When you hear ‘A/B Testing’, do you think straight away of revenue gain? Uplift? A dollars and cents outcome?
According to David Mannheim, CEO of the Conversion Rate Optimization (CRO) agency User Conversion, you probably do – and shouldn’t. Here’s why:
Unfortunately, it’s just not that simple.
Experimentation is more than just a quick strategy to uplift your ROI.
In this article we will discuss why we experiment, the challenges of assessing return on investment (ROI), prioritization, and what A/B testing experimentation is really about.
Why do we experiment?
Technically speaking, experimentation is performed to support or reject a hypothesis. Experimentation provides you with valuable insights into cause-and-effect relationships by determining the outcome of a certain test when different factors are manipulated in a controlled setting.
In other words, if there is no experiment, there is no way to refute a hypothesis and reduce the risk of losing business or negatively impacting metrics.
Experimentation is about prioritization, minimizing risk and learning from the outcome. The tests you choose to implement should be developed accordingly. It’s not necessarily about making the “right” or “wrong” decision, experimentation helps you make better decisions based on data.
In visual terms, experimentation will look something like this:
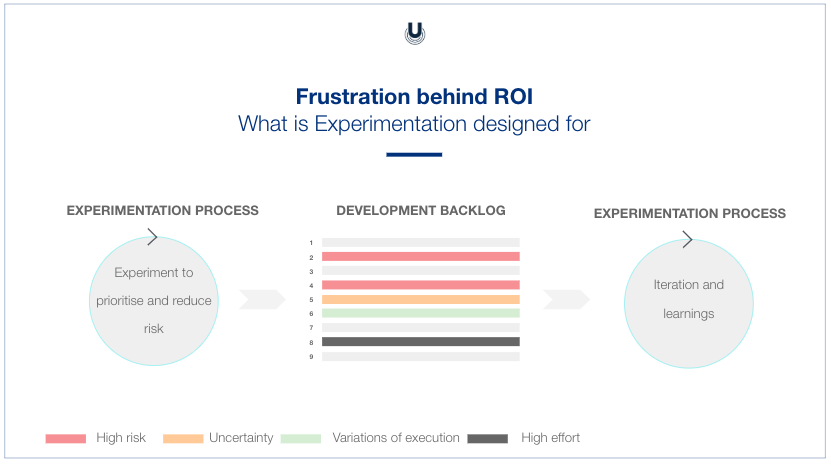
Online experiments in the business world must be carefully designed to learn, accomplish a specific purpose, and/or measure a key performance indicator that may not have an immediate financial effect.
However, far too often it’s the key stakeholders (or HIPPOs) who decide what tests get implemented first. Their primary concern? The amount of time it will take to see a neat revenue uplift.
This tendency leads us to the following theory:
The ROI of experimentation is impossible to achieve because the industry is conditioned to think that A/B testing is only about gain.
Frustrations and challenges of ROI expectations
You may be asking yourself at this point, What’s so bad about expecting revenue uplift from A/B tests? Isn’t it normal to expect a clear ROI?
It is normal, however, the issue isn’t just that simple.
We’ve been conditioned to expect a neat formula with a clean-cut solution: “We invested X, we need to get Y.”
This is a misleading CRO myth that gets in the way.
Stakeholders have come to erroneously believe that every test they run should function like this – which has set unrealistic ROI expectations for conversion optimization practitioners.
As you can imagine, this way of thinking creates frustration for those implementing online experimentation tests.
