Anthony is a B2B Digital Marketing Specialist. He's currently managing Demand Generation at AB Tasty, with a strong focus on marketing automation, nurturing and inbound marketing. He was previously an SEO consultant and worked several years for digital ad houses. View profile on LinkedIn.
What are the top feature flags projects on GitHub? Let’s find out.
If you are into open-source software, GitHub is probably the go-to place to find interesting projects you can use for free and contribute to.
Feature flags tools are no exception. We have listed below the top 10 feature toggle repositories on github.com ranked by popularity.
If you want to explore alternatives that scale better and are suitable for more use cases, read our article about feature flag implementation journey where we answer the question: should I build or buy a feature flag platform.
Unleash is the open-source feature management platform. It provides a great overview of all feature toggles/flags across all your applications and services. Unleash enables software teams all over the world to take full control on how they deploy new functionality to end users.
Flipper gives you control over who has access to features in your app.
Enable or disable features for everyone, specific actors, groups of actors, a percentage of actors, or a percentage of time.
Configure your feature flags from the console or a web UI.
Regardless of what data store you are using, Flipper can performantly store your feature flags.
Use Flipper Cloud to cascade features from multiple environments, share settings with your team, control permissions, keep an audit history, and rollback.
Piranha is a tool to automatically refactor code related to stale flags. At a higher level, the input to the tool is the name of the flag and the expected behavior, after specifying a list of APIs related to flags in a properties file. Piranha will use these inputs to automatically refactor the code according to the expected behavior.
This repository contains four independent versions of Piranha, one for each of the four supported languages: Java, JavaScript, Objective-C and Swift.
Flagr is an open source Go service that delivers the right experience to the right entity and monitors the impact. It provides feature flags, experimentation (A/B testing), and dynamic configuration. It has clear swagger REST APIs for flags management and flag evaluation.
Flipt is an open source, on-prem feature flag application that allows you to run experiments across services in your environment. Flipt can be deployed within your existing infrastructure so that you don’t have to worry about your information being sent to a third party or the latency required to communicate across the internet.
Flipt supports use cases such as:
Simple on/off feature flags to toggle functionality in your applications
Rolling out features to a percentage of your customers
Using advanced segmentation to target and serve users based on custom properties that you define
Togglz is another implementation of the Feature Toggles pattern for Java.
Modular setup. Select exactly the components of the framework you want to use. Besides the main dependency, install specific integration modules if you are planning to integrate Togglz into a web application (Servlet environment) or if you are using CDI, Spring, Spring Boot, JSF.
Straight forward usage. Just call the isActive() method on the corresponding enum to check if a feature is active or not for the current user.
Admin console. Togglz comes with an embedded admin console that allows you to enable or disable features and edit the user list associated with every feature.
Activation strategies. They are responsible for deciding whether an enabled feature is active or not. Activation strategies can, for example, be used to activate features only for specific users, for specific client IPs or at a specified time.
Custom Strategies. Besides the built-in default strategies, it’s easy to add your own strategies. Togglz offers an extension point that allows you to implement a new strategy with only a single class.
Feature groups. To make sure you don’t get lost in all the different feature flags, Togglz allows you to define group for feature that are just used for a visual grouping in the admin console.
FunWithFlags is an OTP application that provides a 2-level storage to save and retrieve feature flags, an Elixir API to toggle and query them, and a web dashboard as control panel.
It stores flag information in Redis or a relational DB (PostgreSQL or MySQL, with Ecto) for persistence and synchronization across different nodes, but it also maintains a local cache in an ETS table for fast lookups. When flags are added or toggled on a node, the other nodes are notified via PubSub and reload their local ETS caches
One of the most critical metrics in DevOps is the speed with which you deliver new features. Aligning developers, ops teams, and support staff together, they quickly get new software into production that generates value sooner and can often be the deciding factor in whether your company gains an edge on the competition.
Quick delivery also shortens the time betweensoftware development and user feedback, which is essential for teams practicing CI/CD.
One practice you should consider adding to your CI/CD toolkit is the blue-green deployment. This process helps reduce both technical and business risks associated with software releases.
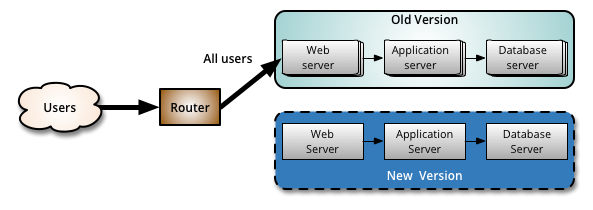
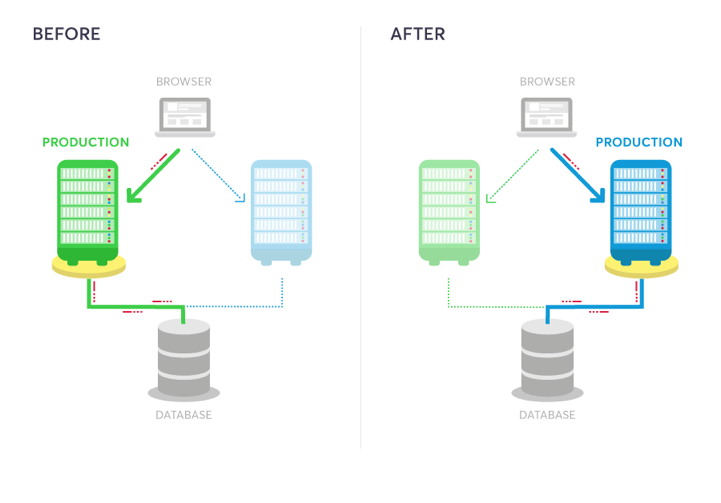
In this model, two identical production environments nicknamed “blue” and “green” are running side-by-side, but only one is live, receiving user transactions. The other is up but idle.
In this article, we’ll go over how blue-green deployments work. We’ll discuss the pros and cons of using this approach to release software. We’ll also compare how they stack up against other deployment methodologies and give you some of our recommended best practices for ensuring your blue-green deployments go smoothly.
[toc]
How do blue-green deployments work?
One of the most challenging steps in a deployment process is the cutover from testing to production. It must happen quickly and smoothly to minimize downtime.
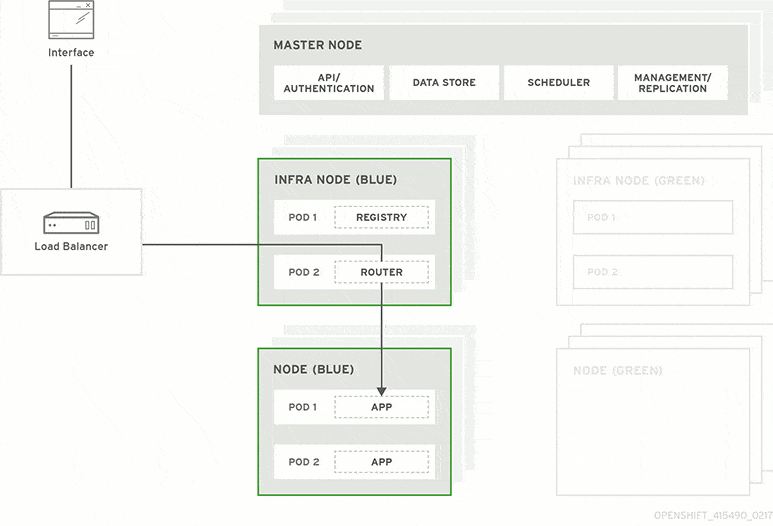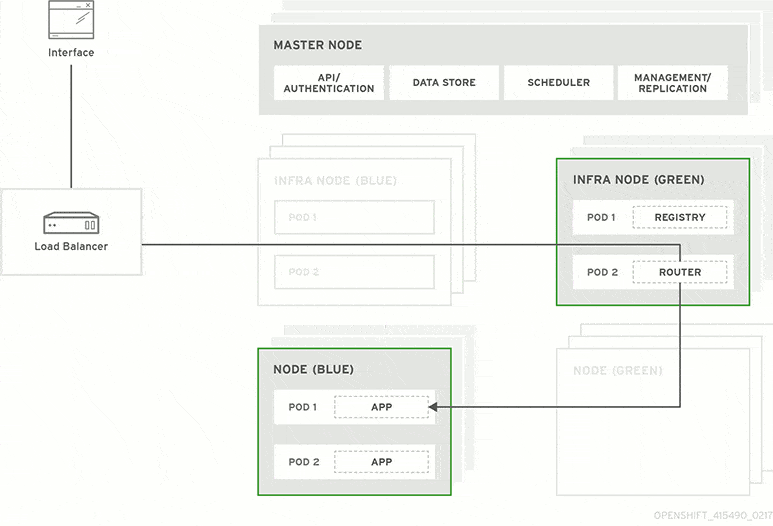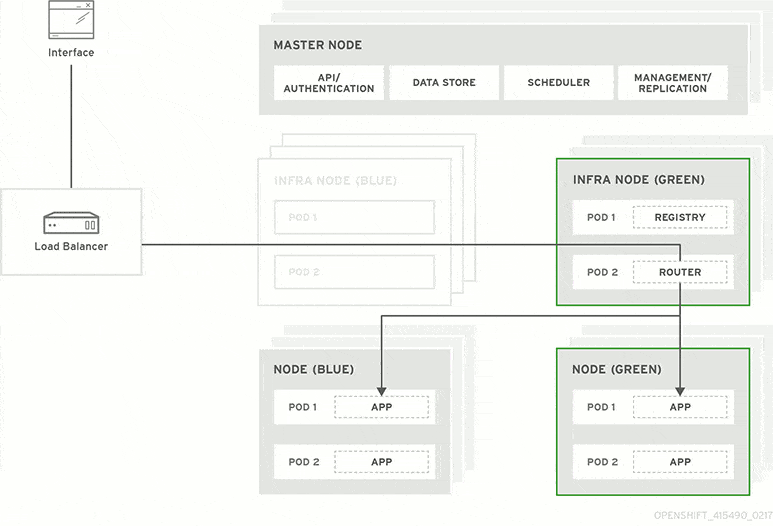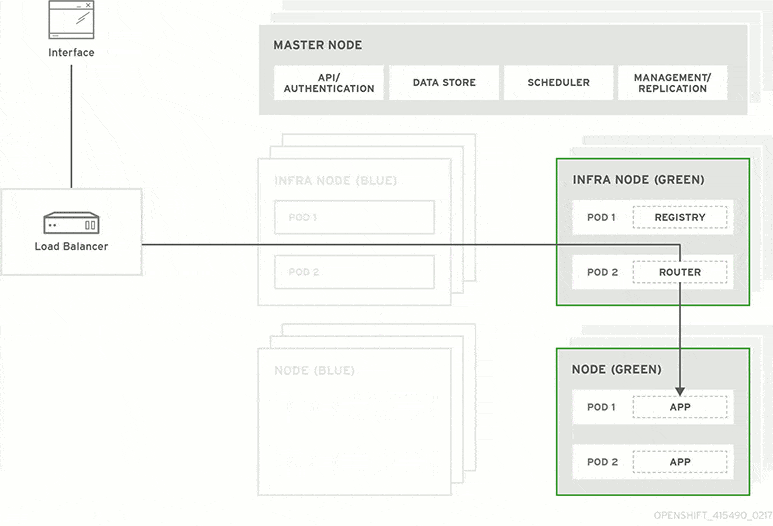
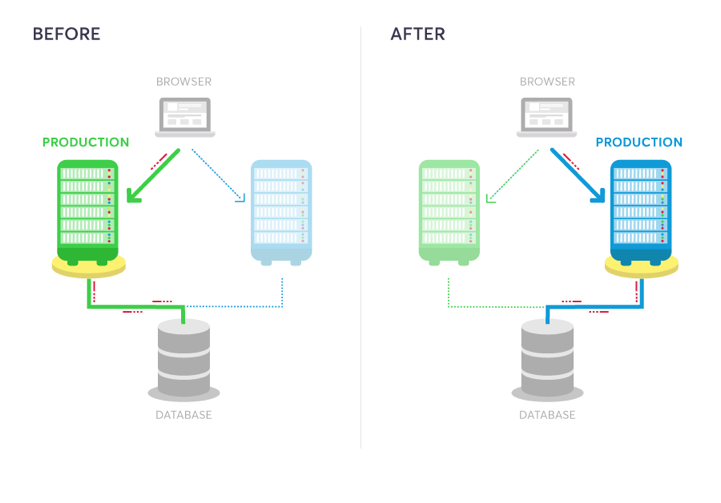
A blue-green deployment methodology addresses this challenge by utilizing two parallel production environments. At any given time, only one of them is the live environment receiving user transactions. In the image below, that would be green. The blue idle system is a near-identical copy.
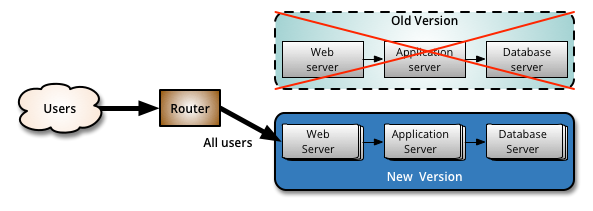
Your team will use the idle blue system as your test or staging environment to conduct the final round of testing when preparing to release a new feature. Once the new software is working correctly on blue, your ops team can switch routing to make blue the live system. You can then implement the feature on green, which is now idle, to get both systems resynchronized.
Generally speaking, that is all there is to a blue-green deployment. You have a great deal of flexibility in how the parallel systems and cut-overs are structured. For example, you might not want to maintain parallel databases, in which case all you will change is routing to web and app servers. For another project, you may use a blue-green deployment to release an untested feature on the live system, but set it behind a feature flag for A/B user testing.
