As we go deeper into digital transformation and as companies move towards large-scale globally distributed systems, the complexity that comes with them increases. This means that failures in these intricate systems become much harder to predict, as opposed to traditional, monolithic systems.
Yet, these failures could result in high costs for teams to repair them; not to mention the painstaking probability of the potential loss of new and existing customers.
The question then is how can we build confidence in the systems that we put into production? How can teams make sure that they’re releasing stable and resilient software that can handle any unpredictable conditions that they’re put into?
This is when teams turn to what is aptly referred to as “chaos engineering”.
What is chaos engineering?
According to the Principles of Chaos, chaos engineering is “the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production.”
In other words, chaos engineering is the process of testing distributed systems to ensure that it can withstand turbulent conditions and unexpected disturbances. Strictly speaking, this is the “chaos” of production.
Chaos engineering is particularly applicable to large-scale, distributed systems. Since such systems are now hosted on globally distributed infrastructures, there are many complex dependencies and moving parts with several points of failure. This makes it harder to predict when an unexpected error will occur.
Due to the unpredictability of these failures of the components of the system, it becomes harder to test for them in a typical software development life cycle.
This is when the concept of chaos engineering came about as a way to predict and test for such failures and uncover hidden flaws within these systems.
In other words, this concept determines the resilience of these systems by identifying their vulnerabilities by carrying out controlled experiments to test for any unpredictable and unstable behavior.
This is done by breaking things on purpose by injecting failure and various types of faults into the system to see how it responds. This will help determine any potential outages and weaknesses in the system.
The ultimate goal of this is a lesson in how to build more resilient systems.
Where does the term come from?
Before we delve any deeper into chaos engineering, it would be helpful to understand where this concept originated.
Chaos engineering started in 2010 when the engineering team at Netflix decided to develop “Chaos Monkey”, which was later made open source, as the team at Netflix migrated from a monolithic architecture to the cloud, deployed on AWS.
For Netflix, this migration to hundreds of microservices brought on a high amount of complexity; therefore, engineers at Netflix were seeking a better approach to prevent sudden outages in the system.
These engineers were mainly looking for a way to disable instances and services within their architecture to ensure that their system can handle such failures with minimal impact on the user experience, allowing them to build a more resilient and reliable architecture.
The idea behind the Chaos Monkey tool was that they would unleash a “wild monkey” to break down individual components in a carefully monitored environment to make sure that a breakdown in this single component wouldn’t affect the entire system.
This, in turn, helped them locate the weaknesses in the system and build automatic recovery plans to address them and alter the system if necessary so that it could easily tolerate unplanned failures in the future.
Afterwards, Chaos Monkey improved and evolved to allow Netflix engineers to more precisely determine failures by testing against more failure states, enhancing the resilience of their system.
From then on, the chaos journey began for Netflix and later on for many organizations dealing with similar distributed systems.
Principles of chaos engineering
We can deduce that chaos engineering involves running experiments to understand how a distributed system behaves when faced with failure.
Unlike other forms of testing, chaos engineering involves experimentation and learning new things about a system by creating a hypothesis and attempting to prove that hypothesis. If it’s not true, this is a chance to learn something new about the system.
Testing, on the other hand, involves making an assumption about a system based on existing knowledge and determining whether it’s true or not by running tests; in other words, the test is conducted based on knowledge of specific properties about the system. The results, therefore, don’t provide new insights or information.
Chaos engineering, for its part, involves exploring scenarios that don’t usually occur during testing designed to gain new knowledge about the system by considering factors that often go beyond the obvious issues that are normally tested for.
The following principles provide a basis on which to run such experiments on your system:
- Plan an experiment
The first step involves planning an experiment, where you will need to pinpoint things that could go wrong. This will require gaining an understanding of your system’s normal behavior and determining what constitutes a normal state. Afterwards, you start off by forming a hypothesis of how you think the components of your system will behave in case something goes wrong and then create your control and experimental groups accordingly.
Defining a metric to measure at this stage is useful to gauge the level of normalcy within your system. These could include metrics such as error rates or latency.