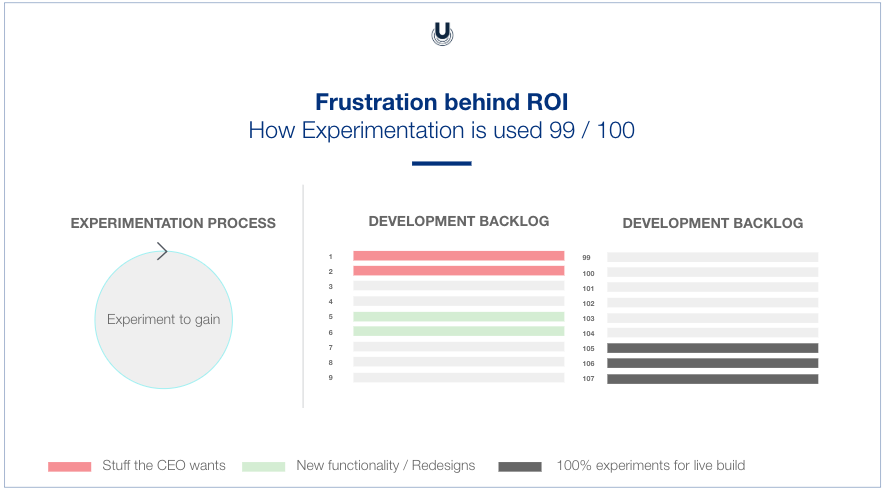
What people often overlook is the complexity of the context in which they are running their experimentation tests and assessing their ROI.
It’s not always possible to accurately measure everything online, which makes putting an exact number on it next to impossible.
Although identifying the impact of experiments can be quite a challenge due to the complexity of the context, there are some online tools that exist to measure your ROI efforts as accurately as possible.
AB Tasty is an example of an A/B testing tool that allows you to quickly set up tests with low-code implementation of front-end or UX changes on your web pages, gather insights via an ROI dashboard, and determine which route will increase your revenue.

Aside from the frustration that arises from the ingrained ROI expectation to be focused on immediate financial improvement, three of the biggest challenges of the ROI of experimentation are forecasting, working with averages, and multiple tests at once.
Challenge #1: Forecasting
The first challenge with assessing the ROI of experimentation is forecasting. A huge range of factors impacts an analyst’s ability to accurately project revenue uplift from any given test, such as:
- Paid traffic strategy
- Online and offline marketing
- Newsletters
- Offers
- Bugs
- Device traffic evolution
- Season
- What your competitors are doing
- Societal factors (Brexit)
In terms of estimating revenue projection for the following year from a single experiment– it’s impossible to predict an exact figure. It’s only possible to forecast an ROI trend or an expected average.
Expecting a perfectly accurate and precise prediction for each experiment you run just isn’t realistic – the context of each online experimentation test is too complex.
Challenge #2: Working with averages
The next challenge is that your CRO team is working with averages – in fact, the averages of averages.
Let’s say you’ve run an excellent website experiment on a specific audience segment – and you experienced a high uplift in conversion rate.
If you then take a look at your global conversion rate for your entire site, there’s a very good chance that this uplift will be swallowed up in the average data.
Your revenue wave will have shrunk to an undetectable ripple. And this is a big issue when trying to assess overall conversion rate or revenue uplift – there are just too many external factors to get an accurate picture.
With averages, the bottom line is that you’re shifting an average. Averages make it very difficult to get a clear understanding.
On average, an average customer, exposed to an average A/B test will perform… averagely.
Challenge #3: Multiple tests
The third challenge of ROI expectations happens when you want to run multiple online experiments at one time and try to aggregate the results.
Again, it’s tempting to run simple math equations to get a clear-cut answer for your gain, but the reality is more complicated than this.
Grouping together multiple experiments and the results of each experiment will provide you will blurred results.
This makes ROI calculations for experimentation a nightmare for those simultaneously running tests. Keeping experiments and their respective results separate is the best practice when running multiple tests.
Should it always be “revenue first”?
Is “revenue first” the best mentality? When you step back and think about it, it doesn’t make sense for conversion optimizers to expect revenue gain, and only revenue gain, to be the primary indicator of success driving their entire experimentation program.
What would happen if all businesses always put revenue first?
That would mean no free returns for an e-commerce site (returns don’t increase gain!), no free sweets in the delivery packaging (think ASOS), the most inexpensive product photographs on the site, and so on.
If you were to put immediate revenue gain first – as stakeholders so often want to do in an experimentation context – the implications are even more unsavory.
Let’s take a look at some examples: you would offer the skimpiest customer service to cut costs, push ‘buy now!’ offers unendingly, discount everything, and forget any kind of brand loyalty initiatives. Need we go on?