Example
Let’s say you’re in charge of the DevOps team at a niche e-commerce company. You sell clothing and accessories popular in a small but high-value market. On your site, customers can customize and order products on-demand.
Your site’s backend consists of many microservices in a few different containers. You have microservices for inventory management, order management, customization apps, and a built-in social network to support your customers’ niche community.
Your team will release early and often as you credit your CI/CD model for your continued popularity. But this niche community is global, so your site sees fairly steady traffic throughout any given day. Finding a lull in which to update your production system is always tricky.
When one of your teams announces that their updated customization interface is ready for final testing in production, you decide to release it using a blue-green deployment so it can go out right away.
Animation of load balancer adjusting traffic from blue to green (Source)
The next day before lunch, your team decides they’re ready to launch the new customizer. At that moment, all traffic routes to your blue production system. You update the software on your idle green system and ask testers to put it through Q/A. Everything looks good, so your ops team uses a load balancer to redirect user sessions from blue to green.
Once traffic is completely filtered over to green, you make it the official production environment and set blue to idle. Your dev team pushes the updated customizer code to blue, puts in their lunch order, and takes a look at your backlog.
Pros: Benefits & use cases
One of the primary advantages of blue-green deployments over other software release strategies is how flexible they are. They can be beneficial in a wide range of environments and many use cases.
Rapid releasing
For product owners working within CI/CD frameworks, blue-green deployments are an excellent method to get your software into production. You can release software practically any time. You don’t need to schedule a weekend or off-hours release because, in most cases, all that is necessary to go live is a routing change. Because there is no associated downtime, these deployments have no negative impact on users.
They’re less disruptive for DevOps teams too. They don’t need to rush updates during a set outage window, leading to deployment errors and unnecessary stress. Executive teams will be happier too. They won’t have to watch the clock during downtime, tallying up lost revenue.
Simple rollbacks
The reverse process is equally fast. Because blue-green deployments utilize two parallel production environments, you can quickly flip back to the stable one should any issues arise in your live environment.
This reduces the risks inherent in experimenting in production. Your team can easily remove any issues with a simple routing change back to the stable production environment. There is a risk of losing user transactions cutting back—which we’ll get into a little further down—but many strategies for managing that situation are available.
You can temporarily set your app to be read-only during cutovers. Or you could do rolling cutovers with a load balancer while you wait for transactions to complete in the live environment.
Built-in disaster recovery
Because blue-green deployments use two production environments, they implicitly offer disaster recovery for your business systems. A dual production environment is its own hot backup.
Load balancing
Blue-green parallel production environments also make load balancing easy. When the two environments are functionally identical, you can use a load balancer or feature toggle in your software to route traffic to different environments as needed.
Easier A/B testing
Another use case for parallel production environments is A/B testing. You can load new features onto your idle environment and then split traffic with a feature toggle between your blue and green systems.
Collect data from those split user sessions, monitor your KPIs, and then, if analyses of the new feature look good in your management system, you can flip traffic over to the updated environment.
Cons: Challenges to be aware of
Blue-green deployments offer a great deal of value, but integrating the infrastructure and practices required to carry them out creates challenges for DevOps teams. Before integrating blue-green deployments into your CI/CD pipeline, it is worth understanding these challenges.
Resource-intensive
As is evident by now, to perform a blue-green deployment, you will need to resource and maintain two production environments. The costs of this, in money and sysadmin time, might be too high for some organizations.
For others, they may only be able to commit such resources for their highest value products. If that is the case, does the DevOps team release software in a CI/CD model for some products but not others? That may not be sustainable.
Extra database management
Managing your database—or multiple databases—when you have parallel production environments can be complicated. You need to account for anything downstream of the software update you’re making needs in both your blue and green environments, such as any external services you’re invoking.
For example, what if your feature change requires you to rename a database column? As soon as you change the name to blue, the green environment with old code won’t function with that database anymore.
Can your entire production environment even function with two separate databases? That’s often not the case if you’re using your blue and green systems for load balancing, testing, or any function other than as a hot backup.
A blue-green deployment diagram with a single database (Source)
Product management
Aside from system administration, managing a product that runs on two near-identical environments also requires more resources. Product Managers need reliable tools for tracking how their software is performing, which services different teams are updating, and ways to monitor the KPIs associated with each. A reliable product and feature management dashboard to monitor and coordinate all of these activities becomes essential.
Blue-green deployments vs. rolling deployments
Blue-green deployments are, of course, not the only option for performing rapid software releases. Another popular approach is to conduct a rolling deployment.
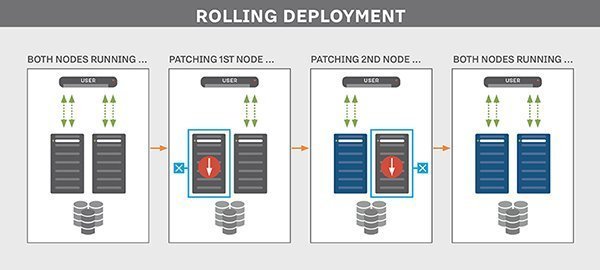
Rolling deployments also require a production environment that consists of multiple servers hosting an application, often, but not always, with a load balancer in front of them for routing traffic. When the DevOps team is ready to update their application, they configure a staggered release, pushing to one server after another.
While the release is rolling out, some live servers will be running the updated application, while others have the older version. This contrasts with a blue-green deployment, where the updated software is either live or not for all users.
As users initiate sessions with the application, they might either reach the old copy of the app or the new one, depending on how the load balancer routes them. When the rollout is complete, every new user session that comes in will reach the software’s updated version. If an error occurs during rollout, the DevOps team can halt updates and route all traffic to the remaining known-good servers until they resolve the error.
Rolling deployments are a viable option for organizations with the resources to host such a large production environment. For those organizations, they are an effective method for releasing small, gradual updates, as you would in agile development methodologies.
There are other use cases where blue-green deployments may be a better fit. For example, if you’re making a significant update where you don’t want any users to access the old version of your software, you would want to take an “all or nothing” approach, like a blue-green deployment.
Suppose your application requires a high degree of technical or customer support. In that case, the support burden is magnified during rolling deployment windows when support staff can’t tell which version of an application users are running.
Blue-green deployments vs. canary releasing
Rolling and blue-green deployments aren’t the only release strategies out there. Canary deployments are another alternative. At first, only a subset of all production environments receives a software update in a canary release. But instead of continuing to roll deploy to the rest, this partial release is held in place for testing purposes. A subset of users is then directed to the new software by a load balancer or a feature flag.
Canary releasing makes sense when you want to collect data and feedback from an identifiable set of users about updated software. Practicing canary releases dovetails nicely with broader rolling deployments, as you can gradually roll the updated software out to larger and larger segments of your user base until you’ve finished updating all production servers.
Best practices
You have many options for releasing software quickly. If you’re considering blue-green deployments as your new software release strategy, we recommend you adopt some of these best practices.
Automate as much as possible
Scripting and automating as much of the release process as possible has many benefits. Not only will the cutover happen faster, but there’s less room for human error. A dev can’t accidentally forget a checklist item if a script or a management platform handles the checklist. If everything is packaged in a script, then any developer or non-developer can carry out the deployment. You don’t need to wait for your system expert to get back to the office.
Monitor your systems
Always make sure to monitor both blue and green environments. For a blue-green deployment to go smoothly, you need to know what is going on in both your live and idle systems.
Both systems will likely need the same set ofmonitoring alerts, but set to different priorities. For example, you’ll want to know the second there is an error in your live system. But the same error in the idle system may need to be addressed sometime that business day.
In some cases, new and old versions of your software won’t be able to run simultaneously during a cutover. For example, if you need to alter your database schema, it would help if you structured your updates so that both blue and green systems will be functional throughout the cutover.
One way to handle these situations is to break your releases down into a series of even smaller release packages. Let’s say our e-commerce company is deepening its inventory and needs to update its database by changing a field name from “shirt” to “longsleeve_shirt” for clarity.
They might break this update down by:
Releasing a feature flag-enabled intermediary version of their code that can interpret results from both “shirt” and “longsleeve_shirt”;
Running a rename migration across their entire database to rename the field;
Releasing the final version of the code—or flip their feature flag—so the software only uses “longsleeve_shirt.”
Do more, smaller deployments
Smaller, more frequent updates are already an integral practice in agile development and CI/CD. It is even more important to follow this practice if you’re going to conduct blue-green deployments. Reducing deployment times shortens feedback loops, informing the next release, making each incremental upgrade more effective and more valuable for your organization.
Restructure your applications into microservices
This approach goes hand-in-hand with conducting smaller deployments. Restructuring application code into sets of microservices allows you to manage updates and changes more easily. Different features are compartmentalized in a way that makes them easier to update in isolation.
Use feature flags to reduce risk further
By themselves, blue-green deployments create a single, short window of risk. You’re updating everything, all-or-nothing, but you can cut back if needed should an issue arise.
Blue-green deployments also have a pretty consistent amount of administrative overhead that comes with each cutover. You can reduce this overhead through automation, but still, you’re going to follow the same process no matter whether you’re updating a single line of code or you’re overhauling your entire e-commerce suite.
Those conditions can be simple “yes/no” checks, or they can be complex decision trees. Feature flags help make software releases more manageable by controlling what is turned on or off at a feature-by-feature level.
For example, our e-commerce company can perform a blue-green deployment of their customizer microservice but leave the new code turned off behind a feature flag in the live system. Then, the DevOps team can turn on that feature according to whatever condition they wish, whenever it is convenient.
The team might want to do some further A/B testing in production. Or maybe they want to conduct some further fitness tests. Or it might make more sense for the team to do a canary release of the customizer for an identified set of early adopters.
Your feature flags can work in conjunction with a load balancer to manage which users see which application and feature subsets while performing a blue-green deployment. Instead of switching over entire applications all at once, you can cut over to the new application and then gradually turn individual features on and off on the live and idle systems until you’ve completely upgraded. This gradual process reduces risk and helps you track down any bugs as individual features go live one-by-one.
You can manually control feature flags in your codebase, or you can use feature flag services for more robust control. These platforms offer detailed reporting and KPI tracking along with a deep set of DevOps management tools.
We recommend using feature flags in any major application release when you’re doing a blue-green deployment. They’re valuable even in smaller deployments where you’re not necessarily switching environments. You can enable features gradually one at a time on blue, leaving green on standby as a hot backup if a major problem arises. Combining feature flags with blue-green deployments is an excellent way to perform continuous delivery at any scale.
Consider adding blue-green deployments to your DevOps arsenal
Blue-green deployments are an excellent method for managing software releases of any size, no matter whether they’re a whole application, major updates, a single microservice, or a small feature update.
It is essential to consider how well blue-green deployments will integrate into your existing delivery process before adopting them. This article detailed how blue-green deployments work, the pros and cons of using them in your delivery process, and how they stack up against other possible deployment methods. You should now have a better sense of whether blue-green deployments might be a viable option for your organization.
Picking an effective deployment strategy is an important decision for every DevOps team. Many options exist, and you want to find the strategy that best aligns with how you work. Today, we’ll go over canary deployments.
Are you an agile organization? Are you performing continuous integration and continuous delivery (CI/CD)? Are you developing a web app? Mobile app? Local desktop or cloud-based app? These factors, and many others, will determine how effective any given deployment strategy will be.
But no matter which strategy you use, remember that deployment issues will be inevitable. A merge may go wrong, bugs may appear, human error may cause a problem in production. The point is, don’t wear yourself out trying to find a deployment strategy that will be perfect. That strategy doesn’t exist.
Instead, try to find a strategy that is highly resilient and adaptive to the way you work. Instead of trying to prevent inevitable errors, deploy code in a way that minimizes errors and allows you to respond when they do occur quickly.
Canary deployments can help you put your best code into production as efficiently as possible. In this article, we’ll go over what they are and what they aren’t. We’ll go over the pros and cons, compare them to other deployment strategies, and show you how you can easily begin performing such deployments with your team.
In this article, we’ll go over:
[toc]
What is a canary deployment?
Canary deployments are a best practice for teams who’ve adopted a continuous delivery process. With this strategy, a new feature is first made available to a small subset of users. The new feature is monitored for several minutes to several hours, depending on the traffic volume, or just long enough to collect meaningful data. If the team identifies an issue, the new feature is quickly pulled. If no problems are found, the feature is made available to the entire user base.
The term “canary deployment” has a fascinating history. It comes from the phrase “canary in a coal mine,” which refers to the historical use of canaries and other small songbirds as living early-warning systems in mines. Miners would bring caged birds with them underground. If the birds fell ill or died, it was a warning that odorless toxic gases, like carbon monoxide, were present. While inhumane, it was an effective process used in Britain and the US until 1986, when electronic sensors replaced canaries.
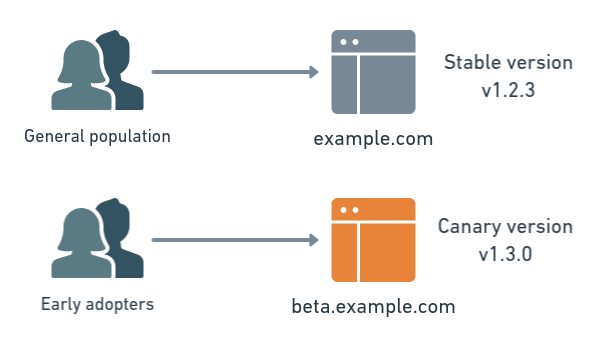
A canary deployment turns a subset of your users —ideally a bug-tolerant subset— into your own early warning system. That user group identifies bugs, broken features, and unintuitive features before your software gets wider exposure.