- Design real-world events
At this stage, you will outline and introduce real-world events that could potentially cause disruptions to your system such as those that occur within hardware or server or any other external event that could lead to outages in your system such as a sudden spike in traffic, hardware failures, network latency or any event that could potentially disrupt the steady state of the system.
- Run the experiment
After defining your system’s normal behavior and the events that could disrupt it, experiments can then be run on your system preferably in a production environment to measure the impact of the failure to gain a better understanding of your system’s real-world behavior.
This will also allow you to prove or disprove your hypothesis. The harder it is to cause an outage in the system, the more confident you can be in your system’s resilience.
However, keep in mind that since your experiments are run in production, it’s important to minimize the blast radius in case something goes wrong. This will ensure that any adverse effects are kept at a minimum and if things go smoothly, you can then gradually increase this radius till it reaches full scale. It’s also wise to have a roll back plan if something does go wrong.
- Monitor results
The experiment should give you a clear idea of what’s working and of what needs to be improved by looking for a difference between the control and experimental group. Teams can then make the necessary changes as they’re able to identify what led to the outage or disruption to the service, if relevant.
Why we should break things on purpose: Benefits of chaos engineering
We can look at chaos engineering as a sort of safeguard that helps prevent worst case scenarios from happening and impacting the user experience before they actually happen.
Consequently, chaos engineering has a number of benefits.
Increased reliability and resilience
As we’ve already mentioned, running such controlled chaos experiments will help determine your system’s capabilities, thereby preparing the system against unexpected failures.
Information gathered from these experiments can be used to strengthen your system and increase its resilience by locating potential weaknesses and finding ways to resolve them.
In other words, by learning what failure scenarios to prepare for, teams can improve and speed up their response to troubleshooting incidents.
Enhanced user experience
By strengthening your system, it is less likely that it will experience major outages and downtime that could negatively affect the user experience. It allows you to pinpoint issues and problems before they actually become customer pain points.
This will, in turn, result in improved user experience and increased customer satisfaction as you are now releasing high performing, more resilient software.
Reduced revenue loss
By running chaos experiments, companies can prevent lengthy disruptions and outages to the system, which otherwise could lead to losses in revenue as well as high maintenance costs.
Improved confidence in the system
The insights gathered from these experiments can help teams build more resilient and robust systems.
This means that teams, by predicting the unexpected, are prepared for worst-case scenarios, which helps to increase confidence in their systems by having a recovery plan set up for such scenarios.
Nonetheless, organizations should still carefully consider the challenges of chaos engineering before implementing it as, despite its benefits, it can also be costly and time-consuming.
Unleashing chaos for better digital experiences
As we’ve seen, chaos engineering is an essential practice when it comes to creating uninterrupted, seamless digital experiences for your customers.
It’s not just breaking things for the sake of breaking things; it’s a way to gain insight on how a system behaves and to gauge its resilience. In other words, chaos engineering is not only breaking things, but it’s also about fixing weaknesses in a system to build its resilience by exposing hidden threats thereby minimizing risk.
It’s important to note that chaos engineering isn’t meant to replace the other types of testing that are carried out throughout the software development life cycle but instead to complement these tests to provide a high performing system.
Finally, chaos engineering has an important role in DevOps. At the heart of DevOps is the idea of continuous improvement, which is why integrating chaos engineering into a DevOps methodology is essential to mitigate security risks. It’s also a way for DevOps teams to deal with the rising complexity of applications nowadays.
Consequently, introducing chaos experiments into your DevOps CI/CD pipeline will help teams detect hidden issues more quickly, which grows confidence in the system enabling them to deploy faster to end-users.

 Once all these criteria have been met, a KPI can be properly designed and implemented with confidence. However, it will need monitoring and adjustment as time goes on once the KPI has been fully integrated.