In short, focusing too heavily on immediate, clearly measurable revenue gain inevitably cannibalizes the customer experience. And this, in turn, will diminish your revenue in the long run.
What should A/B testing be about?
One big thing experimenters can do is work with binomial metrics.
Avoid the fuzziness and much of the complexity by running tests that aim to give you a yes/no, black or white answer.

Likewise, be extremely clear and deliberate with your hypothesis, and be savvy with your secondary metrics: Use experimentation to avoid loss, minimize risk, and so on.
But perhaps the best thing you can do is modify your expectations.
Instead of saying, experimentation should unfailingly lead to a clear revenue gain, each and every time, you might want to start saying, experimentation will allow us to make better decisions.
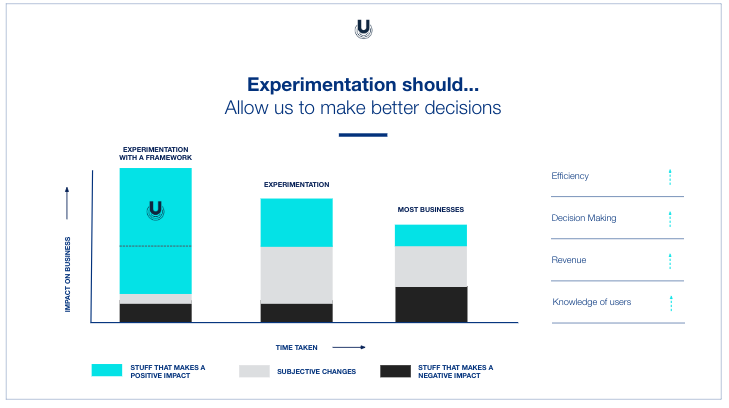
These better decisions – combined with all of the other efforts the company is making – will move your business in a better direction, one that includes revenue gain.
The ROI of experimentation theory
With this in mind, we can slightly modify the original theory of the ROI of experimentation:
The ROI of experimentation is difficult to achieve and should be contextualized for different stakeholders and businesses. We