Your canary users could be self-identified early adopters, a demographically targeted segment, or a random sampling. Whichever mix of users makes the most sense for verifying your new feature in production.
One helpful way to think about canary deployments is risk management. You are free to push new, exciting features more regularly without having to worry that any one new feature will harm the experience of your entire user base.
Canary releases vs. canary deployments
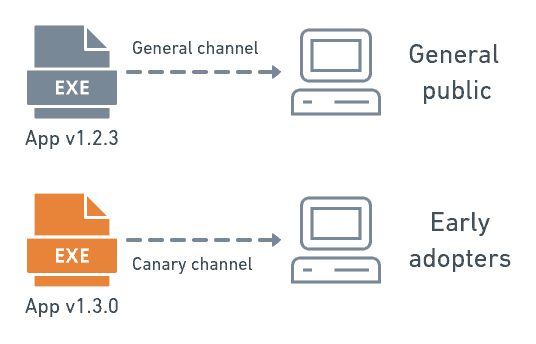
The phrases “canary release” and “canary deployment” are sometimes used interchangeably, but in DevOps, they really should be thought of as separate. A canary release is a test build of a complete application. It could be a nightly release or a beta, for example.
Teams will often distribute canary releases hoping that early adopters and power users, who are more familiar with development processes, will download the new application for real-world testing. The browser teams at Mozilla and Google, and many other open-source projects, are fond of this release strategy.
On the other hand, canary deployments are what we described earlier. A team will release new features into production with early adopters or different user subsets, routed to the new software by a load balancer or feature flag. Most of the user base still sees the current, stable software.
Canary deployment pros and cons
Canary deployments can be a powerful and effective release strategy. But they’re not the correct strategy in every possible scenario. Let’s run through some of the pros and cons so you can better determine whether they make sense for your DevOps team.
Pros
Support for CI/CD processes
Canary deployments shorten feedback loops on new features delivered to production. DevOps teams get real-world usage data faster, which allows them to refine and integrate the next round of features faster and more effectively. Shorter development loops like this are one of the hallmarks of continuous integration/continuous delivery processes.
Granular control over feature deployments
If your team conducts smaller, regular feature deployments, you reduce the risk of errors disrupting your workflow. If you catch a mistake in the deployment, you won’t have exposed many users to it, and it will be a minor matter to resolve. You won’t have exposed your entire user population and needed to pull colleagues off planned work to fix a major production issue.
Real-world testing
Internal testing has its place, but it is no substitute for putting your application in front of real-world users. Canary deployments are an excellent strategy for conducting small-scale real-world testing without imposing the significant risks of pushing an entirely new application to production.
Quickly improve engagement
Besides offering better technical testing, canary deployments allow you to quickly see how users engage with your new features. Are session lengths increasing? Are engagement metrics rising in the canary? If no bugs are found, get that feature in front of everyone.
There is no need to wait for a more extensive test deployment to complete. Engage those users and get iterating on your next feature.
More data to make business cases
Developers may see the value in their code, but DevOps teams still need to make business cases to leadership and the broader organization when they need more resources.
Canary deployments can quickly show you what demand might be for new features. Conduct a deployment for a compelling new feature on a small group of influencer users to get them talking. Use engagement and publicity metrics to make the case why you want to push a major new initiative tied to that feature.
Stronger risk management
Canary deployments are effectively a series of microtests. Rolling out new features incrementally and verifying them one at a time with canary testing can significantly reduce the total cost of errors or more significant system issues. You’ll never need to roll back a major release, suffer a PR hit, and need to rework a large and unwieldy codebase.
Cons
More overhead
Like any complex process, canary deployments come with some downsides. If you’re going to use a load balancer to partition users, you will need additional infrastructure and need to take on some additional administration.
In this scenario, you create a second production environment and backend that will run alongside your primary environment. You will have two codebases, two app servers, potentially two web servers, and networking infrastructure to maintain.
Alternatively, many DevOps teams use feature flags to manage their canary deployments on a single system. A feature flag can partition users into a canary test at runtime within a single code base. Canary users see the new feature, and everyone else runs the existing code.
Deploying local applications is hard
If you’re developing a locally installed application, you run the risk of users needing to initiate a manual update to get the latest version of your software. If your canary deployment sits in that latest update, your new feature may not get installed on as many client systems as you need to get good test results.
In other words, the more your software runs client-side, the less amenable it is to canary deployments. A full canary release might be a more suitable approach to get real-world test results in this scenario.
Users are still exposed to software issues
While the whole point of a canary deployment is to expose only a few users to a new feature to spare the broader user base, you will still expose end users to less-tested code. If the fallout from even a few users encountering a problem with a particular feature is too significant, then consider skipping this kind of deployment in favor of more rigorous internal testing.
How to perform a canary deployment
Planning out a canary deployment takes a few simple steps:
Identify your canary group
There are several different ways you can select a user group to be your canary.
Random subset
Pick a truly random sampling of different users. While you can do this with a load balancer, feature flag management software can easily route a certain percentage of total traffic to a canary test using a simple modulo.
Early adopters
If you run an early adopter program for highly engaged users, consider using them as your canary group. Make it a perk of their program. In exchange for tolerating bugs they might encounter in a canary deployment, you can offer them loyalty rewards.
By region
You might want to assign a specific region to be your canary. For example, you could set European IPs during late evening hours to go to your canary deployment. You would avoid exposing daytime users to your new features but still get a handful of off-hours user sessions to use as a test.
Internal testers
You can always configure sessions from your internal subnets to be the canary.
Decide on your canary metrics
The purpose of conducting a canary deployment is to get a firm “yes” or “no” answer to the question of whether your feature is safe to push into wider production. To answer that question, you first need to decide what metrics you’re going to use and install the means for monitoring performance.
For example, you may decide you want to monitor:
Internal error counts
CPU utilization
Memory utilization
Latency
You can customize feature management software quickly and easily to monitor performance analytics. These platforms can be excellent tools for encouraging a culture of experimentation.
Decide how to transition from canary to full deployment
As discussed, canary releases should only last on the order of several minutes to several hours. They are not intended to be overly long experiments. Because the timeframe is so short, your team should decide up front how many users or sessions you want in the canary and how you’re going to move to full deployment once your metrics hit positive benchmarks.
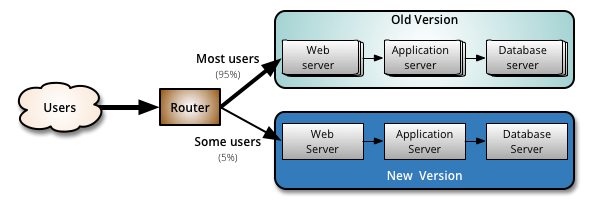
For example, you could go with a 5/95 random canary deployment. Configure a feature flag to move a random 5 percent of your users to the canary test while the remaining 95 percent stay on the stable production release. If you see positive results, remove the flag and deploy the feature completely.
Or you might want to take a more conservative approach. Another popular canary strategy is to deploy a canary test logarithmically, going from a 1 percent random sample to 10 percent to see how the new feature stands up to a larger load, then up to a full 100 percent.
Determine what infrastructure you need
Once your team is on the same page about the approach you’ll take, you’ll need to make sure you have all the proper infrastructure in place to make your canary deployment go off without a hitch.
You need a system for partitioning the user base and for monitoring performance. You can use a router or load balancer for the partitioning, but you can also do it right in your code with a feature flag. Feature flags are often more cost-effective and quick to set up, and they can be the more powerful solution.
Canary vs. blue/green deployments
Canary deployments are also sometimes confused with blue/green deployments. Both can use parallel production environments —managed with a load balancer or feature flag— to mitigate the risk of software issues.
In a blue/green deployment, those environments start identical, but only one receives traffic (the blue server). Your team releases a new feature onto the hot backup environment (the green server). Then the router, feature flag, or however you’re managing traffic, gradually shifts new user sessions from blue to green until 100 percent of all traffic goes to green. Once the cutover is complete, the team updates the now-old blue server with the new feature, and then it becomes the hot backup environment.
The way the switchover is handled in these two strategies differs because of the desired outcome. Blue/green deployments are used to eliminate downtime. Canary deployments are used to test a new feature in a production environment with minimal risk and are much more targeted.
Use feature flags for better deployments
When you boil it right down, a feature flag is nothing more than an “if” statement from which users take different code paths at runtime depending on a condition or conditions you set. In a canary deployment, that condition is whether the user is in the canary group or not.
Let’s say we’re running a fledgling social networking site for esports fans. Our DevOps team has been hard at work on a content recommender that gives users real-time recommendations based on livestreams they’re watching. The team has refined the recommendation feature to be significantly faster. It has performed well in internal testing, and now they want to see how it performs under real-world conditions.
The team doesn’t want to invest time and money into installing new physical infrastructure to conduct a canary deployment. Instead, the team decides to use a feature flag to expose the new recommendation engine to a random 5 percent sample of the user base.
The feature flag splits users into two groups with a simple modulo when users load a live stream. Within minutes your team gets results back from a few thousand user sessions with the new code. It does, in fact, load faster and improves user engagement, but there is an unanticipated spike in CPU utilization on the production server. Ops staff realize it is about to degrade performance, so they kill the canary flag.
The team agrees not to proceed with rollout until they can debug why the new code caused the unexpected server CPU spike. Thanks to the real-world test results provided by the canary deployment, they have a pretty good idea of what was going on and get back to work.
Features flags streamline and simplify canary deployments. They mitigate the need for a second production environment. Using feature flag management software like AB Tasty allows sophisticated testing and analysis.
In this article, we’ll cover how to implement feature flags in Java using our Java SDK and also discuss other open-source Java frameworks available on Github. If your are using the Spring framework, this article will suit you well.
Overview of the feature flag pattern
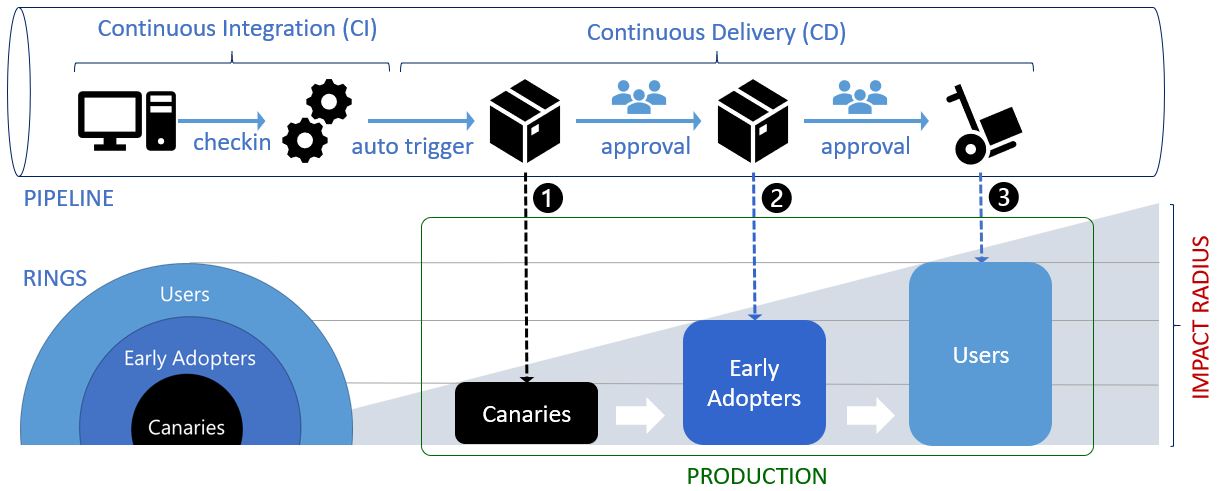
Feature flags are a powerful software development tool that turns certain functionalities on and off without the need to deploy new code, and without any service disruptions. Feature flags can be used for a wide range of purposes, from kill switch to targeted releases (ex: ring deployments, canary deployments), through feature testing. Thus, a feature flag ranges from a simple IF statement to more complex decision trees, which act upon different variables.
As its core, it provides a Decision API to assign and retrieve feature flag values for your users (e.g. what value a flag should be for a specific user), so you don’t have to mess with complex configuration files or manage a dedicated infrastructure to store all the different flag values.
The “Decision” part in the name refers to built-in intelligence that is key to maintain flag values consistency between different user sessions or for instance when an anonymous users gets authenticated to your application.
White this REST API is language-agnostic by design, we provide several server and client-side SDKs. Here, we’ll discuss the Java SDK that includes preconfigured methods to implement the Decision API. Refer to our developer documentation for more details.
Setting feature flags with AB Tasty Java SDK
Using our cloud-based feature management service is a 2- step process. First, in your codebase, you wrap your features once with flags using methods from the Java SDK. Once this is done, you remotely configure your flags (values, segments…) from the dashboard. Let’s see both steps in details.
Setting up the Java SDK
Installation and initialization
First, you need to add the Java repository to your dependency manager. You can use Maven or Gradle build tools to do so:
To initialize and start the SDK, simply call the start function of the class, in the most appropriate location for your application. You need to pass two parameters: your environment id and your API authentication key. Both values are available from the user interface (UI), once you are logged in.
The visitor instance is a helper object that lets you manage the context and campaigns for a user identified by a unique ID.
The user context is a property dataset which defines the current user of your app. This dataset is sent and used by the Decision API as targeting criterias for campaign assignment.
For example, if you want to enable or disable a specific feature based on a VIP status, you would pass this attribute as a key-value pair in the user context so that the Decision API can enable or disable the corresponding feature flag for the user.
The first parameter of the method is the Unique visitor identifier, while the second is the initial user context.
You can also update the visitor context when required. The following method from the Visitor instance allows you to set new context values matching the given keys.
The synchronizeModifications() method of the visitor instance automatically calls the Decision API to run feature flag assignments according to the current user context.
