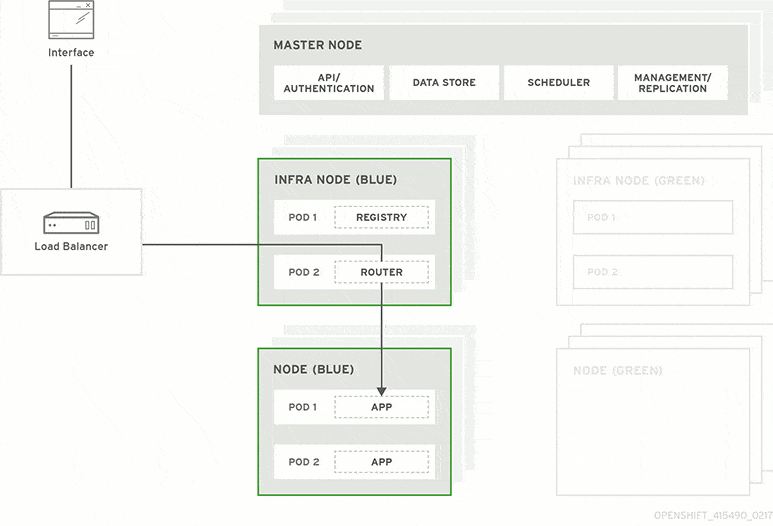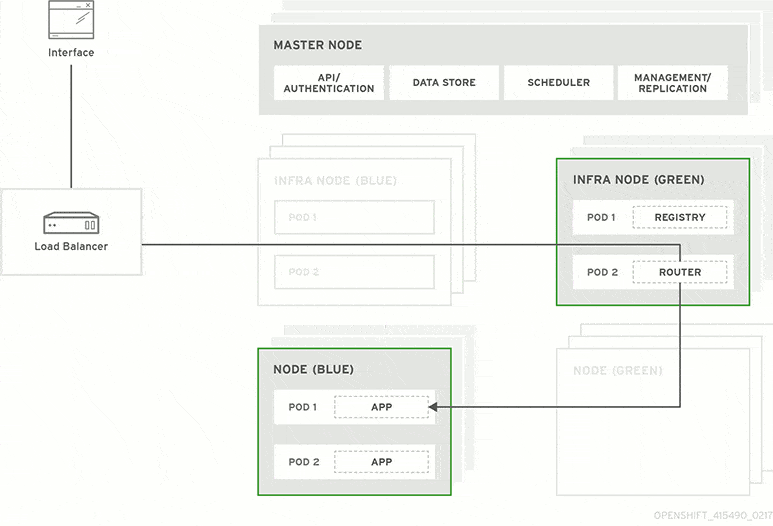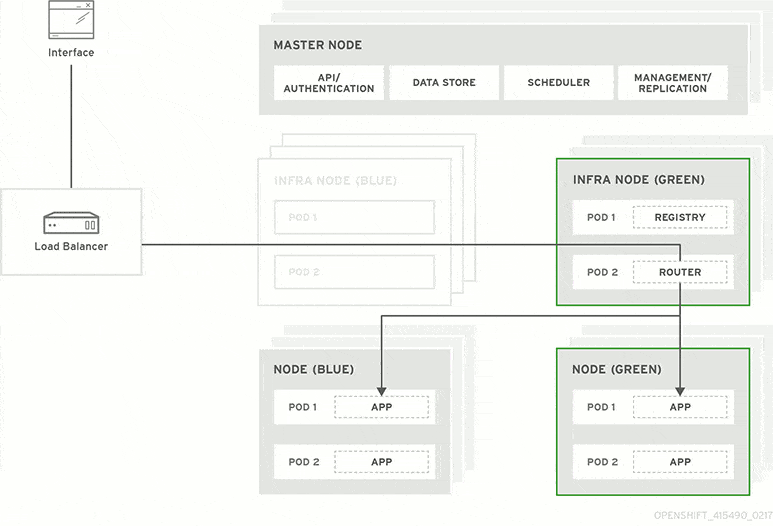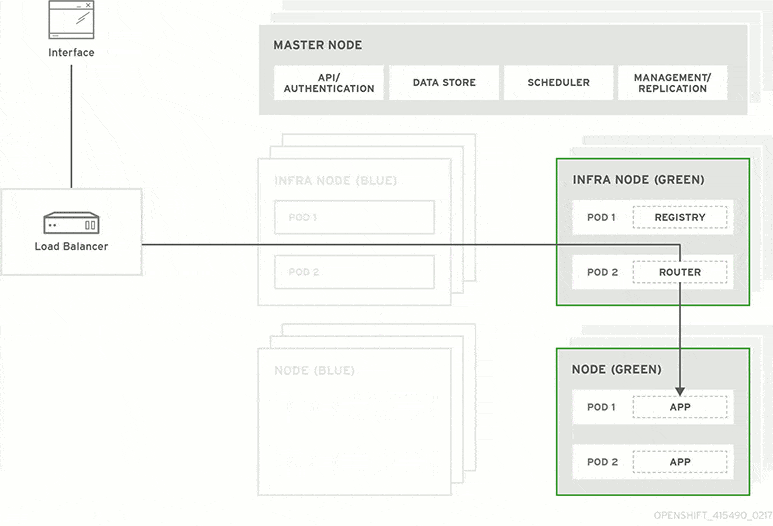
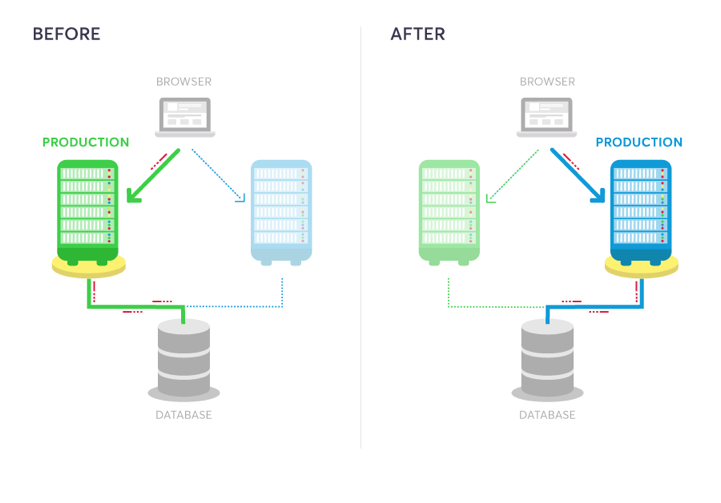
A blue-green deployment methodology addresses this challenge by utilizing two parallel production environments. At any given time, only one of them is the live environment receiving user transactions. In the image below, that would be green. The blue idle system is a near-identical copy.
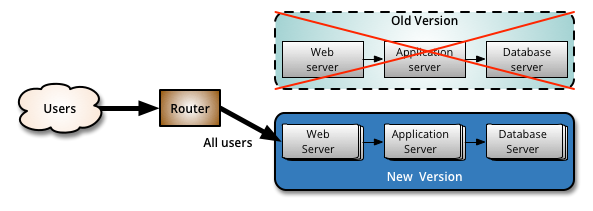
Your team will use the idle blue system as your test or staging environment to conduct the final round of testing when preparing to release a new feature. Once the new software is working correctly on blue, your ops team can switch routing to make blue the live system. You can then implement the feature on green, which is now idle, to get both systems resynchronized.
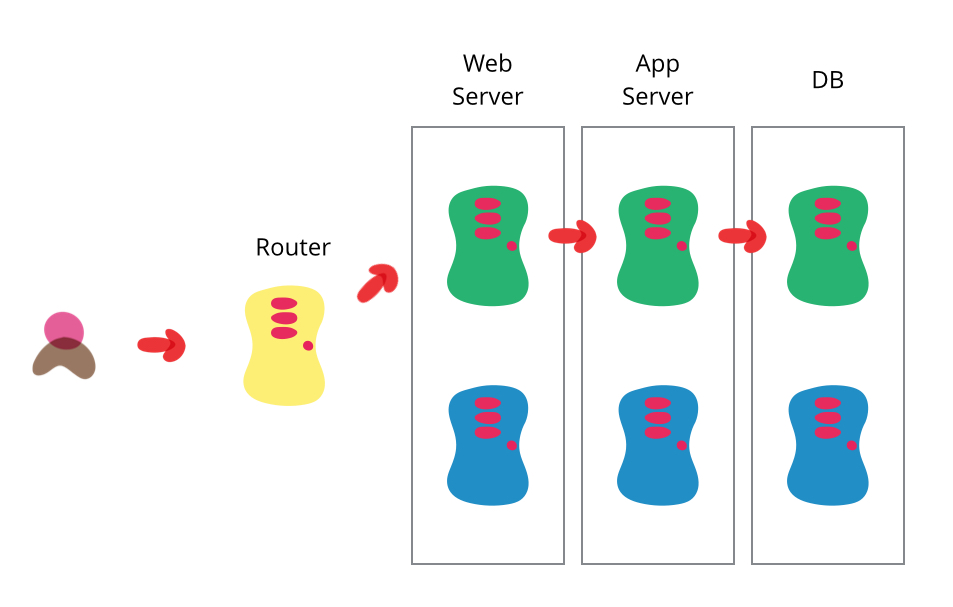
Generally speaking, that is all there is to a blue-green deployment. You have a great deal of flexibility in how the parallel systems and cut-overs are structured. For example, you might not want to maintain parallel databases, in which case all you will change is routing to web and app servers. For another project, you may use a blue-green deployment to release an untested feature on the live system, but set it behind a feature flag for A/B user testing.
Example
Let’s say you’re in charge of the DevOps team at a niche e-commerce company. You sell clothing and accessories popular in a small but high-value market. On your site, customers can customize and order products on-demand.
Your site’s backend consists of many microservices in a few different containers. You have microservices for inventory management, order management, customization apps, and a built-in social network to support your customers’ niche community.
Your team will release early and often as you credit your CI/CD model for your continued popularity. But this niche community is global, so your site sees fairly steady traffic throughout any given day. Finding a lull in which to update your production system is always tricky.
When one of your teams announces that their updated customization interface is ready for final testing in production, you decide to release it using a blue-green deployment so it can go out right away.
Animation of load balancer adjusting traffic from blue to green (Source)
The next day before lunch, your team decides they’re ready to launch the new customizer. At that moment, all traffic routes to your blue production system. You update the software on your idle green system and ask testers to put it through Q/A. Everything looks good, so your ops team uses a load balancer to redirect user sessions from blue to green.