Once all these criteria have been met, a KPI can be properly designed and implemented with confidence. However, it will need monitoring and adjustment as time goes on once the KPI has been fully integrated.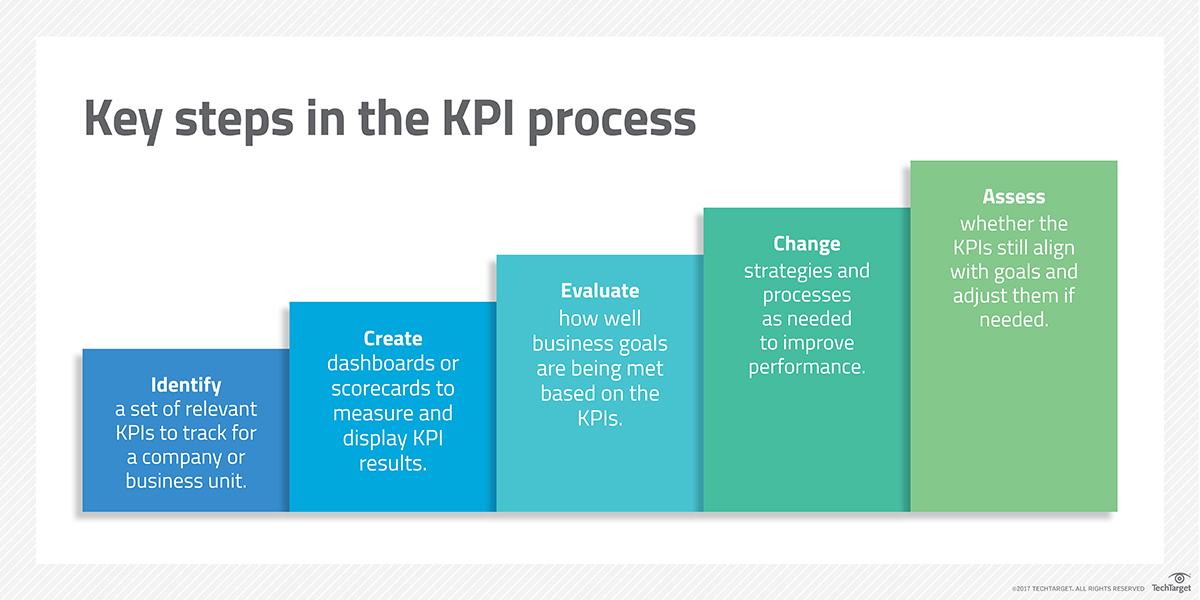





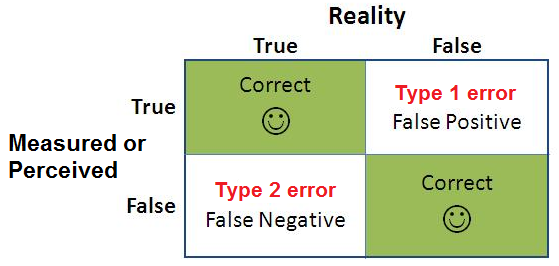
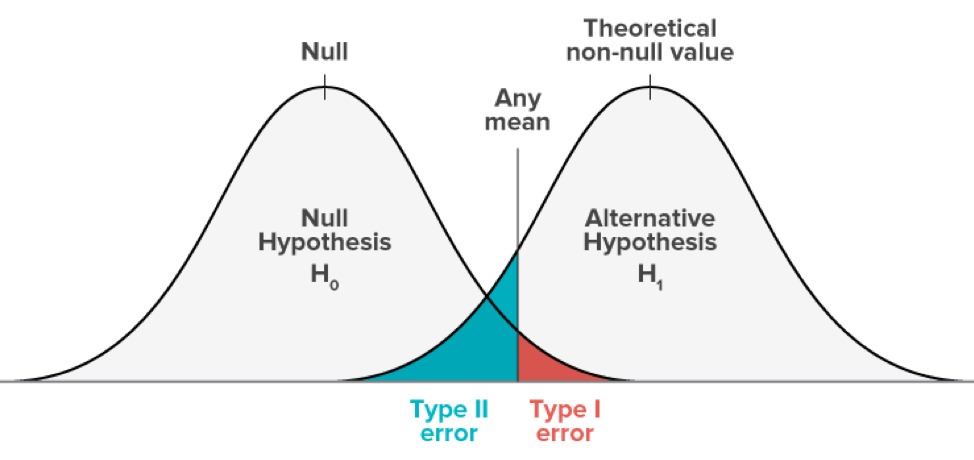
 You launch an A/B test to see if the variation (B) could outperform your control version (A).
You launch an A/B test to see if the variation (B) could outperform your control version (A).