<pre><code class="language-java line-numbers"><!--
Visitor visitor = Flagship.newVisitor("YOUR_VISITOR_ID")
visitor.updateContext("isVip", true)
visitor.synchronizeModifications().whenComplete((instance, error) -> {
// Asynchronous non blocking call
// Synchronization has been completed. Do stuff here...
});
--></code></pre>
Once the campaign has been assigned and synchronized, all the modifications are stored in the SDK. You can retrieve these modifications using the getModification method from the Visitor instance. It retrieves a modification value by its key. If no modification matches the given key or if the stored value type and default value type do not match, default value will be returned.
The getModification method accepts a third argument, that, if set to true will automatically report on our server that the current visitor has seen this specifc variation. It is also possible to call activateModification() later.
Our Universal Collect protocol provides a unified hit format to send data back to our server-side solution for reporting purposes. The format of the hit is based on the Google Analytics measurement protocol. By sending hits to our platform, you can measure the impact of a feature on different metrics such as pageviews, screenviews, transactions or generic events.
To send hits, you must call the sendHit method from the Visitor instance:
<pre><code class="language-java line-numbers"><!--
// Pageview hit
Page page = new Page("https://www.my_domain_com/my_page")
visitor.sendHit(page);
// Sreenview hit
Screen screen = new Screen("screen location")
.withResolution(200, 100)
.withLocale("fr_FR")
.withIp("127.0.0.1")
.withSessionNumber(2);
visitor.sendHit(screen);
// Transaction hit
Transaction transaction = new Transaction("#12345", "affiliation")
.withCouponCode("code")
.withCurrency("EUR")
.withItemCount(1)
.withPaymentMethod("creditcard")
.withShippingCosts(9.99f)
.withTaxes(19.99f)
.withTotalRevenue(199.99f)
.withShippingMethod("1day");
visitor.sendHit(transaction);
// Generic Event hit
Event event = new Event(Event.EventCategory.ACTION_TRACKING, "action")
.withEventLabel("label")
.withEventValue(100);
visitor.sendHit(event);
--></code></pre>
To create a feature flag from the dashboard, apply the following steps:
Go to the dashboard.
Click the + button.
Choose an existing project or create a new one
Click the “Add a use case” button.
You are presented with a list of different templates or use cases (ex: progressive rollout, A/B test…)
Choose the “Feature toggling” template.
Entering the basic information
First, you need to enter the basic information of your feature flag use case:
The feature name: use the most representative name for your feature, because this is the one you’ll need to remember in case you want to find it later.
The feature description: explain exactly what your feature deployment is about and what its purpose for your business is.
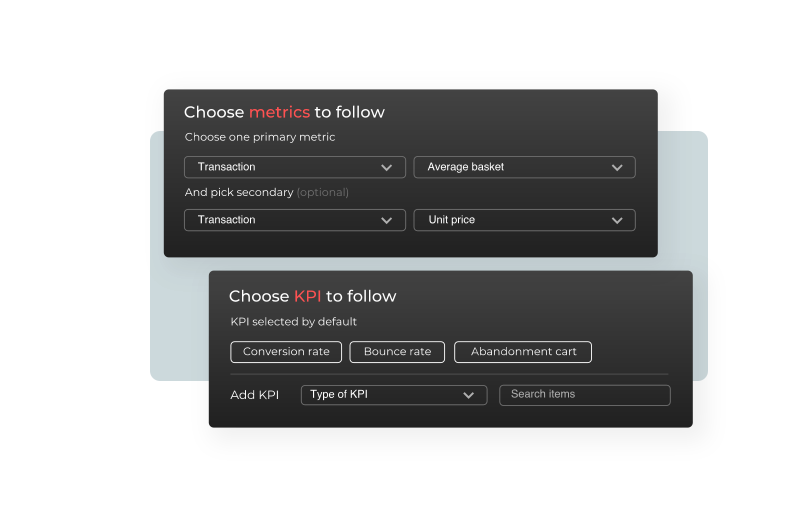
The primary/secondary metric to follow (optional) which will serve as a point of reference to analyze performance. For more information, refer to Configuring KPIs.
Defining flags
This is where you configure the flags and their values based on your different scenarios. Think of it as the config file mentioned in the first method, but that you manage remotely from the cloud. Important: flag names you specify here should match the ones used in your codebase.
Defining targeting
During this step, you can define which users will be assigned to your different flag values. This is a segmentation engine built into the platform that makes it easy to assign flags conditionally based on user traits (or attributes) that you have access to in your codebase. Refer to this article about feature flag targeting for more information. The 3 following options are available:
All Users if you want all your users to progressively see your feature.
Users by ID if you want only users with a specific ID to see your feature.
Key if you only want users matching this key value to see your feature.
Enabling your feature
Once you have configured your feature, it is OFF by default to allow you to check that it is correctly configured. Back to the dashboard, you can activate your feature ON when you are ready!
And that’s it. Now, provided changes to your codebase have been deployed, you can activate/deactivate feature flags, remotely change their values and have your Java Application react instantly to these changes.
Open-source feature flag frameworks for Java
For the sake of completeness, we list here open source alternatives if you are using Java. While there are pros and cons to each approach, the third-party vendor option is probably the most efficient method for large teams with evolving use cases that don’t want to deal with the challenges of an in-house system.
Keep reading: The Journey of Feature Flag Implementation (Build vs. Buy) where we discuss the pros and cons of different options when it comes to choosing between to build, use an open-source project or buy a feature flag management solution.
FF4J – Feature Flipping for Java
FF4j, is an implementation of the Feature Toggle pattern for Java. It provides a rich set of features:
Enable and disable features at runtime – no deployments.
Enable features not only with flag values but also drive access with roles and groups.
Implement custom predicates to evaluate if a feature is enabled.
Keep your code clean and readable: Avoid nested if statements but use annotations.
Each action (create, update, delete, toggles) can be traced and saved in the audit trail for troubleshooting.
Administrate FF4j (including features and properties) with the web UI.
Wide choice of databases technologies to store your features, properties and events.
(Distributed) Cache Evaluating predicates may put pressure on DB (high hit ratio).
Togglz is another implementation of the Feature Toggles pattern for Java.
Modular setup. Select exactly the components of the framework you want to use. Besides the main dependency, install specific integration modules if you are planning to integrate Togglz into a web application (Servlet environment) or if you are using CDI, Spring, Spring Boot, JSF.
Straight forward usage. Just call the isActive() method on the corresponding enum to check if a feature is active or not for the current user.
Admin console. Togglz comes with an embedded admin console that allows you to enable or disable features and edit the user list associated with every feature.
Activation strategies. They are responsible for deciding whether an enabled feature is active or not. Activation strategies can, for example, be used to activate features only for specific users, for specific client IPs or at a specified time.
Custom Strategies. Besides the built-in default strategies, it’s easy to add your own strategies. Togglz offers an extension point that allows you to implement a new strategy with only a single class.
Feature groups. To make sure you don’t get lost in all the different feature flags, Togglz allows you to define group for feature that are just used for a visual grouping in the admin console.
Unleash is an open-source feature management platform. It provides an overview of all feature toggles/flags across all your applications and services. You first need to setup an Unleash server that you self-host, and then use a client SDK to connect your application to the server. A Java Client SDK is available and provides features such as:
Boolean feature toggles (on/off)
Canary release (Gradual rollout)
Targeted release
Experimentation (A/B testing)
Kill switches
Custom activation strategies
Privacy first (GDPR) where end-user data never leaves your application
Audit logs
Addons integrating with other popular tools (Slack, Teams, Datadog, etc.)
Feature flags, or toggles, as described by Martin Fowler are a “powerful technique, allowing teams to modify system behavior without changing code.” In other words, implementing feature flags as a set of patterns is a robust way to manage code complexity and deliver new features to users using CI/CD (continuous integration/continuous delivery) pipelines, reducing the time to value and decreasing the risk of deploying buggy, error-ridden code to production.
Feature flags are an integral part of deploying software updates via CI/CD pipelines without disrupting existing functionality. There are several ways to implement feature flags in your React apps. Let’s consider three of the most popular and common ways:
The do-it-yourself method where the developer writes the feature flag code from scratch.
The use of open-source libraries that are integrated into the React Single-Page Application (SPA).
Signing up with a cloud based solution (feature flag as a service).
Do it yourself: A simple and free solution
This method requires you to write code, switching feature flags on and off directly in JavaScript. By expanding on this method, let’s consider a simple use case, including code samples from a feature flag React app project, before looking at the primary pros and cons of this method.
1. Setting up the React project
If you already have your React project set up, you can skip to the next section, “Adding new feature flags” otherwise, here is a step-by-step guide to setting up a new project.
The reactjs.org website notes that the create-react-app is the easiest way to develop a new single-page application with React.
Therefore, use the following code to create a new boilerplate app:
npx create-react-app my-app
cd my-app
npm start
2. Adding new feature flags
Now that we have the project created and an empty app template, let’s look at how to add a feature flag in React.
The first step is to create a React js feature flag file with the following format used to create new features. This will act as your config file that you’ll update every time you want to turn on/off a specific feature.
Each feature flag must have a unique name that we can later call or reference in React. A short description is also needed to describe the functionality it adds and an active flag to determine whether the toggle is on or off.
As seen from the code snippet for creating a banner flag, our flags are stored inside an array.
To store these flags in local storage, add the following function to your app.js file and call it at the top of your feature component file.
Note: This will create 3 new feature flags if there are no feature flags created in local storage (localStorage). You also need to use the JSON.stringify () method to convert the JavaScript objects into strings as localStorage can only handle strings.
3. Adding the feature component
In order to reference these feature flags in React and show/hide features based on these feature flags, you need to create a new React component <Feature />. Define it in a file called feature.js and store it in your src folder.
This component accepts 2 props:
the flag name to check against,
the child content to be used (children prop).
The first step is to get the feature from localStorage and see if it is set to active or not. If the feature is active, we can render the feature; otherwise, we return null.
This component will handle the toggling of feature flags on and off. Finally, you just import and render the component where you need.
Pros
There are several advantages to using this method. The most obvious being the fact that when writing your own feature flag code, it is free, easily accessible, and highly available for small React feature toggle projects.
Cons
However, what happens when your application grows in scale, and you need to create and manage several different feature flags, both long- and short-lived?
This is where this method’s disadvantages come to the fore. Succinctly stated, this method is difficult to scale where lots of flags are utilized. And as you can see from the code samples highlighted above, advanced features require more development work which can be challenging and complicated to maintain.
Feature flag open-source libraries for React
The second method is to use existing libraries that you can find on Github. A simple search will lead you to multiple open-source libraries or packages to do feature flagging. Here are a few examples of these packages for React:
Flagged, for instance, provides nice features such as:
Hooks API
High Order Component API
Render Props API
TypeScript Support
Zero Dependencies
Nested Flags
Pros
The advantages of using these open-source libraries are that they are freely available, easy to use, and quick to set up. As described above, all you need to do is consume the libraries into your application and then call the functions created in the library files, passing in variables as required and reading returned variables to understand the state of your feature flags.
Cons
However, as with everything, there are also disadvantages to using open-source feature flag libraries. The most prominent includes the fact that maintenance and evolution are not guaranteed, and the library’s functional scope might not suit your app’s specific requirements. In both cases, a fair amount of refactoring and new code development will have to take place to maintain the existing code and add the features specific to your application.
Feature flag management platforms
The third and last way to implement feature flags in a single-page application is using a dedicated feature flag management 3rd-party service that provides a React integration.
By way of expanding on this statement, let’s look at a step-by-step guide on how to set up feature flags in our server-side solution with the React SDK. As an alternative, you can also directly call the Decision API (REST API), but for the sake of simplicity we’ll use the dedicated SDK that provides additional capabilities out of the box (ex: bucketing). The platform also provides additional SDKs for Java, Python, PHP, .Net, Go, iOS, Android, Flutter…
Using our cloud-based feature management service is a 2- step process. First, in your codebase, you wrap your features once with flags using methods and providers from the React SDK. Once this is done, you remotely configure your flags (values, segments…) from the dashboard.
1. Set up the React SDK in your SPA project and wrap features with flags
Let’s use the same project that we created in the first method (Setting up the project) using our create-react-app boilerplate app.
Install the SDK using NPM or yarn.
npm install @flagship.io/react-sdk
Import the our provider from the React SDK which makes the tool’s features available to the rest of your app. You can wrap your app directly within the app.js file.
The envID and apiKey props are required. You access them from the UI under the “Settings” section. For more information on the different props available, please refer to the API references.
Then, from the React component you want to get access to your flags, import and use one of our React Hook. It gets modifications assigned to the current user as well as further functionalities, such as sending hit tracking, checking the SDK status…
You can refer to this short video that goes through all the process of a feature flag setup or read the detailed instructions below.
Creating your feature flag use case
To create a feature flag from the dashboard, apply the following steps:
Go to the dashboard.
Click the + button.
Choose an existing project or create a new one
Click the “Add a use case” button.
You are presented with a list of different templates or use cases (ex: progressive rollout, A/B test…)
Choose the “Feature toggling” template.
Entering the basic information
First, you need to enter the basic information of your feature flag use case:
The feature name: use the most representative name for your feature, because this is the one you’ll need to remember in case you want to find it later.
The feature description: explain exactly what your feature deployment is about and what its purpose for your business is.
The primary/secondary metric to follow (optional) which will serve as a point of reference to analyze performance. For more information, refer to Configuring KPIs.
Defining flags
This is where you configure the flags and their values based on your different scenarios. Think of it as the config file mentioned in the first method, but that you manage remotely from the cloud. Important: flag names you specify here should match the ones used in your codebase (“btnColor” in your code example above).