Once traffic is completely filtered over to green, you make it the official production environment and set blue to idle. Your dev team pushes the updated customizer code to blue, puts in their lunch order, and takes a look at your backlog.
Pros: Benefits & use cases
One of the primary advantages of blue-green deployments over other software release strategies is how flexible they are. They can be beneficial in a wide range of environments and many use cases.
Rapid releasing
For product owners working within CI/CD frameworks, blue-green deployments are an excellent method to get your software into production. You can release software practically any time. You don’t need to schedule a weekend or off-hours release because, in most cases, all that is necessary to go live is a routing change. Because there is no associated downtime, these deployments have no negative impact on users.
They’re less disruptive for DevOps teams too. They don’t need to rush updates during a set outage window, leading to deployment errors and unnecessary stress. Executive teams will be happier too. They won’t have to watch the clock during downtime, tallying up lost revenue.
Simple rollbacks
The reverse process is equally fast. Because blue-green deployments utilize two parallel production environments, you can quickly flip back to the stable one should any issues arise in your live environment.
This reduces the risks inherent in experimenting in production. Your team can easily remove any issues with a simple routing change back to the stable production environment. There is a risk of losing user transactions cutting back—which we’ll get into a little further down—but many strategies for managing that situation are available.
You can temporarily set your app to be read-only during cutovers. Or you could do rolling cutovers with a load balancer while you wait for transactions to complete in the live environment.
Built-in disaster recovery
Because blue-green deployments use two production environments, they implicitly offer disaster recovery for your business systems. A dual production environment is its own hot backup.
Load balancing
Blue-green parallel production environments also make load balancing easy. When the two environments are functionally identical, you can use a load balancer or feature toggle in your software to route traffic to different environments as needed.
Easier A/B testing
Another use case for parallel production environments is A/B testing. You can load new features onto your idle environment and then split traffic with a feature toggle between your blue and green systems.
Collect data from those split user sessions, monitor your KPIs, and then, if analyses of the new feature look good in your management system, you can flip traffic over to the updated environment.
Cons: Challenges to be aware of
Blue-green deployments offer a great deal of value, but integrating the infrastructure and practices required to carry them out creates challenges for DevOps teams. Before integrating blue-green deployments into your CI/CD pipeline, it is worth understanding these challenges.
Resource-intensive
As is evident by now, to perform a blue-green deployment, you will need to resource and maintain two production environments. The costs of this, in money and sysadmin time, might be too high for some organizations.
For others, they may only be able to commit such resources for their highest value products. If that is the case, does the DevOps team release software in a CI/CD model for some products but not others? That may not be sustainable.
Extra database management
Managing your database—or multiple databases—when you have parallel production environments can be complicated. You need to account for anything downstream of the software update you’re making needs in both your blue and green environments, such as any external services you’re invoking.
For example, what if your feature change requires you to rename a database column? As soon as you change the name to blue, the green environment with old code won’t function with that database anymore.
Can your entire production environment even function with two separate databases? That’s often not the case if you’re using your blue and green systems for load balancing, testing, or any function other than as a hot backup.
A blue-green deployment diagram with a single database (Source)
Product management
Aside from system administration, managing a product that runs on two near-identical environments also requires more resources. Product Managers need reliable tools for tracking how their software is performing, which services different teams are updating, and ways to monitor the KPIs associated with each. A reliable product and feature management dashboard to monitor and coordinate all of these activities becomes essential.
Blue-green deployments vs. rolling deployments
Blue-green deployments are, of course, not the only option for performing rapid software releases. Another popular approach is to conduct a rolling deployment.
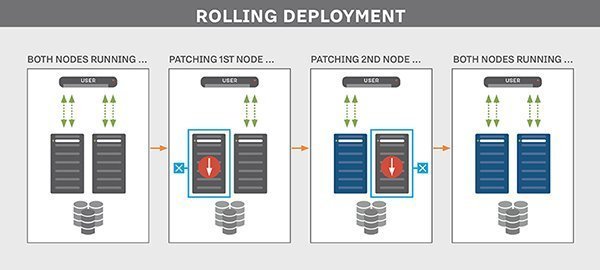
Rolling deployments also require a production environment that consists of multiple servers hosting an application, often, but not always, with a load balancer in front of them for routing traffic. When the DevOps team is ready to update their application, they configure a staggered release, pushing to one server after another.
While the release is rolling out, some live servers will be running the updated application, while others have the older version. This contrasts with a blue-green deployment, where the updated software is either live or not for all users.
As users initiate sessions with the application, they might either reach the old copy of the app or the new one, depending on how the load balancer routes them. When the rollout is complete, every new user session that comes in will reach the software’s updated version. If an error occurs during rollout, the DevOps team can halt updates and route all traffic to the remaining known-good servers until they resolve the error.
Rolling deployments are a viable option for organizations with the resources to host such a large production environment. For those organizations, they are an effective method for releasing small, gradual updates, as you would in agile development methodologies.
There are other use cases where blue-green deployments may be a better fit. For example, if you’re making a significant update where you don’t want any users to access the old version of your software, you would want to take an “all or nothing” approach, like a blue-green deployment.
Suppose your application requires a high degree of technical or customer support. In that case, the support burden is magnified during rolling deployment windows when support staff can’t tell which version of an application users are running.
Blue-green deployments vs. canary releasing
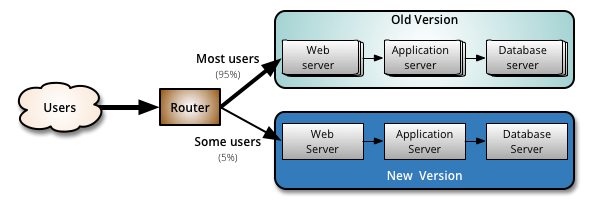
Rolling and blue-green deployments aren’t the only release strategies out there. Canary deployments are another alternative. At first, only a subset of all production environments receives a software update in a canary release. But instead of continuing to roll deploy to the rest, this partial release is held in place for testing purposes. A subset of users is then directed to the new software by a load balancer or a feature flag.
Canary releasing makes sense when you want to collect data and feedback from an identifiable set of users about updated software. Practicing canary releases dovetails nicely with broader rolling deployments, as you can gradually roll the updated software out to larger and larger segments of your user base until you’ve finished updating all production servers.
Best practices
You have many options for releasing software quickly. If you’re considering blue-green deployments as your new software release strategy, we recommend you adopt some of these best practices.
Automate as much as possible
Scripting and automating as much of the release process as possible has many benefits. Not only will the cutover happen faster, but there’s less room for human error. A dev can’t accidentally forget a checklist item if a script or a management platform handles the checklist. If everything is packaged in a script, then any developer or non-developer can carry out the deployment. You don’t need to wait for your system expert to get back to the office.
Monitor your systems
Always make sure to monitor both blue and green environments. For a blue-green deployment to go smoothly, you need to know what is going on in both your live and idle systems.
Both systems will likely need the same set ofmonitoring alerts, but set to different priorities. For example, you’ll want to know the second there is an error in your live system. But the same error in the idle system may need to be addressed sometime that business day.
In some cases, new and old versions of your software won’t be able to run simultaneously during a cutover. For example, if you need to alter your database schema, it would help if you structured your updates so that both blue and green systems will be functional throughout the cutover.
One way to handle these situations is to break your releases down into a series of even smaller release packages. Let’s say our e-commerce company is deepening its inventory and needs to update its database by changing a field name from “shirt” to “longsleeve_shirt” for clarity.
They might break this update down by:
Releasing a feature flag-enabled intermediary version of their code that can interpret results from both “shirt” and “longsleeve_shirt”;
Running a rename migration across their entire database to rename the field;
Releasing the final version of the code—or flip their feature flag—so the software only uses “longsleeve_shirt.”
Do more, smaller deployments
Smaller, more frequent updates are already an integral practice in agile development and CI/CD. It is even more important to follow this practice if you’re going to conduct blue-green deployments. Reducing deployment times shortens feedback loops, informing the next release, making each incremental upgrade more effective and more valuable for your organization.
Restructure your applications into microservices
This approach goes hand-in-hand with conducting smaller deployments. Restructuring application code into sets of microservices allows you to manage updates and changes more easily. Different features are compartmentalized in a way that makes them easier to update in isolation.
Use feature flags to reduce risk further
By themselves, blue-green deployments create a single, short window of risk. You’re updating everything, all-or-nothing, but you can cut back if needed should an issue arise.
Blue-green deployments also have a pretty consistent amount of administrative overhead that comes with each cutover. You can reduce this overhead through automation, but still, you’re going to follow the same process no matter whether you’re updating a single line of code or you’re overhauling your entire e-commerce suite.
Those conditions can be simple “yes/no” checks, or they can be complex decision trees. Feature flags help make software releases more manageable by controlling what is turned on or off at a feature-by-feature level.
For example, our e-commerce company can perform a blue-green deployment of their customizer microservice but leave the new code turned off behind a feature flag in the live system. Then, the DevOps team can turn on that feature according to whatever condition they wish, whenever it is convenient.
The team might want to do some further A/B testing in production. Or maybe they want to conduct some further fitness tests. Or it might make more sense for the team to do a canary release of the customizer for an identified set of early adopters.
Your feature flags can work in conjunction with a load balancer to manage which users see which application and feature subsets while performing a blue-green deployment. Instead of switching over entire applications all at once, you can cut over to the new application and then gradually turn individual features on and off on the live and idle systems until you’ve completely upgraded. This gradual process reduces risk and helps you track down any bugs as individual features go live one-by-one.
You can manually control feature flags in your codebase, or you can use feature flag services for more robust control. These platforms offer detailed reporting and KPI tracking along with a deep set of DevOps management tools.
We recommend using feature flags in any major application release when you’re doing a blue-green deployment. They’re valuable even in smaller deployments where you’re not necessarily switching environments. You can enable features gradually one at a time on blue, leaving green on standby as a hot backup if a major problem arises. Combining feature flags with blue-green deployments is an excellent way to perform continuous delivery at any scale.
Consider adding blue-green deployments to your DevOps arsenal
Blue-green deployments are an excellent method for managing software releases of any size, no matter whether they’re a whole application, major updates, a single microservice, or a small feature update.