should not move completely away from a dollar sign way of thinking, but we should deprioritize it. “Revenue first” is not the best mentality in all cases- especially in situations as complex as calculating the ROI of experiments.





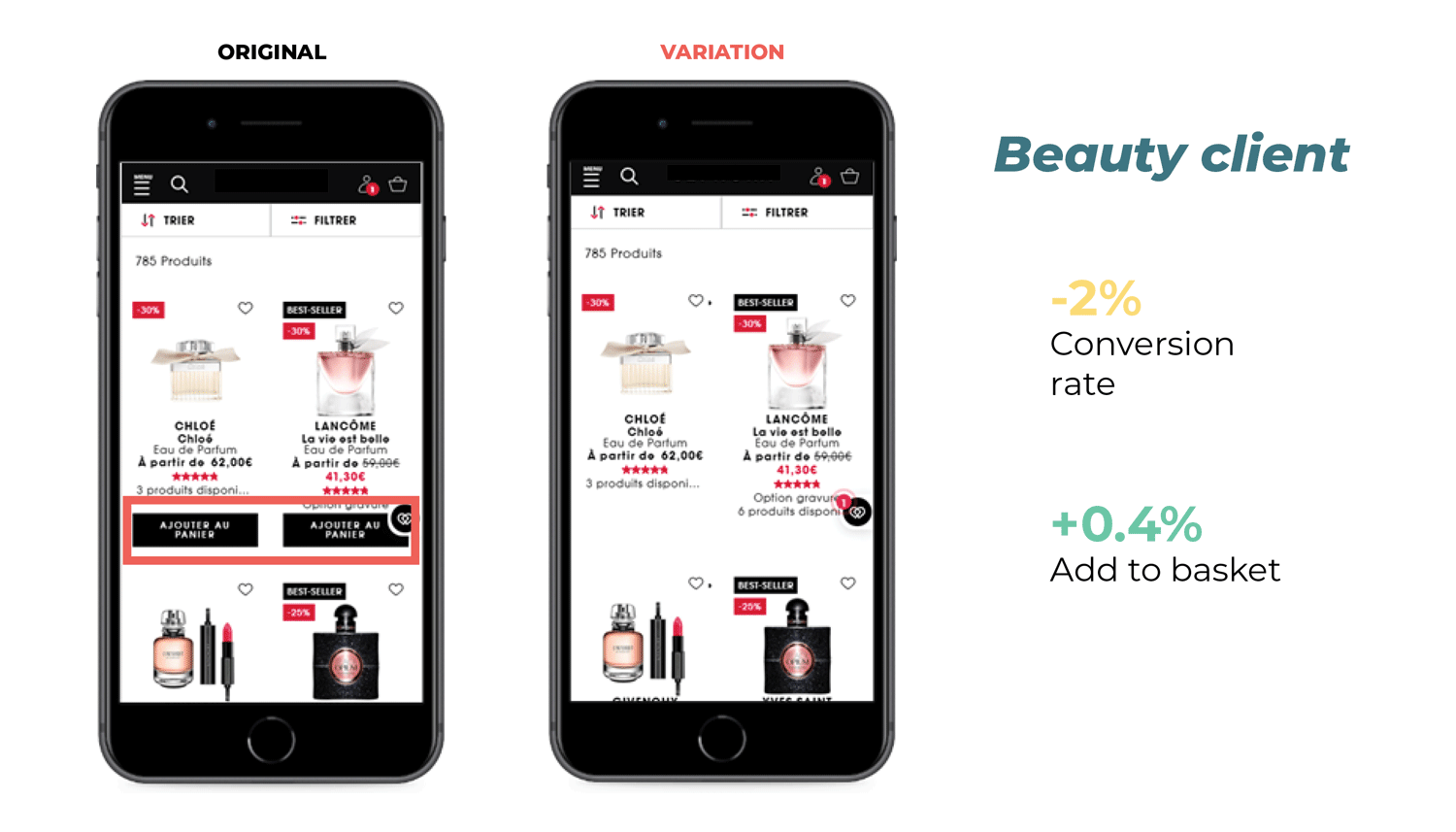

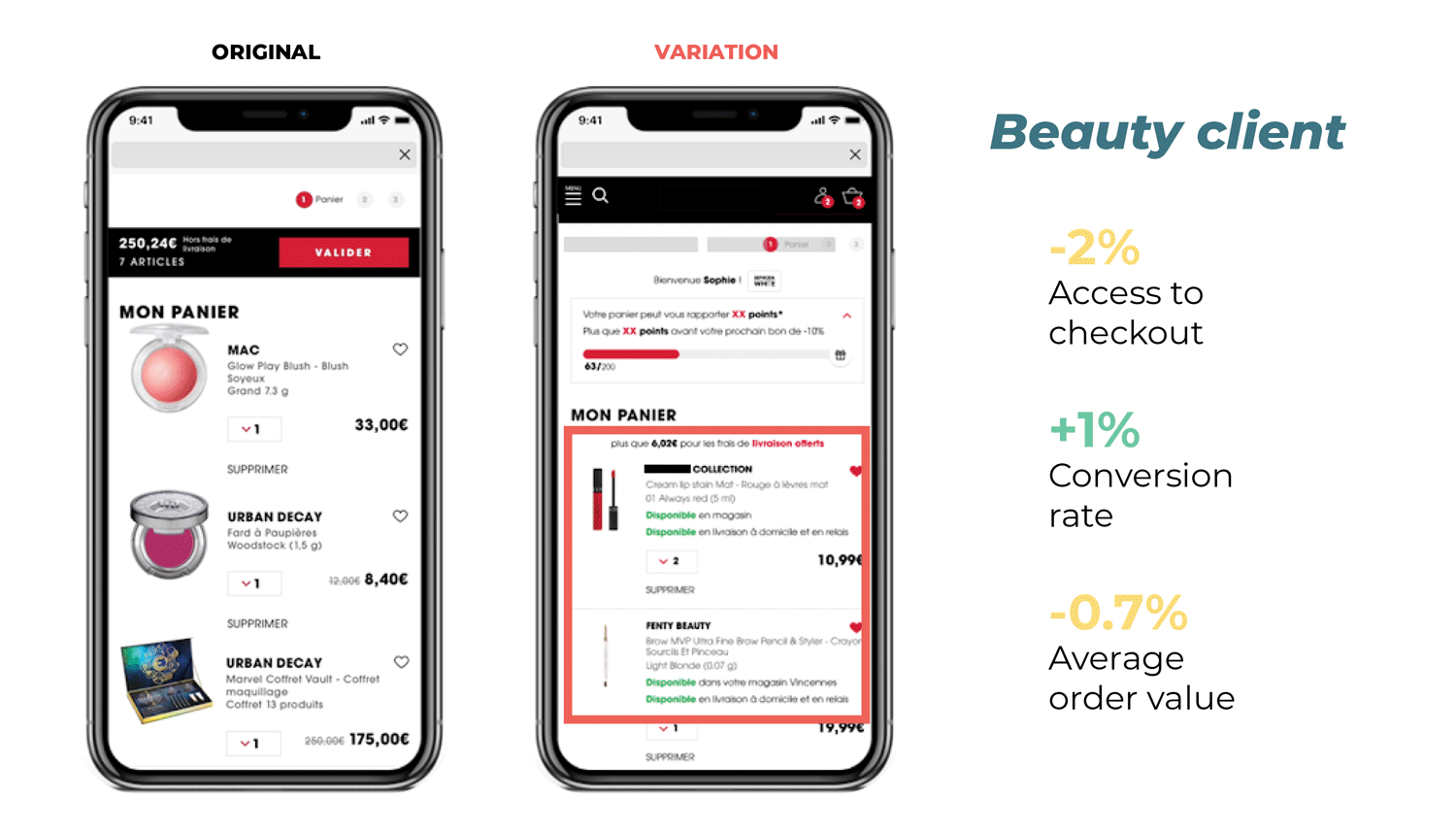






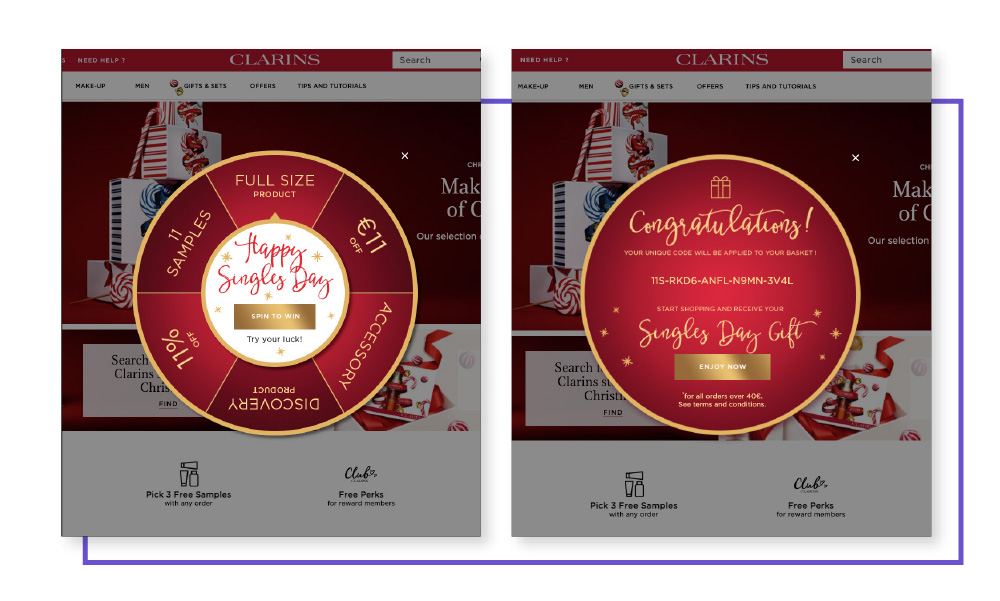 Clarins delivered a customer experience on par with their clients’ expectations (
Clarins delivered a customer experience on par with their clients’ expectations (









 Chad Sanderson (Convoy)
Chad Sanderson (Convoy) Jonny Longden (Journey Further)
Jonny Longden (Journey Further)