Defining targeting
During this step, you can define which users will be assigned to your different flag values. This is a segmentation engine built into the platform that makes it easy to assign flags conditionally based on user traits (or attributes) that you have access to in your codebase. Refer to this article about feature flag targeting for more information. The 3 following options are available:
All Users if you want all your users to progressively see your feature.
Users by ID if you want only users with a specific ID to see your feature.
Key if you only want users matching this key value to see your feature.
Enabling your feature
Once you have configured your feature, it is OFF by default to allow you to check that it is correctly configured. Back to the dashboard, you can activate your feature ON when you are ready!
And that’s it. Now, provided changes to your codebase have been deployed, you can activate/deactivate feature flags, remotely change their values and have your React App react instantly to these changes.
Last thoughts
This article describes three ways of implementing feature flags in a React SPA (single-page application):
the do-it-yourself method,
using open-source libraries,
signing up with a dedicated feature management platform.
While there are pros and cons to each approach, the third-party vendor option is probably the most efficient method for large teams with evolving use cases that don’t want to deal with the challenges of an in-house system. For more details, read our article The Journey of Feature Flag Implementation.
Developers can create feature toggles by coding a “decision point” where the system runs a given feature depending on whether specified conditions are met. In other words, feature toggles allow you to quickly and efficiently deliver context-sensitive software.
Feature toggles have a wide range of possible applications for everything from supporting agile development, to market testing, to streamlining ongoing operations. However, with this power comes the potential for introducing unnecessary complexity into your code. You need to properly manage feature toggles to get the most from them.
In this article, we’ll give you an overview of precisely what feature toggles can do, how you can implement them in your development and production environments, and share some of our own recommended best practices for using them.
[toc]
What exactly is a feature toggle?
In the simplest possible case, a feature toggle is a powerful “if” statement, from which at least one of two different codepaths is followed at runtime depending on a condition or conditions provided. Here is a straightforward example:
In this Python code sample, we have defined two different, generic features: normalFeature and testFeature. At runtime, the application checks in configuration to see whether an internal test user is loading it. If so, the application loads the test feature under development. If not, the regular customer sees the current feature.
Example of a feature toggle controlling two codepaths (Source)
Feature toggles can be anything from a simple “if” statement to complex decision trees, which act upon many different variables. A wide variety of conditions, including fitness test results from other features in the codebase, a setting in feature management software, or a variable provided by a config file, can be used to determine which way a toggle flips.
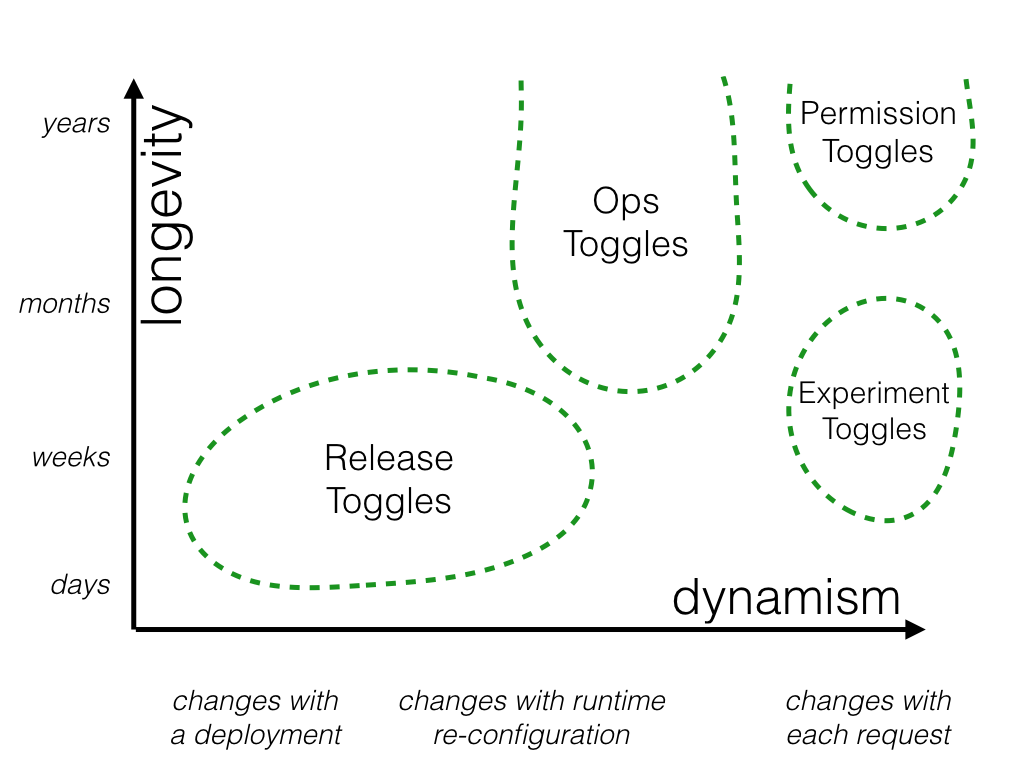
Different feature toggles for different tasks
You should manage feature toggles differently depending on how you deploy them. One useful way to think about toggles is to break them down into categories across two dimensions: their longevity in your development and operational processes and how dynamic their function is. Considered this way, we can break feature toggles out into four different categories:
Release toggles
Experimental toggles
Operational toggles
Permission toggles
A chart of the four feature toggle categories (Source)
Release toggles usually aren’t meant to be permanent fixtures in your codebase. You should remove them once their associated feature is complete. In practice, this usually means they have a lifecycle of a few days to a few weeks, which puts them lower on the longevity scale. Release toggles also tend not to be very dynamic. Either the feature is ready for release, or it isn’t.
Release toggle example
An e-commerce company has a new configurator tool in development at the request of one high-profile customer. The configurator monitors items the customer has already selected for a built-out and suggests item sets to complete their order.
The company eventually wants to roll out that feature to all customers, but for now, the configurator only works within that one customer’s specifications. The configurator’s dev team enables a release toggle for this new feature that keeps it inactive.
Experiment toggles
These toggles are used to facilitate A/B testing or multivariable testing. You create a toggle point beyond which the different features you want to test are down two or more different code paths. At runtime, the system —or the toggle itself— splits users into different cohorts and exposes them to the different features.
Usually, experiment toggles should only exist as long as data needs to be gathered for feature testing. The exact timeframe will depend on traffic volume to that feature, but typically that means on the order of several weeks to several months. This constraint is more about the test itself than the toggle. The value of the data collected will diminish over time as other feature and code updates invalidate comparisons to earlier gathered user data.
Experiment toggle example
Our e-commerce company has finished debugging its new configurator, but there is some debate over which of the two suggestion algorithms provides the best experience. They decide to set up an A/B test to get some real-world data.
They add an experiment toggle to the production configurator with the two different suggestion algorithms behind it. The toggle splits users into two cohorts with a modulo when they try loading the configurator. After three weeks, the team feels they have conclusive data showing more users complete their orders using the B algorithm. The e-commerce company removes the experiment toggle, and that algorithm goes live for all users.
Operational (Ops) toggles are used to turn features off —like a “kill switch“— or otherwise adjust their performance. For example, if certain conditions are not met, such as KPI targets dipping below a threshold, the toggle turns that feature off until conditions improve. Operational toggles are useful to code in front of new features just out of testing or in front of resource-intensive features.
The longevity of ops toggles varies depending on their specific use case. If you’re using one to regulate a new feature just out of development, you probably only need the toggle in place for a couple of months. On the other hand, a kill switch toggle is usually designed to be a permanent code fixture. Ops toggles usually are as static or dynamic as the conditions under which the feature they control will operate. For example, ops toggles tied to just one performance metric tend to be relatively static.
Operational toggle example
Our e-commerce company is preparing for a spike in traffic ahead of their popular annual sale. This will be the first such sale with the configurator in production. During testing, devs noticed the user-preferred B algorithm was a little greedy with system resources.
The operators ask for a kill switch to be coded for the configurator before the sale goes live. They just want a single toggle they need to click in their release management software should performance degrade. Lo and behold, on the first day of the sale, the configurator begins to degrade performance, and ops staff quickly kill it before too many users notice.
Permission toggles
Permission toggles are intended to be longer-lived or even permanent fixtures in your code. They are used as a method to make features available to specific subsets of users. For example, you might use a permission toggle to show premium content only to premium users logged into your site. Permission toggles tend to be the most dynamic of the four categories defined here, as they usually trigger on a per-user basis.
Permission toggle example
The simple example at the beginning of this article is close to what a permission toggle might look like. After the annual sale is complete, our e-commerce company decides algorithm B is too resource-intensive to make it available to their entire user population. Instead, they decide to make it a premium feature.
Feature toggles vs. feature flags
As a brief aside, there is some debate over the name feature toggle as opposed to feature flag. “Toggle” is a more appropriate name when code is turned on or off for a few major code branches. “Flag” is a more appropriate term if a decision point is followed by a very multi-conditional or broad set of codepaths.
Including feature toggles in your roadmap supports agile workflows
Applying feature toggles to your development process supports newer agile approaches. You can release software even while code sprints on new features are still in progress. Those features just need to be hidden behind toggles until they’re ready for release, market testing, or whatever the next stage in their development is.
You would usually write the user’s newly requested features on code branches under more traditional waterfall development models. Those features would then go through a lengthy testing and QA process before your team could integrate them back into trunk code. Using feature toggles, you can perform the entire development and testing process right on trunk code.
Our best practices for using feature toggles
As we’ve discussed, feature toggles are a powerful and flexible development method. If you don’t carefully implement and manage your toggles, they can quickly lead to a messy codebase or increased technical debt.
Many different best practices for coding feature toggles have been proposed, but we wanted to offer some of our own. Once one messy decision point is written into your codebase, many more seem to follow. Applying these best practices from the start will help keep problems like that in check.
Website code under development (Source)
Use feature toggles to gradually transition to agile development
If your team wants to try out agile development and testing methodologies without jumping entirely into a new development methodology, then introducing feature toggles into your roadmap is an excellent place to start. The cost to try them out is low. You could just have one team try using an experimental toggle for a single canary deployment they’re working on, for example.
If the trial goes well, you can replace that experimental toggle with an ops toggle when the feature goes into production. Then expand toggle use to other teams or other processes from there. Introduce them earlier in development cycles as release toggles. Then, slowly but surely, you’ll be on your way to full agile development.
Use toggles for both internal and external features
As should be clear by now, feature toggles have uses throughout the development and production lifecycle of your software. Don’t limit your toggle usage to just customer-visible features. You can use release and operational toggles to manage backend features too. They give DevOps teams a very granular level of control and risk management over code, which can be important when modifying backend features that have a wide-ranging impact on how your system performs.
Include toggle planning in your design phase
Everything from toggle naming, configuration settings, removal processes, and access control trickles down from how you first feature design new features. Build that toggle planning into your design process, and feature management six months from now will be greatly simplified.
Have a standardized toggle naming scheme
Many organizations use a style guide to regulate how developers write and organize code. For example, how they employ everything from spacing, ordering, and parentheses, to naming. If you’re going to use feature toggles, you should also standardize your naming style early in your toggle adoption process.
Brevity is essential in other aspects of coding, but when it comes to toggle names, be verbose. Detail means clarity. Verbose toggle names help devs and ops staff outside your core understand what they’re looking at when their only reference is the toggle name you chose on a whim six months ago.
Some other toggle naming conventions we suggest adopting include:
Include the team or the project name.
Include the toggle’s creation date.
Identify the flag’s category.
Be descriptive of the toggle’s actual behavior.
Here is an example: algteam_10-12-2021_Ops_configurator-killswitch
This name gives some useful information someone on any team can use to understand what they’re looking at when a toggle is called in an error message. They know who wrote the toggle, how long it has been sitting in the codebase, and what the toggle does.
This practice sounds self-evident, but it is an important point to underline. As we discussed above, feature toggles can be divided into four general categories. You should manage each of those four categories differently.
Think about our configurator example from earlier as it moved from development to market testing to operational management. The configurator code sat behind a feature toggle of one kind or another the entire time. But the way the development and product teams interact with that toggle needs to change at every stage.
During early development, the toggle might just be configured in source control. Then while the e-commerce company is doing A/B testing, the toggle might be in a feature management platform. When the ops team adds a kill switch, they may decide they want it in the same feature management platform but on a different dashboard.
Always expose feature toggle configurations
As with any other code object, it is beneficial to document feature toggle configurations as metadata, so other developers, testers, and production staff have a “paper trail” they can follow to understand precisely how your feature toggle runs in a given environment. Ideally, store your toggle configurations in a human-readable format so that it is easy for people outside your team to understand what a toggle does.
This best practice is beneficial for features you expect to be toggled for a long time. Think about our configurator example again. A brand new product operator trying to understand a sudden, unexpected performance slowdown will be very grateful to have a human-readable file explaining that the B algorithm was surprisingly resource-intensive in testing a year earlier.
Keep the holding costs of feature toggles in check
When first using feature toggles, try to resist the temptation to use them everywhere in your code all at once. While feature toggles are easy to create, their use requires proper management and testing to realize any benefit. Scale up your feature toggle usage slowly, or consider integrating a feature management platform into your development and testing environments.
Deploy feature toggles strategically and keep your inventory of toggles as low as possible. Use them wherever necessary, but make sure there is a process for vetting whether toggles are the appropriate method for solving a particular problem.
Don’t let old toggles hang around in your code. Prune them as soon as their lifecycle has run its course. The more idle toggles your code has, the greater the management overhead that falls on your team. You can manage toggle removal by adding code cleanup tasks to your team’s backlog or building the process into your management platform.
Keep toggle scope as small as possible
Since toggling can be so powerful, it is often tempting to put large swaths of code under the control of a complex series of toggles. Resist this urge and keep feature toggling within as small a scope as possible to complete any given task.