It is essential to consider how well blue-green deployments will integrate into your existing delivery process before adopting them. This article detailed how blue-green deployments work, the pros and cons of using them in your delivery process, and how they stack up against other possible deployment methods. You should now have a better sense of whether blue-green deployments might be a viable option for your organization.
Picking an effective deployment strategy is an important decision for every DevOps team. Many options exist, and you want to find the strategy that best aligns with how you work. Today, we’ll go over canary deployments.
Are you an agile organization? Are you performing continuous integration and continuous delivery (CI/CD)? Are you developing a web app? Mobile app? Local desktop or cloud-based app? These factors, and many others, will determine how effective any given deployment strategy will be.
But no matter which strategy you use, remember that deployment issues will be inevitable. A merge may go wrong, bugs may appear, human error may cause a problem in production. The point is, don’t wear yourself out trying to find a deployment strategy that will be perfect. That strategy doesn’t exist.
Instead, try to find a strategy that is highly resilient and adaptive to the way you work. Instead of trying to prevent inevitable errors, deploy code in a way that minimizes errors and allows you to respond when they do occur quickly.
Canary deployments can help you put your best code into production as efficiently as possible. In this article, we’ll go over what they are and what they aren’t. We’ll go over the pros and cons, compare them to other deployment strategies, and show you how you can easily begin performing such deployments with your team.
In this article, we’ll go over:
[toc]
What is a canary deployment?
Canary deployments are a best practice for teams who’ve adopted a continuous delivery process. With this strategy, a new feature is first made available to a small subset of users. The new feature is monitored for several minutes to several hours, depending on the traffic volume, or just long enough to collect meaningful data. If the team identifies an issue, the new feature is quickly pulled. If no problems are found, the feature is made available to the entire user base.
The term “canary deployment” has a fascinating history. It comes from the phrase “canary in a coal mine,” which refers to the historical use of canaries and other small songbirds as living early-warning systems in mines. Miners would bring caged birds with them underground. If the birds fell ill or died, it was a warning that odorless toxic gases, like carbon monoxide, were present. While inhumane, it was an effective process used in Britain and the US until 1986, when electronic sensors replaced canaries.
A canary deployment turns a subset of your users —ideally a bug-tolerant subset— into your own early warning system. That user group identifies bugs, broken features, and unintuitive features before your software gets wider exposure.
Your canary users could be self-identified early adopters, a demographically targeted segment, or a random sampling. Whichever mix of users makes the most sense for verifying your new feature in production.
One helpful way to think about canary deployments is risk management. You are free to push new, exciting features more regularly without having to worry that any one new feature will harm the experience of your entire user base.
Canary releases vs. canary deployments
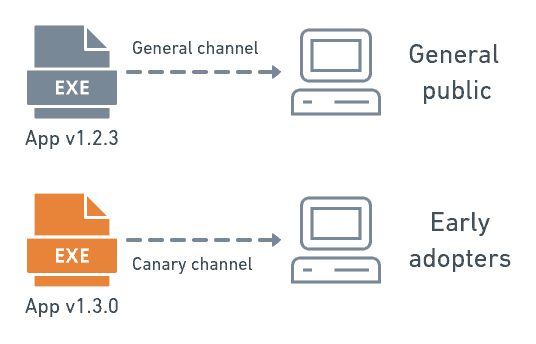
The phrases “canary release” and “canary deployment” are sometimes used interchangeably, but in DevOps, they really should be thought of as separate. A canary release is a test build of a complete application. It could be a nightly release or a beta, for example.
Teams will often distribute canary releases hoping that early adopters and power users, who are more familiar with development processes, will download the new application for real-world testing. The browser teams at Mozilla and Google, and many other open-source projects, are fond of this release strategy.
On the other hand, canary deployments are what we described earlier. A team will release new features into production with early adopters or different user subsets, routed to the new software by a load balancer or feature flag. Most of the user base still sees the current, stable software.
Canary deployment pros and cons
Canary deployments can be a powerful and effective release strategy. But they’re not the correct strategy in every possible scenario. Let’s run through some of the pros and cons so you can better determine whether they make sense for your DevOps team.
Pros
Support for CI/CD processes
Canary deployments shorten feedback loops on new features delivered to production. DevOps teams get real-world usage data faster, which allows them to refine and integrate the next round of features faster and more effectively. Shorter development loops like this are one of the hallmarks of continuous integration/continuous delivery processes.
Granular control over feature deployments
If your team conducts smaller, regular feature deployments, you reduce the risk of errors disrupting your workflow. If you catch a mistake in the deployment, you won’t have exposed many users to it, and it will be a minor matter to resolve. You won’t have exposed your entire user population and needed to pull colleagues off planned work to fix a major production issue.
Real-world testing
Internal testing has its place, but it is no substitute for putting your application in front of real-world users. Canary deployments are an excellent strategy for conducting small-scale real-world testing without imposing the significant risks of pushing an entirely new application to production.
Quickly improve engagement
Besides offering better technical testing, canary deployments allow you to quickly see how users engage with your new features. Are session lengths increasing? Are engagement metrics rising in the canary? If no bugs are found, get that feature in front of everyone.
There is no need to wait for a more extensive test deployment to complete. Engage those users and get iterating on your next feature.
More data to make business cases
Developers may see the value in their code, but DevOps teams still need to make business cases to leadership and the broader organization when they need more resources.
Canary deployments can quickly show you what demand might be for new features. Conduct a deployment for a compelling new feature on a small group of influencer users to get them talking. Use engagement and publicity metrics to make the case why you want to push a major new initiative tied to that feature.
Stronger risk management
Canary deployments are effectively a series of microtests. Rolling out new features incrementally and verifying them one at a time with canary testing can significantly reduce the total cost of errors or more significant system issues. You’ll never need to roll back a major release, suffer a PR hit, and need to rework a large and unwieldy codebase.
Cons
More overhead
Like any complex process, canary deployments come with some downsides. If you’re going to use a load balancer to partition users, you will need additional infrastructure and need to take on some additional administration.
In this scenario, you create a second production environment and backend that will run alongside your primary environment. You will have two codebases, two app servers, potentially two web servers, and networking infrastructure to maintain.
Alternatively, many DevOps teams use feature flags to manage their canary deployments on a single system. A feature flag can partition users into a canary test at runtime within a single code base. Canary users see the new feature, and everyone else runs the existing code.
Deploying local applications is hard
If you’re developing a locally installed application, you run the risk of users needing to initiate a manual update to get the latest version of your software. If your canary deployment sits in that latest update, your new feature may not get installed on as many client systems as you need to get good test results.
In other words, the more your software runs client-side, the less amenable it is to canary deployments. A full canary release might be a more suitable approach to get real-world test results in this scenario.
Users are still exposed to software issues
While the whole point of a canary deployment is to expose only a few users to a new feature to spare the broader user base, you will still expose end users to less-tested code. If the fallout from even a few users encountering a problem with a particular feature is too significant, then consider skipping this kind of deployment in favor of more rigorous internal testing.
How to perform a canary deployment
Planning out a canary deployment takes a few simple steps:
Identify your canary group
There are several different ways you can select a user group to be your canary.
Random subset
Pick a truly random sampling of different users. While you can do this with a load balancer, feature flag management software can easily route a certain percentage of total traffic to a canary test using a simple modulo.
Early adopters
If you run an early adopter program for highly engaged users, consider using them as your canary group. Make it a perk of their program. In exchange for tolerating bugs they might encounter in a canary deployment, you can offer them loyalty rewards.
By region
You might want to assign a specific region to be your canary. For example, you could set European IPs during late evening hours to go to your canary deployment. You would avoid exposing daytime users to your new features but still get a handful of off-hours user sessions to use as a test.
Internal testers
You can always configure sessions from your internal subnets to be the canary.
Decide on your canary metrics
The purpose of conducting a canary deployment is to get a firm “yes” or “no” answer to the question of whether your feature is safe to push into wider production. To answer that question, you first need to decide what metrics you’re going to use and install the means for monitoring performance.
For example, you may decide you want to monitor:
Internal error counts
CPU utilization
Memory utilization
Latency
You can customize feature management software quickly and easily to monitor performance analytics. These platforms can be excellent tools for encouraging a culture of experimentation.
Decide how to transition from canary to full deployment
As discussed, canary releases should only last on the order of several minutes to several hours. They are not intended to be overly long experiments. Because the timeframe is so short, your team should decide up front how many users or sessions you want in the canary and how you’re going to move to full deployment once your metrics hit positive benchmarks.
For example, you could go with a 5/95 random canary deployment. Configure a feature flag to move a random 5 percent of your users to the canary test while the remaining 95 percent stay on the stable production release. If you see positive results, remove the flag and deploy the feature completely.
Or you might want to take a more conservative approach. Another popular canary strategy is to deploy a canary test logarithmically, going from a 1 percent random sample to 10 percent to see how the new feature stands up to a larger load, then up to a full 100 percent.
Determine what infrastructure you need
Once your team is on the same page about the approach you’ll take, you’ll need to make sure you have all the proper infrastructure in place to make your canary deployment go off without a hitch.
You need a system for partitioning the user base and for monitoring performance. You can use a router or load balancer for the partitioning, but you can also do it right in your code with a feature flag. Feature flags are often more cost-effective and quick to set up, and they can be the more powerful solution.
Canary vs. blue/green deployments
Canary deployments are also sometimes confused with blue/green deployments. Both can use parallel production environments —managed with a load balancer or feature flag— to mitigate the risk of software issues.
In a blue/green deployment, those environments start identical, but only one receives traffic (the blue server). Your team releases a new feature onto the hot backup environment (the green server). Then the router, feature flag, or however you’re managing traffic, gradually shifts new user sessions from blue to green until 100 percent of all traffic goes to green. Once the cutover is complete, the team updates the now-old blue server with the new feature, and then it becomes the hot backup environment.
The way the switchover is handled in these two strategies differs because of the desired outcome. Blue/green deployments are used to eliminate downtime. Canary deployments are used to test a new feature in a production environment with minimal risk and are much more targeted.
Use feature flags for better deployments
When you boil it right down, a feature flag is nothing more than an “if” statement from which users take different code paths at runtime depending on a condition or conditions you set. In a canary deployment, that condition is whether the user is in the canary group or not.
Let’s say we’re running a fledgling social networking site for esports fans. Our DevOps team has been hard at work on a content recommender that gives users real-time recommendations based on livestreams they’re watching. The team has refined the recommendation feature to be significantly faster. It has performed well in internal testing, and now they want to see how it performs under real-world conditions.