If a toggle overlaps more than one feature at a time, it can be confusing for the rest of your team and a nightmare to debug weeks or months down the road when it begins to impact other teams’ work.
Consider our configurator example again. Our dev team is building four separate widgets that users will manipulate within the configurator tool. In this scenario, we would recommend setting up five toggles: one for the configurator itself and one for each widget. Code the widget toggles with a dependency on the configurator toggle. In this framework, if one of the widgets fails to load correctly, the others will still be served to the user.
Feature toggles can transform your entire development process
Feature toggles are powerful methods for developing, testing, and operating code features within a continuous integration and continuous delivery framework. They are a simple method that helps your team deliver higher quality, more stable code according to agile principles.
In this article, we walked through how feature toggles work, what types of toggles you can create, and how you can employ them in your agile process — or try them out in any development process. We also shared some of our recommended best practices for making sure your company gets the most from using feature toggles.
Start small and scale up
There is no reason you can’t start using feature toggles today. Start small and scale up your usage as your team gets comfortable with how they work. If you’re starting to code a brand new feature from your backlog, consider setting up a release toggle in trunk code, so you don’t have to branch. If you’re beginning market testing, consider setting up an experiment toggle for some split testing.
Once your team has a good handle on how they want to use feature toggles, consider whether a feature management platform can streamline their administration. Streamlining development and testing was what we had in mind when we developed our release and feature management platform.
AB Tasty allows your team to use a single tool to streamline toggle workflows and communication. Regardless of a team’s tasks or focus, our feature management product has everything it takes to deliver the right features in the right way.
Here you are. You have taken the plunge and decided to create your own site using WordPress. Even better, you want to create a landing page to attract visitors and convert them into leads or buyers.
How to create a WordPress landing page?
When creating a WordPress landing page, you have several options:
You can use a “Builder” like Divi, Beaver or Elementor. It is a solution that is easy to understand, and you are in charge of creating the design.
You can use a “Plugin” available on WordPress; plugins allow you to create pages fairly quickly but are limited in terms of functionality.
You can use your WordPress theme; this is the solution we’ll cover today.
A theme is a ready-to-use design; in our case, these are landing pages that have already been designed. You just customize the design of your choice with your company’s colors and logo. See other great examples of landing page design.
One of the major strengths of WordPress is the variety of themes available to you. There are thousands of templates, some of which are real bestsellers. They are:
Recognized by the sector
Frequently updated
Easy to use
Attractive and effective
But which WordPress theme should you choose? Before giving you our selection, we would like to draw your attention to the elements that define a good landing page.
These eight elements ensure a landing page is effective, and it is important to keep them in mind when choosing your theme. Have a look at our 2019 landing page optimization guide.
Now that you have a better idea of what makes a “good” landing page, here is our selection.
10 WordPress landing pages templates to use right now
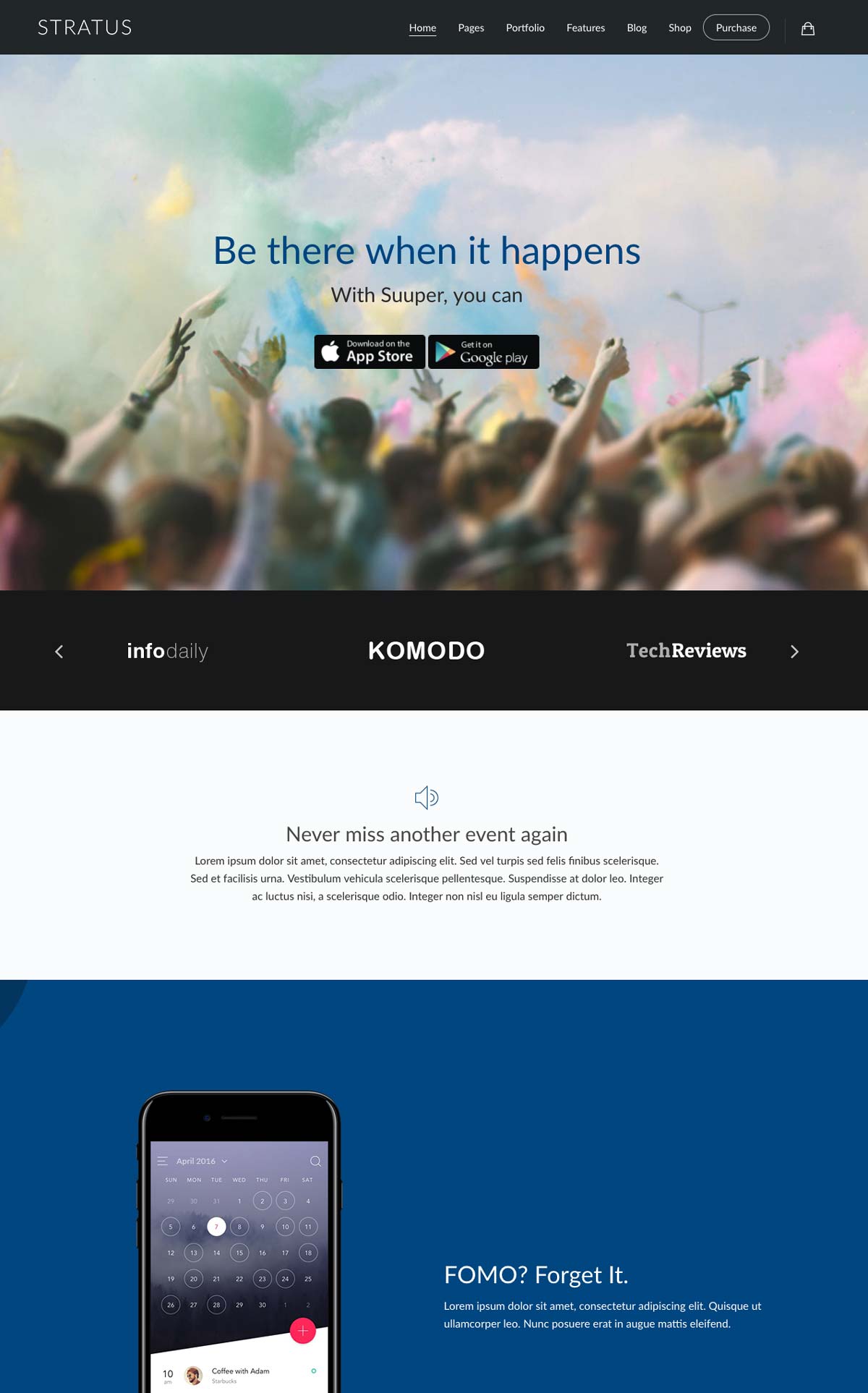
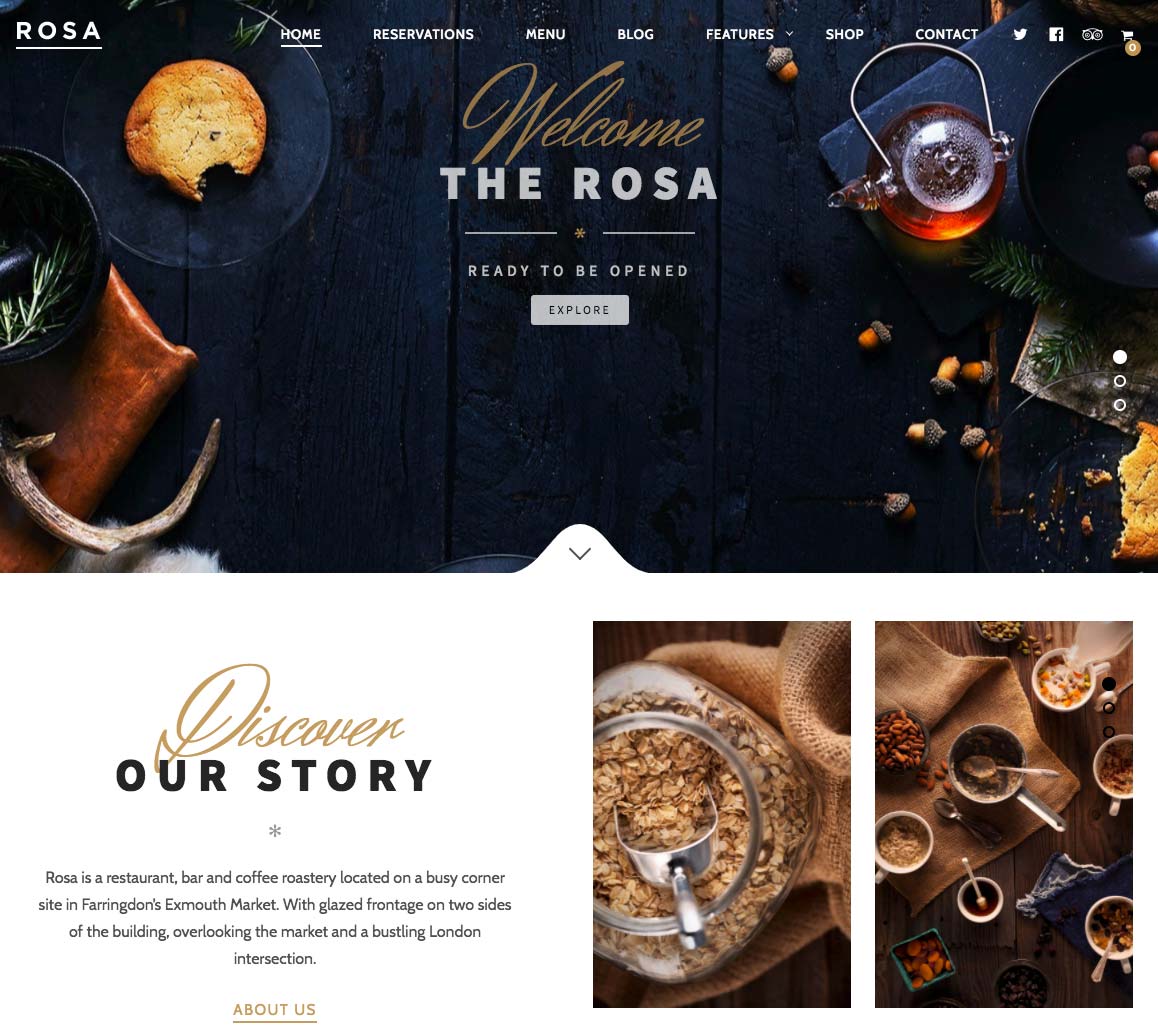
STRATUS
Stratus is a WordPress theme designed for SaaS companies, app developers or those presenting a technology product. You edit it using a “drag and drop” system which makes using and customizing your WordPress landing page easy and intuitive.
It is complete and powerful, and it meets all the criteria of a “good landing page” and contains:
40 widgets for you to personalize
20 page templates
An infinite number of possible designs
Another interesting characteristic of Stratus: its versatility. Stratus is easy to customize and already contains several types of landing pages to suit your core business: SaaS, technology products, or mobile applications.
Flatsome is a WordPress E-Commerce template. This is a WooCommerce theme (which is a free e-commerce plugin for WordPress).
Flatsome is complete and intuitive and is the Swiss knife of WordPress E-commerce.
Frequently updated, it is a bestseller that has registered more than 60,000 sales since its creation: it has a community and a strong reputation among users of WooCommerce.
100% responsive, it uses an intuitive and fast-to-implement builder page that does not require programming skills.
Like for Stratus, the builder works using a “drag and drop” interface which makes the template easy to use.
The template includes nice parallax effects, countdowns, and fields to subscribe to a newsletter; these are great assets to start an e-commerce site.
Uncode is a perfect WordPress template for agencies, freelancers, creatives, and all companies/people who want to present a project, an idea, or a portfolio.
Its impressive library of ready-to-use items makes it a must-have in the industry: Uncode easily adapts to your custom design to create a truly unique site.
Perfect for sites that want to host media, Uncode is designed to embed content from Facebook, Instagram, YouTube, SoundCloud, Spotify, and more.
Something really nice with Uncode: the design is refined and well thought out.
The color schemes are well chosen, and the blocks are in harmony with each other; we can also see that the calls to action stand out from the rest of the page.
In summary: Uncode is a very good base to start your WordPress landing page.
Who said that real estate companies couldn’t have a landing page? In any case, this WordPress template is the ultimate weapon for all agencies or players in real estate.
Designed to present real estate agencies or independent actors, this theme also allows visitors to submit their properties online for a flat fee, a subscription, or for free: perfect for adding to your listings!
To make your task even easier, 12 ready-to-use demos are available in the pack; you can create your agency’s website in just a few minutes.
A map is included in the basic template, which is a real plus for real estate agencies. You can easily show where the property for sale or rent is located. Your users will love it!
We can also see the “grid” layout for property listings that add clarity. The (easily customizable) color scheme highlights real estate well.
The template can include a blog and a newsletter subscription module: a must-have to develop your audience and engage with relevant news.
On this version of the “Rio” template, we love the extensive search bar with a price slider: it makes browsing easier and lets you display relevant results to visitors.
Similarly, the ability to filter property listings as the visitor desires lets the site display results adapted to each visitor faster.
Increasingly popular, e-learning is gaining a prominent place in the world of e-commerce. Accessible and often cheap, internet users love online video courses. However, the resources needed to create an e-learning site sometimes turned entrepreneurs off. That’s over!
Education WP is an ultra-comprehensive template that lets you create your online course website quickly and without programming.
The template contains several themes adapted to the different types of education players:
Elementary/Middle/High Schools
Universities
E-learning
Training centers
Childcare centers
Using the same “drag and drop” concept as Stratus & Flatsome, the Education WP builder is intuitive and easy to use.
The template is 100% responsive, optimized for SEO and UX, and contains 10 pre-loaded themes ready to use.
Since it is a market bestseller, the template is updated very often and has community support.
We could put it in 7th place in this selection, but that might have been confusing!
“The 7” is a fully complete WordPress template. It’s so complete that you can do almost anything with it.
This is a very successful general template that lets you showcase your business easily, no matter its sector of activity.
Here are some suggestions for industries that might use “The 7”:
Corporations, big businesses
All sorts of agencies
All kinds of e-commerce sites
Small and medium businesses
Schools, education institutions
Events
Building and construction
Hair salons and small shops
etc.
Here are two possible uses (among dozens) of “The 7”:
Xstore is a high-performance e-commerce landing page template for WooCommerce, suitable for a large number of activities.
It has a variety of themes with very lively and attractive colors.
Completely responsive, Xstore is a tool to put in the hands of every SMB that wants to embark on e-commerce or renovate their site.
The special feature of Xstore is its large library of ready-to-use “blinds”: a total of more than 70 online stores are at your disposal to create the shop of your dreams.
A bestseller in its category, Xstore offers online documentation and videos, which is a major advantage compared to other templates that do not provide documentation to help you build your site.
Among other things, here are some areas of activity for which Xstore is particularly suitable for creating your future e-shop:
Restaurants
Mobile applications
Spa/Health/Fitness
Hair salons /Barbershops/Small businesses
Fashion, retail, and accessories
Lingerie, sporting goods, technology products
On Xstore, we especially appreciate the attention paid to the design of buttons, forms, and icons that are particularly refined.
The general impression is very qualitative and very impressive: the fields are well positioned, and the site architecture is well thought out.
Overall, Xstore is an excellent base for an e-commerce site.
Medical Press is a WordPress landing page template designed for companies, professionals, and clinics in the healthcare sector.
It offers several styles variations (header, body, footer) as well as several types of forms: handy to customize them to fit with your organization’s image.
The template is responsive and compatible with e-commerce; you can use it to present your activities, book appointments, and sell medical devices or services.
On the whole, Medical Press is a very good theme. We particularly like the choice of colors and buttons and the ability to include blocks for presenting practitioners and services.
The template also contains (written) documentation, which is practical for editing page content.
CRO: A Complete Guide to Conversion Rate Optimization
Anthony Brebion
Here’s the ugly truth: 78% percent of companies are dissatisfied with their conversion rates. While this is a reassuring sign of awareness, it also means that converting more visitors into customers (aka CRO, or Conversion Rate Optimization) is a major challenge encountered by most companies.
As a marketer, chances are that you’re also facing important business challenges related to conversion optimization. If so, you came to the right place.
In this guide, we will provide an extensive overview of conversion rate optimization in order to provide you with the strategies, tools and expert insights necessary to run successful CRO campaigns.
Conversion Rate Optimization Guide Index
What is Conversion Rate Optimization (CRO)?
Conversion Rate Optimization, often abbreviated to ‘CRO’, is the process by which online companies optimize their digital assets in order to drive more visitors towards a desired action.
At this point, you may think, “Well hold on a second, I thought that CRO was about turning visitors into customers”. While this isn’t totally wrong, not all websites are meant to attract new customers. Some websites are informative or media-driven, which means that a “video view” or a “newsletter subscription” would also count as a conversion for them.
Depending on your website’s primary goal, CRO will thus be about converting passive visitors into active visitors in a way that meets your marketing objectives. To put it simply, CRO means using user insights and analytics to improve your key performance indicators.
Need a refresher on CRO jargon? Check out our Conversion Optimization Glossary with 60+ terms every marketing professional should be familiar with.
Why is CRO so valuable for companies?
Imagine that you run Adidas.com (15M visitors per month) and decide that you need to increase yearly ecommerce revenues by 10%.
For this example, we’ll assume that your Adidas.com has a 1.5% conversion rate and a fixed $80 average order value, which gives us 2.7M orders per year for an estimated result of $216M in annual revenues.
At this point, you have 3 options:
Drive more traffic (but this will cost a lot)
Add more products (which means production costs)
Converting more visitors into customers (easiest solution)
The two first options have big drawbacks: they mean heavy investments in paid advertizing, SEO, social media, and HR. While you could potentially do it, nothing proves that the costs won’t exceed the benefits of such actions.
That’s where conversion rate optimization really comes in handy.
Instead of acquiring 1.5M additional visitors per month (assuming they would convert as much as the current ones), you could tweak some of your website attributes in order to increase your conversions accordingly.
In order to gain 10% more in annual revenues, you would need to generate an additional $21.6M in sales. For that goal to come true, you’ll need to convert 270,000 more visitors on a yearly basis.
That’s the good thing about CRO: small changes yield big results.
Here’s the good news: in order to generate an uplift of 10% in annual revenues, you just need to move the needle from a 1.5% to a 1.65% conversion rate. You heard right, a 10% increase for your conversion rate could potentially lead to a 10% uplift in annual sales.
Defining key objectives for your CRO campaigns
No marketing campaign should be run without precise objectives in mind. In fact, it’s not even possible to come up with a decent CRO strategy without setting up clear goals and monitoring the right KPIs.
As we said earlier in our attempt to define conversion rate optimization, not all websites have similar goals. Before launching any CRO campaign, you should try to define your key objectives:
For ecommerce websites
If you run an ecommerce website, chances are that you are looking to increase sales. And that’s perfectly fine. There are many ways to improve ecommerce conversions. So many that it would take hours just to list them all.
Generating more income should definitely be one of your main goals, although CRO may require that you come up with more detailed objectives.
Here are a couple of goals that you could try to achieve:
Media and social media websites are typically known for generating tons and tons of monthly visitors because they create so much content. And that’s a good news.
However, converting visitors into paying customers or subscribers is a big challenge that requires extensive marketing tricks and campaigns to be solved. From paywalls to video content, banners and ebooks; there also are many ways to increase conversions on a media website.
Here are a couple of goals that you could try to achieve:
Convert more readers into subscribers
Increase your monthly ebooks downloads
Convince more visitors to subscribe to a webinar
Increase your newsletter’s click-through-rate
Attract more guest posters
Generate more link sharing
Convert more visitors to social media followers
Increase your page views
Generate more leads from blog posts
Setting up a friendly CRO environment
Testing and optimizing for conversions requires one to take on a scientific approach in order to obtain unbiased and statistically relevant results. To do so, you will need to leverage different tools to combine the collected data.
Collecting data is a massive time-saver and you’ll get to know:
Who’s your audience?
What are they looking for?
Where do they come from?
What is their search intent?
What pages do they visit?
How long do they stay on your website?
How many visitors convert into customers?
For starters, you should use Google Analytics or Adobe Analytics to gain precious insights on your visitors’ demographics and behaviors. From there, plugging your website into one of these tools will allow you to create so-called “funnels” that will quantify your conversion rate at every step of the buyer’s journey. If you haven’t read it yet, we made a complete survival guide that provides tips on how to optimize an ecommerce conversion funnel.
The idea behind the conversion funnel (or ‘purchase funnel’, ‘sales funnel’…) is the funnel metaphor: many people will land on your site, and only a small percentage will actually end up buying.
Seen through this conversion funnel, your visitors frequently encounter conversion obstacles that curb your conversion rate. In marketing terms, we define these obstacles as elements of “friction”: the more friction your website generates, the fewer visitors you’ll convert.
At this point, data analysis is meant to provide you with insights to determine the stage(s) at which your visitors don’t behave according to the plan.
Picture this: your website is a bucket that you fill with water to bring traffic using paid ads, Google Adwords, SEO, social media campaigns… At some point of your conversion funnel, you notice that a heavy part of your visitors are leaving: some water is definitely leaking. Knowing why your bucket is leaking should then be your number one priority before trying to add any more water.
Understanding your users’ behavior is a critical issue that sets up the basic assumptions needed before running any CRO campaign. But there are many other tools available to gain insights on your audience. Here are our top 3 tools to collect visitor data:
Session Recording
Live recording your visitors while they navigate your website is a brilliant opportunity that allows your team to better understand their behavior and interactions. Using this tool, you’ll put yourself in your visitors’ shoes in the most natural and unbiased way.
Heatmaps
Heatmaps are meant to map out your website and see which parts get the most clicks and attention from your visitors. Basically, heatmaps record your website’s activity and display the areas where your visitors click the most and spend the most time. Testing your assumptions using heatmaps is a smart move that helps you determine whether or not your visitors are flowing down the conversion funnel.
Surveys and User Feedback
Adding an on-site survey tool allows your team to gather feedback about your visitors’ satisfaction and their likeliness to recommend your services (net promoter score). Are you looking for these tools ? We provide all of them in our Data Insights features. Click here to schedule a demo.
Keys to a successful conversion optimization strategy
When evaluating your conversion rates, here are some steps to consider:
Identify obstacles
Attract qualified traffic
Make your message easy to understand
Meet your visitors’ expectations with a relevant offer
Make sure technical issues are avoided
Minimize the efforts required of your users
Identify obstacles
You should start with a meticulous evaluation of your website to identify existing obstacles to conversion. By identifying “leaks” in your conversion funnel and trying to determine the likely causes through qualitative and quantitative data collected through your web analytics tool, you can find out which web pages are likely to pose a problem and understand your users’ behavior. This way, you will know where to focus your efforts and get off to a running start on your CRO.
Attract qualified traffic
To optimize your conversions, you need to take the time to work on your acquisition sources in order to attract traffic that is as qualified as possible and truly interested in what you are offering.
The moment a visitor reaches your site, he has already been exposed to your message and is already as informed as possible about your offer, and thus more likely to convert.
How can you go about this? First, you must be as well placed as possible in your sector’s main keywords by targeting words specific to your offer to give you the best chance of optimizing your conversion rate. Work on your AdWords advertising by setting up highly targeted adverts specific to each audience segment. You can also adapt your Search Engine Optimization efforts to bring more qualified leads. Finally, use affiliation by placing advertisements on websites near or in your sector to reach an audience similar to yours who will be more likely to be interested and convert.
Make your message easy to understand
Your site must have a message that is easy to understand if you want it to have a good conversion rate. Identify the message you want to send (AKA: value proposition) and optimize how it’s included on your website.
By identifying your product/offer’s specificities and advantages and testing their success among your audience by offering, for example, faster delivery than your competitors, you can determine what benefits to highlight to strengthen your value proposition and CRO. Once you’ve clearly identified your value proposition, make sure it is clearly presented to your visitors. By testing different ways of presenting data, you’ll find the one that works best among your audience and come to a clear and simple navigation for your website that will speed up your visitors’ conversion.
Meet your visitors’ expectations with a relevant offer
In order to convert, each user that arrives on your website must find an offer that meets his particular needs. To not disappoint the visitors on your website, you must guarantee the greatest coherence possible between the message sent by your acquisition sources and the message on the web page where your visitors arrive; using the same language and terms will help you optimize your conversions. Your offer will be seen as relevant if visitors find what they were expecting and what they were promised on the web page where they arrive.
In order for a CRO program to be complete, it must also include performance. You must reduce the loading time of your website pages as much as possible. No matter which optimizations you make on your page, they will have no impact on conversions if the web page itself takes too long to load. A loading time that is too long could not only cause your visitors to flee out of boredom, but also damage the trust users have in your website and reduce your website’s conversion rate.
Not only should your buying process be smooth, but your site and product pages should be as well: letting a user wander freely and quickly through your products is important as it’s a form of engagement that has an indirect effect on your conversions.
Minimize the efforts required of your users
This step’s aim is to reduce to a minimum the friction that a user encounters, and simplify the experience as much as possible to encourage conversions on your website. Your site must offer clear and concise navigation since the user won’t spend much time trying to understand a complex navigation system.
Faceted navigation will let the user go through your catalog by adapting his search criteria on the fly instead of navigating from section to section. For your forms, only ask for essential information since having too many fields to fill out will cause your visitors to leave.
Wrapping it up
Conversion optimization is a science on its own that requires marketing teams’ time and patience. Besides, CRO requires a decent amount of traffic to generate statistically viable results through A/B testing, although smaller websites can also benefit from CRO if done correctly.
In the end, high-performing websites use A/B testing and CRO solutions to empower their stores and websites in order to generate massive uplifts in sales and conversions.
The internet has come a long way since we last saw flashy, super intrusive popping banners packed with sound that tried to convince us to download a dodgy software.
In fact, many users and marketers have forged pop-ups a bad reputation over the last 10 years, encouraged by new digital marketing trends that promote smoother, user-friendly funnels using Facebook Ads, content marketing or landing pages.
Over the years, pop-ups (that would typically open in a new window) have been largely replaced by “boxes” that open in the same window. In fact, it’s no surprise that pop-ups still work and deliver good results if they provide real value for users.
Here are our expert tips to create pop-ups that actually work. Interested in more conversion optimization tips? Read our complete guide to CRO.
Wait: should we still use pop-ups in 2020?
Over the last five years, internet users and web browsers have fought sketchy third-party banners that would basically ruin any website’s user experience.
Besides, ad blockers have emerged as a popular option to shield visitors from being overwhelmed by flashy, dodgy pop-ups: Business Insider reports that 30% of all internet users now use ad-blockers on a daily basis.
At this point, you may think that pop-ups have become irrelevant and that no one would click them in 2020.
But it’s not true.
In fact, BlogMarketingAcademy reports that pop-ups can deliver decent click-through-rates of around 2% if used correctly; which is above some of the most commonly used channels.
Whether or not your pop-ups campaign will succeed will depend on many factors including your website content and your personas.
If you also believe that pop-ups still deliver good results, check out these tips to implement a pop-up strategy that works.