The team doesn’t want to invest time and money into installing new physical infrastructure to conduct a canary deployment. Instead, the team decides to use a feature flag to expose the new recommendation engine to a random 5 percent sample of the user base.
The feature flag splits users into two groups with a simple modulo when users load a live stream. Within minutes your team gets results back from a few thousand user sessions with the new code. It does, in fact, load faster and improves user engagement, but there is an unanticipated spike in CPU utilization on the production server. Ops staff realize it is about to degrade performance, so they kill the canary flag.
The team agrees not to proceed with rollout until they can debug why the new code caused the unexpected server CPU spike. Thanks to the real-world test results provided by the canary deployment, they have a pretty good idea of what was going on and get back to work.
Features flags streamline and simplify canary deployments. They mitigate the need for a second production environment. Using feature flag management software like AB Tasty allows sophisticated testing and analysis.
Chad Sanderson breaks down the most successful types of experimentations based on company size and growth ambitions
For Chad Sanderson, head of product – data platform at Convoy, the role of data and experimentation are inextricably intertwined.
At Convoy, he oversees the end-to-end data platform team — which includes data engineering, machine learning, experimentation, data pipeline — among a multitude of other teams who are all in service of helping thousands of carriers ship freight more efficiently. The role has given him a broad overview of the process, from ideation, construction to execution.
As a result, Chad has had a front-row seat that most practitioners never do: The end-to-end process of experimentation from hypothesis, data definitions, analysis, reporting to year-end financials. Naturally, he had a few thoughts to share with AB Tasty’s VP Marketing Marylin Montoya in their conversation on the experimentation discipline and the complexities of identifying trustworthy metrics.
Introducing experimentation as a discipline
Experimentation, despite all of its accolades, is still relatively new. You’ll be hard pressed to find great collections of literature or an academic approach (although Ronny Kohavi has penned some thoughts on the subject matter). Furthermore, experimentation has not been considered a data science discipline, especially when compared to areas of machine learning or data warehousing.
While there are a few tips here and there available from blogs, you end up missing out on the deep technical knowledge and best practices of setting up a platform, building a metrics library and selecting the right metrics in a systematic way.
Chad attributes experimentation’s accessibility as a double-edged sword. A lot of companies have yet to apply the same rigor that they do to other data science-related fields because it’s easy to start from a marketing standpoint. But as the business grows, so does the maturity and the complexity of experimentation. That’s when the literature on platform creation and scaling is scant, leading to the field being undervalued and hard to recruit the right profiles.
When small-scale experimentation is your best bet
When you’re a massive-scale company — such as Microsoft or Google with different business units, data sources, technologies and operations — rolling out new features or changes is an incredibly risky endeavour, considering that fact that any mistake could impact millions of users. Imagine accidentally introducing a bug for Microsoft Word or PowerPoint: The impact on the bottom line would be detrimental.
The best way for these companies to experiment is with a cautious, small-scale approach. The aim is to focus on immediate action, catching things quickly in real time and rolling them back.
On the other hand, if you’re a startup in a hyper-growth stage, your approach will vastly differ. These smaller businesses typically have to show double-digit gains with every new feature rollout to their investors, meaning their actions are more so focused on proving the feature’s positive impact and the longevity of its success.
Make metrics your trustworthy allies
Every business will have very different metrics depending on what they’re looking for; it’s essential to define what you want before going down the path of experimentation and building your program.
One question you’ll need to ask yourself is: What do my decision-makers care about? What is leadership looking to achieve? This is the key to defining the right set of metrics that actually moves your business in the right direction. Chad recommends doing this by distinguishing your front-end and back-end metrics: the former is readily available, the latter not so much. Client-side metrics, what he refers to as front-end metrics, measure revenue per transaction. All metrics then lead to revenue, which in and of itself is not necessarily a bad thing, but that just means all your decisions are based on revenue growth and less on proving the scalability or winning impact of a feature.
Chad’s advice is to start with the measurement problems that you have, and from there, build out your experimentation culture, build out the system and lastly choose a platform.
What else can you learn from our conversation with Chad Sanderson?
Different experimentation needs for engineering and marketing
Building a culture of experimentation from top-down
The downside of scaling MVPs
Why marketers are flagbearers of experimentation
About Chad Sanderson
Chad Sanderson is an expert on digital experimentation and analysis at scale. He is a product manager, writer and public speaker, who has given lectures on topics such as advanced experimentation analysis, the statistics of digital experimentation, small-scale experimentation for small businesses and more. He previously worked as senior program manager for Microsoft’s AI platform. Prior to that, Chad worked for Subway’s experimentation team as a personalization manager.
About 1,000 Experiments Club
The 1,000 Experiments Club is an AB Tasty-produced podcast hosted by Marylin Montoya, VP of Marketing at AB Tasty. Join Marylin and the Marketing team as they sit down with the most knowledgeable experts in the world of experimentation to uncover their insights on what it takes to build and run successful experimentation programs.
Everyone hates tests. Ever since our school days, just hearing the word ‘test’ puts us on high alert and brings nothing but dread.
It seems we cannot escape the word even in software development. And it’s not just any test but a ‘test in production’.
Yes, it is the dreaded phrase that leaves you sweating and your heart pounding. Just reading the phrase may make you envision apocalyptic images of the inevitable disaster that could occur in its wake…
“Test in production” they said. “What could go wrong.” they said
We, too, hate tests but even we have to admit that testing in production is a pretty big deal now. Let us tell you why before you run away in horror…
I don’t always test my code. But when I do, I do it in production.
If it helps, think of it more as an essential part of your software development process and less as an actual ‘test’ where the only two options are pass or fail but for the sake of consistency and clarity, we’ll refer to it here as testing in production and who knows? Maybe by the end of this article, it won’t be so scary anymore!
There is no TEST. PRODUCTION only there is.
So here’s the low-down…
First things first, what is testing in production? Testing in production is when you test new code changes on live users rather than a staging or testing environment.
It may sound downright terrifying when you think about it. So what? You have a feature that is brand new and you’re supposed to unleash it to the wild just like that?
Let us break it down for you with the help of our finest selection of memes about test in production…
At this point, you’re probably vehemently shaking your head. The risks are simply too high for you to consider, especially in this day and age of fickle customers who might leave you at the drop of a hat if you make any simple mistake.
I see you test your code in production. I too like to live dangerously.
You may have a well-established product and you cannot risk upsetting your customers, especially your most loyal customers, and damaging your well-crafted reputation by releasing a potentially buggy feature.
Or you might even just be starting out and you simply cannot afford to make any amateur mistakes.
One does not simply test in production!
Why, oh why, should I test in production?
We’re here to tell you that you should absolutely test in production and here’s your answer as to why:
Testing in production allows you to generate feedback from your most relevant users so that you can adjust and improve your releases accordingly. This means that the end-result is a high-quality product that your customers are satisfied with.
There are no finer QA testers than the clients themselves
Additionally, when you test in production, you have the opportunity to test your ideas and even uncover new features that you had not considered before. Plus, it’s not just engineers who get to do this but your product teams can test out their ideas leading to increased productivity.
I’m just a project manager but sure, I’ll do QA
So now you’re thinking, great but there’s still the issue of it all leading to disaster and disgruntled customers.
But really, it’s not as terrifying as it sounds.
Stand back, we’re trying this in production
Wrap up in a feature flag
When you use feature flags while testing in production, you can expose your new features to a certain segment of your users. That way, not everyone will see your feature and in case anything goes wrong, you can roll back the feature with a kill switch.
What if I told you, you could have both speed and safety
Therefore, you have a quick, easy, and low-risk way to roll out your features and roll back any buggy features to fix them before releasing them to everybody else, lessening any negative impact on your user base if any issues arise.
Be the king (or queen) of your software development jungle
With feature flags, you are invincible. You are in complete control of your releases. All you need to do is wrap up your features in a feature flag and you can toggle them on and off like a light switch!
Gave that switch a flick. Switches love flicks
Still confused? Still feeling a bit wary? If you want to find out more about testing in production, read our blog article and let us show you why it’s very much a relevant process and a growing trend that you need to capitalize on today.
We’ll do it live
With AB Tasty’s flagging functionality, it’s easier than ever to manage testing in production. All you need to do is sit back and reap the benefits.
One of the pioneers of experimentation shares a humbling reality check: Most ideas will fail (and it’s a good thing)
Few people have accumulated as much experience as Ronny Kohavi when it comes to experimentation. His work at tech giants such as Amazon, Microsoft and Airbnb — just to name a few — has laid the foundation of modern online experimentation.
Before the idea of “build fast, deploy often” took hold across tech companies, developers followed a waterfall model that saw fewer releases (sometimes every 2-3 years). The shortening of development cycles in the early 2000s thanks to the Agile methodology and an uptick in online experimentation created the perfect storm for a software development revolution ― and Ronny was at the center of it all.
AB Tasty’s VP Marketing Marylin Montoya set out to uncover the early days of experimentation with Ronny and why failure is actually a good thing. Here are some of the key takeaways from their conversation.
.
Progressive deployments as a safety net
A typical cycle of experimentation involves exposing the test to 50% of the population for an average of two weeks before a gradual release. But Ronny suggests coming at it from a different vantage point: Starting with a small audience of just 2% before ramping up to 50%. The slower ramp-up gives you the time to detect any egregious issues or a degradation in metric values in near real time.
In an experiment, we may focus on just two features, but we have a large set of guardrails that suggest we shouldn’t be degrading X, Y or Z. Statistical data that you’re collecting could also suggest that you’re impacting something you didn’t mean to. Hence, the usage of progressive deployments in which you can identify external factors and easily rollback your test.
It’s like if you’re cooling water: You may realize you’re changing the temperature, but it’s not until you reach 0ºC (32ºF) that ice forms. You suddenly realize that when you get to a certain point, something very big happens. So, deploying at a safe velocity and monitoring the results can lead to huge improvements.
Your great idea? It will most likely fail.
Nothing gives you a better reality check than experimentation at scale. Everyone thinks they’re doing the best stuff in the world until it’s in the hands of their users. That’s when the real feedback kicks in.
Over two-thirds of ideas actually fail to move the metrics that they were designed to improve — a statistic Ronny shares from his time at Microsoft, where he founded the experimentation platform team of more than 100 data scientists, developers and program managers.
Don’t be deterred, however. In the world of experimentation, failing is a good thing. Fail fast, pivot fast. Being able to realize that the direction you’re going in isn’t as promising as previously thought enables you to use those new findings to enrich your next actions.
At Airbnb, Ronny’s experimentation team deployed a lot of machine learning algorithms to improve search. Out of 250 ideas tested in controlled experiments, only 20 of them proved to have a positive impact on the key metrics — meaning over 90% of ideas failed to move the needle. On the flip side, however, the 20 ideas that did succeed in some form? Those resulted in a 6% improvement in booking conversion, worth hundreds of millions of dollars.
The starter kit to experimentation
It’s easier today to convince leadership to invest in experimentation because there are plenty of successful use cases out there. Ronny’s advice is to start with a team that has iteration capital. If you’re able to run more experiments and a certain percentage are pass/fail, this ability to try ideas is key.
Pick a scenario where you can easily integrate the experimentation process into the development cycle and then work your way on to more complex scenarios. The value of experimentation is clearer because deployments are happening more often. If you’re working in a team that deploys every six months, there’s not a lot of wiggle room because everyone has already invested their efforts into this idea that the feature cannot fail. Which, as Ronny pointed out earlier, has a low probability of success.
Is experimentation for every company? The short answer is no. A company has to have certain ingredients in order to unlock the value of experimentation. One ingredient you need is being in a domain where it’s easy to make changes, such as website services or software. A second ingredient is you need enough users. Once you have tens of thousands of users, you can start experimenting and doing it at scale. And lastly, make sure you have trustworthy results from which you are taking your decisions.
What else can you learn from our conversation with Ronny Kohavi?
How experimentation becomes central to your product build
Why experimentation is at the root of top tech companies
The role leaders play in evangelizing an experimentation culture
How to build an environment for true experimentation and trustworthy results
About Ronny Kohavi
Ronny Kohavi is an authority in experimentation, having worked on controlled experiments, machine learning, search, personalization and AI for nearly three decades. Ronny previously was vice president and technical fellow at Airbnb. Prior to that, Ronny led the Analysis and Experimentation at Microsoft’s Cloud and AI group and was the director of data mining and personalization at Amazon. Ronny has also co-authored “Trustworthy Online Controlled Experiments : A Practical Guide to A/B Testing.,” which is currently the #1 best-selling data-mining book on Amazon.
About 1,000 Experiments Club
The 1,000 Experiments Club is an AB Tasty-produced podcast hosted by Marylin Montoya, VP of Marketing at AB Tasty. Join Marylin and the Marketing team as they sit down with the most knowledgeable experts in the world of experimentation to uncover their insights on what it takes to build and run successful experimentation programs.
Statistical significance is a powerful yet often underutilized digital marketing tool.
A concept that is theoretical and practical in equal measures, you can use statistical significance models to optimize many of your business’s core marketing activities (A/B testing included).
A/B testing is integral to improving the user experience (UX) of a consumer-facing touchpoint (a landing page, checkout process, mobile application, etc.) and increasing its performance while encouraging conversions.
By creating two versions of a particular marketing asset, both with slightly different functions or elements, and analyzing their performance, it’s possible to develop an optimized landing page, email, web app, etc. that yields the best results. This methodology is also referred to as two-sample hypothesis testing.
When it comes to success in A/B testing, statistical significance plays an important role. In this article, we will explore the concept in more detail and consider how statistical significance can enhance the A/B testing process.
But before we do that, let’s look at the meaning of statistical significance.
What is statistical significance and why does it matter?
According to Investopedia, statistical significance is defined as:
“The claim that a result from data generated by testing or experimentation is not likely to occur randomly or by chance but is instead likely to be attributable to a specific cause.”
In that sense, statistical significance will bestow you with the tools to drill down into a specific cause, thereby making informed decisions that are likely to benefit the business. In essence, it’s the opposite of shooting in the dark.
Make informed decisions with testing and experimentation
Calculating statistical significance
To calculate statistical significance accurately, most people use Pearson’s chi-squared test or distribution.
Invented by Karl Pearson, the chi (which represents ‘x’ in Greek)-squared test commands that users square their data to highlight possible variables.
This methodology is based on whole numbers. For instance, chi-squared is often used to test marketing conversions—a clear-cut scenario where users either take the desired action or they don’t.
In a digital marketing context, people apply Pearson’s chi-squared method using the following formula:
Statistically significant = Probability (p) < Threshold (ɑ)
Based on this notion, a test or experiment is viewed as statistically significant if the probability (p) turns out lower than the appointed threshold (a), also referred to as the alpha. In plainer terms, a test will prove statistically significant if there is a low probability that a result has happened by chance.
Statistical significance is important because applying it to your marketing efforts will give you confidence that the adjustments you make to a campaign, website, or application will have a positive impact on engagement, conversion rates, and other key metrics.
Essentially, statistically significant results aren’t based on chance and depend on two primary variables: sample size and effect size.
Statistical significance and digital marketing
At this point, it’s likely that you have a grasp of the role that statistical significance plays in digital marketing.
Without validating your data or giving your discoveries credibility, you will probably have to take promotional actions that offer very little value or return on investment (ROI), particularly when it comes to A/B testing.
Despite the wealth of data available in the digital age, many marketers are still making decisions based on their gut.
While the shooting in the dim light approach may yield positive results on occasion, to create campaigns or assets that resonate with your audience on a meaningful level, making intelligent decisions based on watertight insights is crucial.
That said, when conducting tests or experiments based on key elements of your digital marketing activities, taking a methodical approach will ensure that every move you make offers genuine value, and statistical significance will help you do so.
Using statistical significance for A/B testing
Now we move on to A/B testing, or more specifically, how you can use statistical significance techniques to enhance your A/B testing efforts.
Testing uses
Before we consider its practical applications, let’s consider what A/B tests you can run using statistical significance:
Emails clicks, open rates, and engagements
Landing page conversion rates
Notification responses
Push notification conversions
Customer reactions and browsing behaviors
Product launch reactions
Website calls to action (CTAs)
The statistical steps
To conduct successful A/B tests using statistical significance (the chi-squared test), you should follow these definitive steps:
1. Set a null hypothesis
The idea of the null hypothesis is that it won’t return any significant results. For example, a null hypothesis might be that there is no affirmative evidence to suggest that your audience prefers your new checkout journey to the original checkout journey. Such a hypothesis or statement will be used as an anchor or a benchmark.
2. Create an alternative theory or hypothesis
Once you’ve set your null hypothesis, you should create an alternative theory, one that you’re looking to prove, definitively. In this context, the alternative statement could be: our audience does favor our new checkout journey.
3. Set your testing threshold
With your hypotheses in place, you should set a percentage threshold (the (a) or alpha) that will dictate the validity of your theory. The lower you set the threshold—or (a)—the stricter the test will be. If your test is based on a wider asset such as an entire landing page, then you might set a higher threshold than if you’re analyzing a very specific metric or element like a CTA button, for instance.
For conclusive results, it’s imperative to set your threshold prior to running your A/B test or experiment.
4. Run your A/B test
With your theories and threshold in place, it’s time to run the A/B test. In this example, you would run two versions (A and B) of your checkout journey and document the results.
Here you might compare cart abandonment and conversion rates to see which version has performed better. If checkout journey B (the newer version) has outperformed the original (version A), then your alternative theory or hypothesis will be proved correct.
5. Apply the chi-squared method
Armed with your discoveries, you will be able to apply the chi-squared test to determine whether the actual results differ from the expected results.
To help you apply chi-squared calculations to your A/B test results, here’s a video tutorial for your reference:
By applying chi-squared calculations to your results, you will be able to determine if the outcome is statistically significant (if your (p) value is lower than your (a) value), thereby gaining confidence in your decisions, activities, or initiatives.
6. Put theory into action
If you’ve arrived at a statistically significant result, then you should feel confident transforming theory into practice.
In this particular example, if our checkout journey theory shows a statistically significant relationship, then you would make the informed decision to launch the new version (version B) to your entire consumer base or population, rather than certain segments of your audience.
If your results are not labelled as statistically significant, then you would run another A/B test using a bigger sample.
At first, running statistical significance experiments can prove challenging, but there are free online calculation tools that can help to simplify your efforts.
Statistical significance and A/B testing: what to avoid
While it’s important to understand how to apply statistical significance to your A/B tests effectively, knowing what to avoid is equally vital.
Here is a rundown of common A/B testing mistakes to ensure that you run your experiments and calculations successfully:
Unnecessary usage: If your marketing initiatives or activities are low cost or reversible, then you needn’t apply strategic significance to your A/B tests as this will ultimately cost you time. If you’re testing something irreversible or which requires a definitive answer, then you should apply chi-squared testing.
Lack of adjustments or comparisons: When applying statistical significance to A/B testing, you should allow for multiple variations or multiple comparisons. Failing to do so will either throw off or narrow your results, rendering them unusable in some instances.
Creating biases: When conducting A/B tests of this type, it’s common to apply biases to your experiments unwittingly—the kind of which that don’t consider the population or consumer base as a whole.
To avoid doing this, you must examine your test with a fine-tooth comb before launch to ensure that there aren’t any variables that could push or pull your results in the wrong direction. For example, is your test skewed towards a specific geographical region or narrow user demographic? If so, it might be time to make adjustments.
Statistical significance plays a pivotal role in A/B testing and, if handled correctly, will offer a level of insight that can help catalyze business success across industries.
While you shouldn’t rely on statistical significance for insight or validation, it’s certainly a tool that you should have in your digital marketing toolkit.
We hope that this guide has given you all you need to get started with statistical significance. If you have any wisdom to share, please do so by leaving a comment.
In this article, we’ll cover how to implement feature flags in Java using our Java SDK and also discuss other open-source Java frameworks available on Github. If your are using the Spring framework, this article will suit you well.