Define your marketing objectives
Implementing pop-ups on your website has to fulfill a goal: otherwise it’s just pure unnecessary noise that will distract your visitors away from your content.
Depending on your website, pop-ups can be used to achieve a variety of goals.
Drive more sales
Pop-ups are a convenient tool to drive more sales using well-known marketing techniques such as up-selling, cross-selling and cart abandonment reduction.
For ecommerce websites, pop-ups can be timed around an “exit intent” (i.e they are triggered when a user wants to leave) in order to promote a last-second offer to re-engage your visitors.
Using pop-ups, you can offer your visitors a last chance and eventually convert them into additional customers, which is excellent news if you’re trying to increase your ecommerce conversion rate.
Harvest emails
Growing your email list is a tricky task that just became even harder under the European GDPR regulation that yielded unprecedented changes in the data privacy policies that websites now have to abide by.
Whether you have activities in Europe or not, collecting email addresses generally requires your visitors to opt-in, which can conveniently be achieved using pop-ups.
Made.com uses a central pop-up to grow their email list by offering 10£ in exchange for a newsletter subscription: this is a good incentive to grow your email list. Because you can easily click away, the pop-up doesn’t disturb visitors that much: they can simply close it and keep on shopping.
Generate leads
On that matter, pop-ups can be used as a complementary tool to your content marketing efforts, just like HubSpot does by displaying pop-ups in their articles.
While their visitors read, Hubspot displays a “fake” pop-up chat box that redirects you to an ebook landing page which ultimately asks for your email address: this is a smart strategy that provides value in exchange for an email address.
Improve customer experience
Getting feedback and improving user experience is a major challenge faced by most serious ecommerce and lead generation websites.
Although they weren’t specifically created for that purpose, pop-ups can play a great role in harvesting feedback and improving user experience.
For instance, using AB Tasty’s Net Promoter Score tool (i.e how likely are your visitors to recommend you), you can instantly generate feedback for your ecommerce or services while analyzing real-time data in order to run further optimization tests based on your discoveries.
Choose the right pop-ups for your audience
There are many types of pop-ups that are more or less efficient depending on your strategy. In fact, some industries require more aggressive practices than others: it all depends on your marketing personas and price range.
Here are the 5 main types of pop-ups that you could use:
Entry pop-ups
These are pop-ups that are triggered at the moment your visitors land on your website. Although they might work in some cases (language selection, age restriction, disclaimer, exceptional offer, major news…), they’re generally not happily welcomed by your visitors because of their intrusive nature.
Scroll-based pop-ups
Scroll-based pop-ups are typically activated after a visitor has scrolled to a certain depth (e.g 25% of the page for example). Because these pop-ups only activate after a proof of engagement, they tend to yield slightly better results and work particularly well on articles and blog posts although some ecommerce websites may use them as well.
Delayed pop-ups
Delayed pop-ups are triggered after a visitor has spent a certain amount of time on your website. Similarly to scroll-based pop-ups, they’re only activated after a proof of engagement.
Interaction-based pop-ups
These pop-ups come in handy for marketing teams interested in personalized experiences. Basically, interaction-based pop-ups are triggered once a visitor has clicked or hovered over a specific element. Contrary to delayed or entry pop-ups, they allow your team to create personalized experience based on your visitors’ behavior.
Exit intent pop-ups
Exit pop-ups are triggered once a visitor is about to leave your page. These pop-ups are famous in the ecommerce industry as an effective tool to reduce cart abandonment rate. They can also be used to generate leads or collect email addresses.
You can easily run all these pop-ups using a customer activation platform like AB Tasty. Our
Provide value to your audience
Perhaps the most important rule to bear in mind while implementing a pop-up strategy: always provide value to your audience. Creating and displaying pop-ups on your website that don’t deliver any kind of useful information or value to your visitors is extremely risky.
Backcountry – a famous outdoor equipment ecommerce – uses a large pop-up to indicate that their website isn’t available for European customers. It then redirects you to another website that is GDPR compliant.
Remember: mobile users are extremely demanding when it comes to mobile experience.
Before launching any new pop-ups on your website, take some time to check your mobile version and see if anything could be improved.
Optimize your mobile pop-ups for SEO
After Google announced its mobile-first indexing, the firm also updated its algorithm to penalize intrusive mobile interstitials that would hide the main content on a mobile website.
As a rule of thumb, keep this in mind: do not display pop-ups that cover the main content or hamper the user experience.
Based on these guidelines, your mobile pop-ups should complement the user experience rather than restrain it.
Here’s a diagram from Google that summarizes it quite clearly:
With that in mind, you have all the information to carefully run pop-up campaigns that will drive conversions without hurting user experience or your search rankings.
How Creating Personas Can Help You Personalize Your Website
Anthony Brebion
Personas are one of the most important marketing tools a business has in the current age. It is broad enough that it does not require huge resources to implement in the way personalization does, yet specific enough to inform design teams and capture the attention and loyalty of customers. It requires creative thinking, hard data and a tacit understanding of customers traits, requirements and expectations.
What Is Persona
A customer persona is a broad, fictional character that a business creates from data related to their customer’s needs, wants, traits and goals. While a persona is not an actual person, it is based on real-world characteristics of a business’s customer base and can also include potential customers, depending on the research carried out.
Personas essentially narrow the parameters and refine the focus of business practices to suit the specific, yet broad needs of their customers. They do this by creating main groups that represent the major users of a website and what their needs are.
Persona Vs Cognitive Styles
There is some confusion between the definition of a cognitive style and that of a persona. This is further confused by the fact that few definitions of cognitive style are agreed upon and that there is some crossover between the concept and that of personas.
As previously described, personas are broad, fictitious characters that help define the parameters of certain aspects of a business and its targeted audience or customer base. Cognitive styles, on the other hand, is a thinking style, a personality trait if you will, that describes the way an individual might perceive specific information. As such, it is a lot more complex and individual. Unlike personas, cognitive styles are hard-wired and therefore unchanging. In practice, a persona has little to do with cognitive style, but cognitive styles can inform the creation of a persona, alongside other data.
Benefits Of Creating Personas
Creating personas has many benefits, providing the correct level of research has been carried out. In some ways, customer personas are a method of simplification.
Once a business understands the broad needs and expectations of its customers, it can act accordingly. This narrowing of the parameters can focus attention in the right areas with specified ideas.
For example, the design of a website, from its wireframe to even the color scheme, can be refined with the right type of data to hand, informing the entire design team of what is required. Meanwhile, new ideas can be refined and focused with customer needs in mind, rather than the hit or miss, typically miss, of implementing ideas on hunches and whims.
Types Of Personas
Customer personas are typically divided into types and are highly dependent on the goals of the business creating them. While there is a lot of crossover, not to mention debate, four of the most commonly defined types are:
Goal Personas
Role Personas
Engaging Personas
Fictional Personas
Goal Personas
One of the simplest, yet most important, is the goal-oriented persona. This is essentially predicting what the customer is looking for from a product or service. The goal-oriented persona is one that has already been defined to some degree, based on data. Goal-based personas are created in three ways. The persona itself (the type of person defined by the group), the scenario (which essentially describes the narrative of the interaction- where, how and why) and the goal itself, which is the persona’s motivation and needs.
Role Personas
One of the most data dependent of the four roles is the role persona. There is a lot of crossover with the goal persona in that it is highly behavioral, but it looks at it from a different perspective. In some ways, the role-based persona is a more empathetic perspective as it looks at the user’s role, rather than wants and issues they may face. For example, what does the persona’s role require? Exactly how will the product be used and in what environment? What are the pressures and requirement of the persona’s role in the day to day running of the business? This persona requires both qualitative and quantitative data, and as such it might need to be highly specific. In this sense, it can spill over into personalization, more on that later.
Engaging Personas
One of the pitfalls of creating personas is the tendency to drift into a stereotype. A stereotype is the practice of assumption, putting people, even groups, into neat boxes based on previously held ideas and not data, the exact opposite of personas. Engaging personas are, broadly speaking, a mix of the role and goal-based personas and are used by designers to fill out the persona to form a rounded character. The most empathetic of the types, engaging personas are created by describing the feelings and backgrounds while creating stories that help designers formulate ideas that engage customers on a more profound level.
Fictional Personas
While all personas are fictional in the sense that they are characters created that represent major groups, they are based on hard data. Fictional personas, instead, are those created by UX design and are based on their experience with customers. Fictional personas are always assumed to be flawed on a fundamental level due to the amount of assumption involved in their creation, but by engaging the design team in the decision process, some wisdom can be attained that would be unlikely to show up in the data.
How To Create Personas?
It is one thing understanding how personas work, but quite another understanding of how to create personas. As with anything that appears complex at the start, taking it step-by-step is key.
Where To Start?
Customer Personas should be created at the very beginning of a project. This does require some planning, but like the much-used analogy of house building, the foundations should be the first thing that is built, not the roof.
As is generally the case with planning at the start of a project, defining the goals is important. This, in turn, will define what type and how many personas will be required. Each project is unique, but the one hard and fast rule regarding personas is sticking to the major audience groups for the site. It should also be remembered that personas are not individuals, rather they are fictionally created individuals that represent these major groups.
From here on it is all about research. Find out:
What are your customers’ behaviors?
Who are they?
Why are they using your website?
What are their expectations?
What Does A Customer Persona Consist Of?
Each customer persona consists of various traits, what these are will depend to some degree on the business, the goals of the project and the purpose of the website. There are, however, some tried and tested elements that remain ubiquitous when creating personas.
Firstly, there is the persona group, which can include the job role, as described earlier. This will include responsibilities and issues the person might face in their day to day life. Another important factor will be demographics. This includes age, ethnicity, gender, identity and marital status. Goals are a mainstay in persona creation as they refine the previously mentioned inherent and status-based traits and personalize them further, allowing you to create a more accurate persona. Lastly, the environment can be a large factor, particularly if the service is international.
Best Practices When Creating Buyer Personas
Although each project might be different, there are some best practices that are relevant for just about every project. To begin with, while personas are fictional, making them as real as possible, and therefore as relatable as possible, means that it will help the design team create and relate to the persona they are producing the website for.
Typically, it is best practice to create three to five personas per project (occasionally up to seven) as this number provides the range of traits that is required to truly represent actual and potential customers.
One of the most common mistakes when it comes to creating personas is to drift into stereotyping. This is understandable to some degree as it is an attempt to deal with general traits rather than individual ones. As previously mentioned, stereotypes are assumptions, unthinking and informed by bias, both implicit and explicit. Generalizations, however, are not explicitly stereotypes, and in the case of personas, are informed by hard data.
Examples
Each persona should be given a name to which they are referred to. You can also add a generic profile picture that represents the persona in a broad sense.
The persona should be rounded and believable, but that does not mean they need to be complex psychological profiles. Personas range from rather broad to highly detailed, but they should never be beyond the understanding of your team or your customer’s comprehension. It is therefore best to avoid being too personal.
Note the use of a profile picture to engender an empathy with the character.
The detailed purchasing behavior section helps Ecommerce professionals create concise but detailed information to inform on a more profound level.
Personas can help a business relate to groups that are not necessarily their own. In this way, a business can be informed about Millennial customers, whether or not they are of the same generation.
How To Use Personas
After creating buyer personas, the next step is to implement them. This involves avoiding some pitfalls that can derail the entire project, or at least make the endeavor a waste of time and resources.
The first obstacle often occurs before the project has gotten going. For some, there is an inherent mistrust of personas, typically by stakeholders or management who believe that humans cannot be defined by the broad strokes that are part of the practice of creating personas. This in itself is a misunderstanding: personas are not meant to appear as individual, like with personalization techniques, but are instead helpful parameters within which ideas can be focused. One way in which this can be avoided is by showing the vast amount of data that goes into creating each persona and the thought processes that create them.
Fundamentally misunderstanding what a persona is and how it should be implemented is particularly toxic when it comes to the UX design team. One of the worst practices when implementing personas is attempting to use a previously successful persona wholesale for a new project. This is the equivalent of forcing a square peg into a round hole, it simply won’t work. Personas may be broad and representative, but they are also unique.
Personas In Web Personalization
As previously mentioned, personas are not personalization. Although there is some crossover between the two, and their goals are similar, when looking at the detail of the nitty gritty, it is clear the two are opposites of sorts. That being said, personas can be a hugely helpful first step in understanding the complex world of personalization, and, more importantly, a first step in its direction.
How Can Personas Be Used In Personalization?
Because personalization is a multi-levelled concept to implement, starting along the road to its full implementation is often a productive way to start. Personas are a great way to do this as they specify the practice without getting into the complex details inherent in personalization, such as minute data, privacy rules and content.
It would be helpful at this point to note the differences between personas and segmentation. Personalization audience segmentation is another step on the ladder towards personalization. It is more specific then a persona, and therefore more complex and granular in its use of data. For example, a persona might describe certain traits and needs of a group (wants information on vegan food products) while segmentation will divide this group further (wants information on organic or gluten free vegan products).
The Persona’s Life Cycle
Customer personas are not the scaffolding of the house, they are the decoration, and as such, they need to change with the times. Many things can affect a persona’s life cycle, changes in technology, fashion, economics and demographics can all require changes in the persona profiles. Therefore, it is essential to stay on top of any changes that might be required.
The Persona Based Concept Of Service Mass Customization
Mass customization has grown enormously in recent years, offering customers the chance to modify products to suit their needs and tastes, and is particularly popular within the fashion retail sector. However, it is growing as a concept as more and more people seek to “Personalize” as an expression of individuality.
Personas are one of the main tools for creating mass customization platforms as they are specific enough to inform, yet broad enough to maintain a sense of individuality. Personas can be created to narrow the parameters of a mass customization platform to make it manageable for the manufacturer, while still providing the choice that customers crave in 2018.