Overview of the feature flag pattern
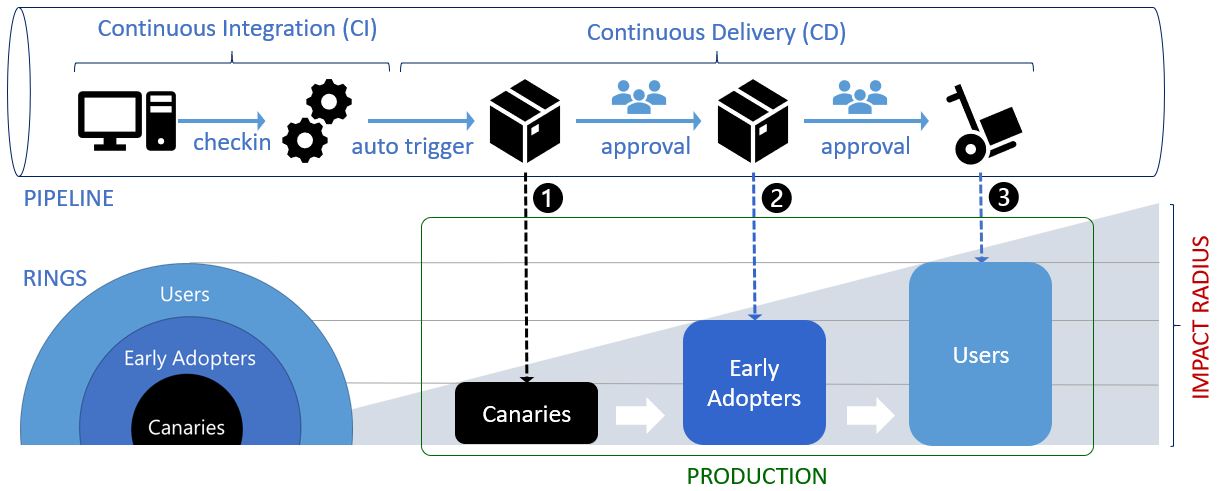
Feature flags are a powerful software development tool that turns certain functionalities on and off without the need to deploy new code, and without any service disruptions. Feature flags can be used for a wide range of purposes, from kill switch to targeted releases (ex: ring deployments, canary deployments), through feature testing. Thus, a feature flag ranges from a simple IF statement to more complex decision trees, which act upon different variables.
As its core, it provides a Decision API to assign and retrieve feature flag values for your users (e.g. what value a flag should be for a specific user), so you don’t have to mess with complex configuration files or manage a dedicated infrastructure to store all the different flag values.
The “Decision” part in the name refers to built-in intelligence that is key to maintain flag values consistency between different user sessions or for instance when an anonymous users gets authenticated to your application.
White this REST API is language-agnostic by design, we provide several server and client-side SDKs. Here, we’ll discuss the Java SDK that includes preconfigured methods to implement the Decision API. Refer to our developer documentation for more details.
Setting feature flags with AB Tasty Java SDK
Using our cloud-based feature management service is a 2- step process. First, in your codebase, you wrap your features once with flags using methods from the Java SDK. Once this is done, you remotely configure your flags (values, segments…) from the dashboard. Let’s see both steps in details.
Setting up the Java SDK
Installation and initialization
First, you need to add the Java repository to your dependency manager. You can use Maven or Gradle build tools to do so:
To initialize and start the SDK, simply call the start function of the class, in the most appropriate location for your application. You need to pass two parameters: your environment id and your API authentication key. Both values are available from the user interface (UI), once you are logged in.
The visitor instance is a helper object that lets you manage the context and campaigns for a user identified by a unique ID.
The user context is a property dataset which defines the current user of your app. This dataset is sent and used by the Decision API as targeting criterias for campaign assignment.
For example, if you want to enable or disable a specific feature based on a VIP status, you would pass this attribute as a key-value pair in the user context so that the Decision API can enable or disable the corresponding feature flag for the user.
The first parameter of the method is the Unique visitor identifier, while the second is the initial user context.
You can also update the visitor context when required. The following method from the Visitor instance allows you to set new context values matching the given keys.
The synchronizeModifications() method of the visitor instance automatically calls the Decision API to run feature flag assignments according to the current user context.
<pre><code class="language-java line-numbers"><!--
Visitor visitor = Flagship.newVisitor("YOUR_VISITOR_ID")
visitor.updateContext("isVip", true)
visitor.synchronizeModifications().whenComplete((instance, error) -> {
// Asynchronous non blocking call
// Synchronization has been completed. Do stuff here...
});
--></code></pre>
Once the campaign has been assigned and synchronized, all the modifications are stored in the SDK. You can retrieve these modifications using the getModification method from the Visitor instance. It retrieves a modification value by its key. If no modification matches the given key or if the stored value type and default value type do not match, default value will be returned.
The getModification method accepts a third argument, that, if set to true will automatically report on our server that the current visitor has seen this specifc variation. It is also possible to call activateModification() later.
Our Universal Collect protocol provides a unified hit format to send data back to our server-side solution for reporting purposes. The format of the hit is based on the Google Analytics measurement protocol. By sending hits to our platform, you can measure the impact of a feature on different metrics such as pageviews, screenviews, transactions or generic events.
To send hits, you must call the sendHit method from the Visitor instance:
<pre><code class="language-java line-numbers"><!--
// Pageview hit
Page page = new Page("https://www.my_domain_com/my_page")
visitor.sendHit(page);
// Sreenview hit
Screen screen = new Screen("screen location")
.withResolution(200, 100)
.withLocale("fr_FR")
.withIp("127.0.0.1")
.withSessionNumber(2);
visitor.sendHit(screen);
// Transaction hit
Transaction transaction = new Transaction("#12345", "affiliation")
.withCouponCode("code")
.withCurrency("EUR")
.withItemCount(1)
.withPaymentMethod("creditcard")
.withShippingCosts(9.99f)
.withTaxes(19.99f)
.withTotalRevenue(199.99f)
.withShippingMethod("1day");
visitor.sendHit(transaction);
// Generic Event hit
Event event = new Event(Event.EventCategory.ACTION_TRACKING, "action")
.withEventLabel("label")
.withEventValue(100);
visitor.sendHit(event);
--></code></pre>
To create a feature flag from the dashboard, apply the following steps:
Go to the dashboard.
Click the + button.
Choose an existing project or create a new one
Click the “Add a use case” button.
You are presented with a list of different templates or use cases (ex: progressive rollout, A/B test…)
Choose the “Feature toggling” template.
Entering the basic information
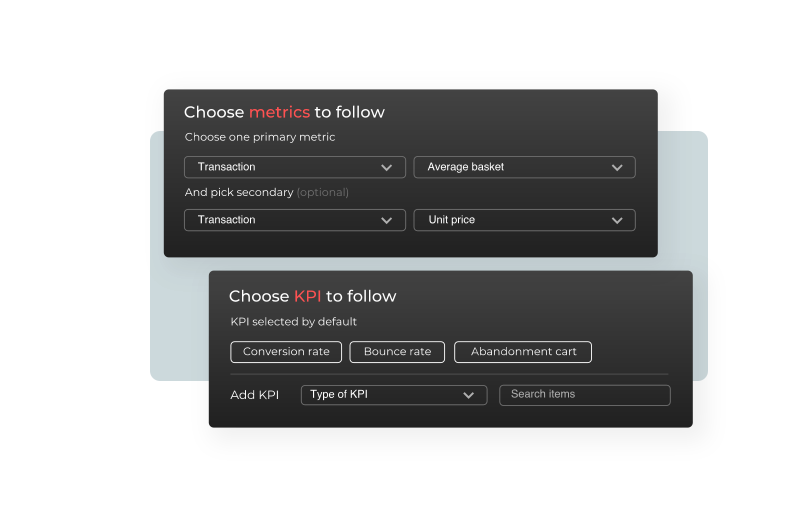
First, you need to enter the basic information of your feature flag use case:
The feature name: use the most representative name for your feature, because this is the one you’ll need to remember in case you want to find it later.
The feature description: explain exactly what your feature deployment is about and what its purpose for your business is.
The primary/secondary metric to follow (optional) which will serve as a point of reference to analyze performance. For more information, refer to Configuring KPIs.
Defining flags
This is where you configure the flags and their values based on your different scenarios. Think of it as the config file mentioned in the first method, but that you manage remotely from the cloud. Important: flag names you specify here should match the ones used in your codebase.
Defining targeting
During this step, you can define which users will be assigned to your different flag values. This is a segmentation engine built into the platform that makes it easy to assign flags conditionally based on user traits (or attributes) that you have access to in your codebase. Refer to this article about feature flag targeting for more information. The 3 following options are available:
All Users if you want all your users to progressively see your feature.
Users by ID if you want only users with a specific ID to see your feature.
Key if you only want users matching this key value to see your feature.
Enabling your feature
Once you have configured your feature, it is OFF by default to allow you to check that it is correctly configured. Back to the dashboard, you can activate your feature ON when you are ready!
And that’s it. Now, provided changes to your codebase have been deployed, you can activate/deactivate feature flags, remotely change their values and have your Java Application react instantly to these changes.
Open-source feature flag frameworks for Java
For the sake of completeness, we list here open source alternatives if you are using Java. While there are pros and cons to each approach, the third-party vendor option is probably the most efficient method for large teams with evolving use cases that don’t want to deal with the challenges of an in-house system.
Keep reading: The Journey of Feature Flag Implementation (Build vs. Buy) where we discuss the pros and cons of different options when it comes to choosing between to build, use an open-source project or buy a feature flag management solution.
FF4J – Feature Flipping for Java
FF4j, is an implementation of the Feature Toggle pattern for Java. It provides a rich set of features:
Enable and disable features at runtime – no deployments.
Enable features not only with flag values but also drive access with roles and groups.
Implement custom predicates to evaluate if a feature is enabled.
Keep your code clean and readable: Avoid nested if statements but use annotations.
Each action (create, update, delete, toggles) can be traced and saved in the audit trail for troubleshooting.
Administrate FF4j (including features and properties) with the web UI.
Wide choice of databases technologies to store your features, properties and events.
(Distributed) Cache Evaluating predicates may put pressure on DB (high hit ratio).
Togglz is another implementation of the Feature Toggles pattern for Java.
Modular setup. Select exactly the components of the framework you want to use. Besides the main dependency, install specific integration modules if you are planning to integrate Togglz into a web application (Servlet environment) or if you are using CDI, Spring, Spring Boot, JSF.
Straight forward usage. Just call the isActive() method on the corresponding enum to check if a feature is active or not for the current user.
Admin console. Togglz comes with an embedded admin console that allows you to enable or disable features and edit the user list associated with every feature.
Activation strategies. They are responsible for deciding whether an enabled feature is active or not. Activation strategies can, for example, be used to activate features only for specific users, for specific client IPs or at a specified time.
Custom Strategies. Besides the built-in default strategies, it’s easy to add your own strategies. Togglz offers an extension point that allows you to implement a new strategy with only a single class.
Feature groups. To make sure you don’t get lost in all the different feature flags, Togglz allows you to define group for feature that are just used for a visual grouping in the admin console.
Unleash is an open-source feature management platform. It provides an overview of all feature toggles/flags across all your applications and services. You first need to setup an Unleash server that you self-host, and then use a client SDK to connect your application to the server. A Java Client SDK is available and provides features such as:
Boolean feature toggles (on/off)
Canary release (Gradual rollout)
Targeted release
Experimentation (A/B testing)
Kill switches
Custom activation strategies
Privacy first (GDPR) where end-user data never leaves your application
Audit logs
Addons integrating with other popular tools (Slack, Teams, Datadog, etc.)
Feature flags, or toggles, as described by Martin Fowler are a “powerful technique, allowing teams to modify system behavior without changing code.” In other words, implementing feature flags as a set of patterns is a robust way to manage code complexity and deliver new features to users using CI/CD (continuous integration/continuous delivery) pipelines, reducing the time to value and decreasing the risk of deploying buggy, error-ridden code to production.
Feature flags are an integral part of deploying software updates via CI/CD pipelines without disrupting existing functionality. There are several ways to implement feature flags in your React apps. Let’s consider three of the most popular and common ways:
The do-it-yourself method where the developer writes the feature flag code from scratch.
The use of open-source libraries that are integrated into the React Single-Page Application (SPA).
Signing up with a cloud based solution (feature flag as a service).
Do it yourself: A simple and free solution
This method requires you to write code, switching feature flags on and off directly in JavaScript. By expanding on this method, let’s consider a simple use case, including code samples from a feature flag React app project, before looking at the primary pros and cons of this method.
1. Setting up the React project
If you already have your React project set up, you can skip to the next section, “Adding new feature flags” otherwise, here is a step-by-step guide to setting up a new project.
The reactjs.org website notes that the create-react-app is the easiest way to develop a new single-page application with React.
Therefore, use the following code to create a new boilerplate app:
npx create-react-app my-app
cd my-app
npm start
2. Adding new feature flags
Now that we have the project created and an empty app template, let’s look at how to add a feature flag in React.
The first step is to create a React js feature flag file with the following format used to create new features. This will act as your config file that you’ll update every time you want to turn on/off a specific feature.
Each feature flag must have a unique name that we can later call or reference in React. A short description is also needed to describe the functionality it adds and an active flag to determine whether the toggle is on or off.
As seen from the code snippet for creating a banner flag, our flags are stored inside an array.
To store these flags in local storage, add the following function to your app.js file and call it at the top of your feature component file.
Note: This will create 3 new feature flags if there are no feature flags created in local storage (localStorage). You also need to use the JSON.stringify () method to convert the JavaScript objects into strings as localStorage can only handle strings.
3. Adding the feature component
In order to reference these feature flags in React and show/hide features based on these feature flags, you need to create a new React component <Feature />. Define it in a file called feature.js and store it in your src folder.
This component accepts 2 props:
the flag name to check against,
the child content to be used (children prop).
The first step is to get the feature from localStorage and see if it is set to active or not. If the feature is active, we can render the feature; otherwise, we return null.
This component will handle the toggling of feature flags on and off. Finally, you just import and render the component where you need.
Pros
There are several advantages to using this method. The most obvious being the fact that when writing your own feature flag code, it is free, easily accessible, and highly available for small React feature toggle projects.
Cons
However, what happens when your application grows in scale, and you need to create and manage several different feature flags, both long- and short-lived?
This is where this method’s disadvantages come to the fore. Succinctly stated, this method is difficult to scale where lots of flags are utilized. And as you can see from the code samples highlighted above, advanced features require more development work which can be challenging and complicated to maintain.
Feature flag open-source libraries for React
The second method is to use existing libraries that you can find on Github. A simple search will lead you to multiple open-source libraries or packages to do feature flagging. Here are a few examples of these packages for React:
Flagged, for instance, provides nice features such as:
Hooks API
High Order Component API
Render Props API
TypeScript Support
Zero Dependencies
Nested Flags
Pros
The advantages of using these open-source libraries are that they are freely available, easy to use, and quick to set up. As described above, all you need to do is consume the libraries into your application and then call the functions created in the library files, passing in variables as required and reading returned variables to understand the state of your feature flags.
Cons
However, as with everything, there are also disadvantages to using open-source feature flag libraries. The most prominent includes the fact that maintenance and evolution are not guaranteed, and the library’s functional scope might not suit your app’s specific requirements. In both cases, a fair amount of refactoring and new code development will have to take place to maintain the existing code and add the features specific to your application.
Feature flag management platforms
The third and last way to implement feature flags in a single-page application is using a dedicated feature flag management 3rd-party service that provides a React integration.
By way of expanding on this statement, let’s look at a step-by-step guide on how to set up feature flags in our server-side solution with the React SDK. As an alternative, you can also directly call the Decision API (REST API), but for the sake of simplicity we’ll use the dedicated SDK that provides additional capabilities out of the box (ex: bucketing). The platform also provides additional SDKs for Java, Python, PHP, .Net, Go, iOS, Android, Flutter…
Using our cloud-based feature management service is a 2- step process. First, in your codebase, you wrap your features once with flags using methods and providers from the React SDK. Once this is done, you remotely configure your flags (values, segments…) from the dashboard.
1. Set up the React SDK in your SPA project and wrap features with flags
Let’s use the same project that we created in the first method (Setting up the project) using our create-react-app boilerplate app.
Install the SDK using NPM or yarn.
npm install @flagship.io/react-sdk
Import the our provider from the React SDK which makes the tool’s features available to the rest of your app. You can wrap your app directly within the app.js file.
The envID and apiKey props are required. You access them from the UI under the “Settings” section. For more information on the different props available, please refer to the API references.
Then, from the React component you want to get access to your flags, import and use one of our React Hook. It gets modifications assigned to the current user as well as further functionalities, such as sending hit tracking, checking the SDK status…
You can refer to this short video that goes through all the process of a feature flag setup or read the detailed instructions below.
Creating your feature flag use case
To create a feature flag from the dashboard, apply the following steps:
Go to the dashboard.
Click the + button.
Choose an existing project or create a new one
Click the “Add a use case” button.
You are presented with a list of different templates or use cases (ex: progressive rollout, A/B test…)
Choose the “Feature toggling” template.
Entering the basic information
First, you need to enter the basic information of your feature flag use case:
The feature name: use the most representative name for your feature, because this is the one you’ll need to remember in case you want to find it later.
The feature description: explain exactly what your feature deployment is about and what its purpose for your business is.
The primary/secondary metric to follow (optional) which will serve as a point of reference to analyze performance. For more information, refer to Configuring KPIs.
Defining flags
This is where you configure the flags and their values based on your different scenarios. Think of it as the config file mentioned in the first method, but that you manage remotely from the cloud. Important: flag names you specify here should match the ones used in your codebase (“btnColor” in your code example above).
Defining targeting
During this step, you can define which users will be assigned to your different flag values. This is a segmentation engine built into the platform that makes it easy to assign flags conditionally based on user traits (or attributes) that you have access to in your codebase. Refer to this article about feature flag targeting for more information. The 3 following options are available:
All Users if you want all your users to progressively see your feature.
Users by ID if you want only users with a specific ID to see your feature.
Key if you only want users matching this key value to see your feature.
Enabling your feature
Once you have configured your feature, it is OFF by default to allow you to check that it is correctly configured. Back to the dashboard, you can activate your feature ON when you are ready!
And that’s it. Now, provided changes to your codebase have been deployed, you can activate/deactivate feature flags, remotely change their values and have your React App react instantly to these changes.
Last thoughts
This article describes three ways of implementing feature flags in a React SPA (single-page application):
the do-it-yourself method,
using open-source libraries,
signing up with a dedicated feature management platform.
While there are pros and cons to each approach, the third-party vendor option is probably the most efficient method for large teams with evolving use cases that don’t want to deal with the challenges of an in-house system. For more details, read our article The Journey of Feature Flag Implementation.
Any business selling products or services online has a conversion funnel — but not everyone realizes it. If you’re unsure what a conversion is or how you can refine yours to sell more online, you’re in the right place. In this post, we’re going to take you through everything you need to know about conversion funnels. We’ll start with the basics — what conversion funnels are and the three key stages — before moving on to some of the most effective strategies to improve your funnels to increase sales. Let’s get stuck in!
In this article, we’ll cover:
[toc]
What is a conversion funnel?
A conversion funnel is a process that takes potential customers on a journey towards buying your products or services. They’re the cornerstone of all e-commerce business models, guiding potential customers from the moment they first become aware of your brand to the moment they make a purchase and beyond.
If you’re new to conversion funnels, think about the shape of a funnel — it’s wider at the top and narrower at the bottom. This represents the flow of people through your marketing strategy. Not everyone who becomes aware of your business will go on to become a paying customer. It’s like brewing coffee using a drip filter — a large volume of coffee grounds go into the top of the brewing equipment and then the funnel filters the high-quality stuff out of the bottom into your mug. A sales funnel works in the same way. The goal is to get as many relevant leads into the top of the funnel as possible, filtering out unsuitable prospects to leave your ideal customers ready to buy from you.
When you optimize your conversion funnel, you maximize the impact of your online marketing strategy and boost sales. This isn’t a once-and-done exercise, but something you need to continually refine throughout your business life. Do you want to know how to do it?
What’s the difference between a conversion funnel and a sales funnel?
The terms conversion funnel and sales funnel are often used interchangeably, but are they the same thing? The answer to this question is no, although they are closely related. A sales funnel typically starts when a potential customer enters the sales pipeline. This can happen online (in an e-commerce environment) as well as offline. However, a prospect typically doesn’t enter your sales funnel until they’re already familiar with your brand and your products or services.
It can take a while to get to this point in the online world, particularly if you’re targeting people who have never heard of your brand before. It takes time to build a connection and trust with your audience.
This is where a conversion funnel comes in. Here, the focus isn’t just on making a sale. It’s about making a connection with your audience, generating leads, and then taking those leads on a journey with your company. Potential customers might come into your funnel cold, without much awareness of who you are or what you do. Over time, your funnel will warm them up, build trust in your offer, and get them ready to buy. It encapsulates the whole process — from the first contact through to purchasing.
The three conversion funnel stages
There are many different conversion funnel models out there. All of them broadly suggest the same thing: breaking the process down into several conversion funnel stages the leads must travel through before making a purchase. Although a customer may enter or exit the funnel at any stage, your personalized model sets out how you intend customers to connect with your business.
The exact model will look different for every organization, but here are the three stages we suggest you follow.
Stage 1: Building awareness at the top of the funnel
The top of the funnel is all about making people aware of your brand and capturing leads. This stage is arguably the most crucial. If you don’t get people into your funnel, how are you going to sell to them? This critical step is often referred to as the awareness stage, and the exact strategy you use to do this will depend on your ideal customer. Who are they? Where do they hang out? What are their fundamental problems and challenges? Why would they be interested in what you have to offer them? The answers to these questions can provide useful directions during the awareness stage. Remember: this isn’t about you; it’s about the customer. Here are a few things that should be happening at the top of the funnel.
Content marketing
To grab attention online, you’re going to need content. This content can take many forms, so it’s essential to think about the types of content your audience is most likely to consume. For example, TikTok videos will likely appeal to 18 to 24-year-olds, but they might not be the best option if you’re targeting an older demographic.
You should consider both onsite and offsite content when outlining your content marketing strategy. An effective conversion funnel needs both. Offsite content helps capture attention and attract people to your website. In contrast, onsite content engages your audience and encourages them to take the next step, such as signing up for your mailing list.
Marketing campaigns
Alongside your content marketing strategy, you should also consider the marketing campaigns you will be running to get people to engage with this content. How will you get your content seen? How will you capture users’ attention? Are you only operating online, or will you use offline marketing to generate leads?
Often, e-commerce businesses are quick to dismiss offline marketing campaigns as irrelevant. However, highly targeted offline campaigns can be extremely useful. The online marketplace is crowded! If you can think of innovative ways to reach your audience offline and direct them to your online content, it could turn out to be a cost-effective way to generate leads for your conversion funnel.
You could also consider how you might automate some of your marketing campaigns. Creating evergreen campaigns that can run in the background while you and your employees focus on other tasks is useful to maximize profits. In essence, it means you can be generating leads for your business while you sleep.
Lead capture
Lead capture is the final step of the awareness stage. It’s where you move your prospects from the top of your conversion funnel to the middle. Once you’ve directed a potential customer to your website and encouraged them to engage with your content, what’s next? Each piece of content your audience engages with on your website should have a call to action — something that tells them what action to complete next.
To achieve this, you might want to consider a lead magnet. This can be something as simple as a discount code. But, for maximum results, you could develop something that helps solve a problem directly related to the product or service you’re offering.
Not only does this ensure you’re capturing highly qualified leads, but it also means people are likely to sign up even when they’re not ready to make a purchase. Given the point of a conversion funnel is to get them ready to buy from you, this is a vital point to consider when outlining your content marketing strategy.
Once you have that email address, it’s time to move on to the second stage of the conversion funnel: nurturing your audience to build desire for your products or services.
To maximize the number of leads you’re capturing, you should focus your stage one activities across a range of digital marketing channels. Here are some of the most popular options:
Social media
Given there are almost 4 billion social media users worldwide (over half the world’s population), it’s no surprise social media marketing is one of the most popular ways to generate leads. That said, it’s important to note it isn’t an easy option! Many business owners expect social media to be a fast and cheap way to grow an audience. Still, it takes time and persistent effort to get results — just like any other marketing strategy.
Work with a professional to develop a social media marketing plan that helps you stand out from the crowd. Many businesses use social media to attract people into their conversion funnel, but few do it well.
Paid search
What’s the first place you turn to when you need information? It’s estimated there are around 2 trillion Google searches every year — so advertising your content on Google could potentially be very lucrative! Unlike social media marketing, people using search engines are actively looking for the information you’re providing. To get the best click-through rate, make sure the phrases you’re targeting are directly relevant to the content. And test campaigns with a small budget before increasing your spending.
Organic search
It’s also a good idea to optimize your content for organic search. While this isn’t a short-term strategy, Search Engine Optimization (SEO) can deliver large volumes of traffic to your website over time. Focus on creating evergreen content — content that doesn’t become irrelevant or outdated and can appear in organic searches for many years to come. When you gain website visitors organically from search engines, you improve your ability to build a list of qualified leads, improving the quality of people entering your conversion funnel.
Stage 2: Nurturing your audience
Many online businesses make the fundamental mistake of pushing for a sale too soon. While you can (and should) always have an option for potential customers to buy from you on their terms, you should design your conversion funnel to nurture your leads, building trust with your brand before moving them into the sales pipeline.
Staying in contact
Once a potential customer has told you they want to hear more from you, it’s essential to stay in touch with them. If you can, you should aim to use multiple channels to do this. Encourage them to follow you on social media, re-target them with relevant online content, and send them regular emails. Research consistently shows the more opportunities a potential customer has to engage with your brand online, the more likely they will buy from you.
In short, it’s not enough to let people know you exist. If you want to sell to them, you need to put in the work to keep them engaged!
Positioning your products and services
As you stay in touch and nurture your audience, you should also ensure each lead is familiar with your products and services. This step isn’t about pushing for the sale — we’ll come back to this in the next stage — but you should be introducing your offering interestingly and engagingly. Essentially, we need your leads to be ready to make a purchase when you deliver your sales pitch. To get to this stage, they need to know what you’re selling.
Building a desire to buy
And finally, throughout the nurturing stage, you should be gearing up your audience to perform the desired action. In most cases, this is completing a purchase. How do you do this? Use emotion.
Humans are emotional beings. Remember earlier when we discussed the problems and challenges your product or service can solve for your customers? What are the emotions behind that problem? Aim to appeal to these emotions when engaging with your audience, and make it clear that you’re here to help them overcome these feelings to foster more positive and desirable emotions. How will your product or service make them feel? Can you impart some of these feelings with your content?
As well as feeling emotion, people have an inbuilt desire to be understood. The more you can show them you understand them, the more they will connect with your brand, and the more desire they will have to do business with you.
Throughout this step, you should be keeping your competitors in mind, especially if you’re operating in a competitive niche. Why should your audience choose you above your competition?
Stage 3: Convert potential customers into paying customers
Stage three is what it’s all about — securing the sale. Without this stage, your business is nothing — without paying customers, you have no profits. But we hope you now appreciate why it’s important to take your audience on a journey through the preceding stages before you attempt to convert them. Once you’ve optimized your funnel, your leads will now be ready to buy from you.
Continue to nurture leads
It’s crucial to be aware of this: you don’t stop nurturing your prospects once you get them to the end of your funnel. This stage should continue as long as your leads — and eventual customers — are in contact with your business.
Work at your potential customer’s pace
It’s also important to remember your potential customers will all travel at their own pace. Some will be ready to make a purchase sooner than others. For this reason, you should think of your conversion funnel as a process. It isn’t about throwing leads in at one end and spitting them out at the other side but about fostering connections that will help your organization thrive over time.
If you attempt to trigger a sale, but your customers aren’t ready, you should continue to engage and nurture them — and try again further down the line. Similarly, if none of your prospects are buying from you at this stage in your conversion funnel, it’s a sign something needs tweaking — we’ll get back to this in a little while.
Trigger a Sale
Now it’s time to encourage your leads to become paying customers, but how should you do it? As always, there are many options here. Finding the right approach will likely involve some trial-and-error. It’s a good idea to test out a few sales tactics and see what works. For some, a simple email or retargeting campaign on social media might do the trick. But for other businesses, you might need to come up with something more personal or creative.
What makes a good call-to-action?
Calls-to-action are the lifeblood of any effective conversion funnel. But how can you make sure yours are effective? Here are some tips to get you started.
Be clear and concise
Your call-to-action shouldn’t be too wordy. It would be best if you were direct. Use short sentences and tell your audience exactly what you want them to do. Use verbs like “buy,” “shop,” or “download.” Telling someone to “shop the new collection” is likely to result in more sales than something like “our new collection is now live on our website.”
Ask yourself why
As you develop your call-to-action, put yourself in your potential customer’s shoes. Why should they do what you’re asking them to? This is where the copy in the rest of your sales pitch comes in. The call-to-action is the final piece of the puzzle. By the time your lead gets to this part of your content, they should already be ready to hit that button. Make it a no-brainer for them.
The role of the shopping cart
The shopping cart on your website can be one of your biggest assets for driving sales. Did you know you can follow up on abandoned carts with your email subscribers? If not, you’re missing out on one of the most effective conversion tools available to e-commerce businesses. Research suggests around 70% of all shopping carts are abandoned online. Think about it: these are leads that have been through the conversion funnel and are almost ready to make a purchase. What is it that stopped them? It might have been something as simple as an interruption. Get back in touch and ask them if they’re ready to complete their purchase. The results may surprise you.
Evaluating your funnel with conversion funnel metrics
As we mentioned at the start of this post, a conversion funnel isn’t something you can create and then forget about. It’s an ongoing, interactive process that you must refine over time. The digital marketing world is dynamic and ever-changing — and your conversion funnel will need to evolve alongside industry trends and technological advances. Evaluating your funnel is an essential part of this, enabling you to improve each stage of the process to generate more qualified leads and convert more of them into paying customers.
Your first step should be to set up Google Analytics to track your conversion funnel. When you do this, you can track a lead from the moment they join your funnel until they make a purchase. This gives you an overview of how well your funnel is performing, as well as helping you access some of the key conversion funnel metrics that help you decide what to focus on next, such as:
Cost per acquisition (CPA)
Marketing costs money and the expenses associated with your conversion funnel can quickly mount up. It’s vital to understand the benefit these investments bring. What is the return on investment (ROI) associated with your conversion funnel? To understand this, you need to calculate your cost per acquisition. To calculate this, divide the costs associated with your conversion funnel by the number of paying customers the funnel generated in the same time period. For example, if you invested $500 and generated 10 paying customers, your CPA would be $50.
You can then compare this with the average spend to figure out whether your conversion is profitable or not. Using the example above, if the average customer spends $200, your funnel is profitable. On the other hand, if the average lifetime spend is $20, the funnel is operating at a loss.
Conversion rate
Google Analytics calculates your funnel’s conversion rate by working out how many of the visitors went to the goal page (e.g., “thank you for your purchase”) as well as one of the pages associated with the earlier stages of your conversion funnel. This provides you with useful insight into how well your funnel is working over time, which can help you evaluate any changes that you make to optimize the funnel.
Are you ready to optimize your funnel?
In summary, conversion funnels are an essential asset to all e-commerce businesses. If you want to improve sales, optimizing your funnel is often the best place to start. What steps will you take after reading this post?