During peak traffic season, the topic of code freezes often comes up as a way to deal with the influx of exceptionally high traffic during that time.
Code freezes may seem like an outdated concept nowadays, a leftover from the days when rigid Waterfall methodologies offered the only option for product development and release.
The whole concept of stopping production and delaying release—just to test for bugs and other functional issues—has no place in Agile and DevOps practices where code is tested and verified at each stage of the development process.
At least that seems to be the general consensus for many tech teams.
But does it hold up? Once you scratch the surface of the most common arguments against incorporating code freezes into Agile product management, will they still seem archaic?
In this article, we’ll explore the three main arguments against incorporating code freezes into your Agile product management, and we’ll break down where those arguments fall apart, all to help you make a better decision about whether or not you should incorporate code freezes into your organization’s workflows.
What’s a code freeze?
We will first start with what a code freeze actually is to understand whether it still has a place in modern software development.
A code freeze is a traditional practice among developers to stop making changes or pushing new code to ensure site or app stability during a certain period of time. A code freeze is usually implemented during periods when higher traffic than normal is expected, particularly for e-commerce websites during the holiday season.
What does this mean? During busy periods in the e-commerce industry, you are temporarily refraining from making any changes to the website. Any changes to impact the user experience during peak traffic time can ultimately result in a loss of conversions and profit.
In other words, a code freeze is done as a way to safeguard against any potential mishaps because of the extra load on a website.
Let’s look at a practical example: developers decide to introduce a new code change during Black Friday when there is a high volume of traffic with shoppers looking to get the best deals. However, it turns out that there’s a bug they hadn’t anticipated. With the website facing downtime as developers quickly attempt to fix the issue, this may result in loss of potential revenue as customers are unable to complete their purchases.
To avoid this worst case scenario, developers instead impose a code freeze time, a time where no more code changes are made. This is done to ensure a website is up and running without any issues until this high traffic period ends.
What does an Agile methodology entail?
We will discuss the idea behind the Agile concept to better determine whether it aligns with code freezes before we explore the most common arguments against them.
The Agile methodology seeks to break up projects into regularly iterated cycles known as sprints and is largely driven by consumer feedback. This helps teams deliver more value to consumers quickly.
In other words, this methodology encourages continuous iteration and improvement of products and testing throughout the software development life cycle.
By breaking down development into sprints, cycle time is reduced, increasing speed-to-market and allowing teams to respond to market demands faster.
With this in mind, a code freeze may potentially reduce the ability for teams to quickly deliver value as they impose a freeze period.
Next, we’ll look at some of the common arguments against code freezes in the context of an Agile methodology.
Argument 1: Code Freezes are Irrelevant and Unnecessary
This argument is pretty simple and concrete— modern Agile methodologies and tools have eliminated the need for a dedicated QA and testing window.
Agile methodologies such as peer code reviews, pair programming, and the constant monitoring of system health give you much greater visibility into an application or feature’s performance while it’s being developed. Bugs and issues are easier, and more likely, to be caught during development itself, and resolved prior to any dedicated testing and QA activities.
The more refined your approach to Agile, the more you will try to shrink this window of time. The most refined current approaches to Agile are Continuous Integration and Continuous Deployment (CI/CD),
These processes aim to break development into small, incremental changes in order to “release” changes to the code as quickly as possible. In the purest application of CI/CD, development and release barely exist as distinct phases— new code is integrated into the application almost as soon as it’s completed.
New tools have also automated many tests. They constantly evaluate code to make sure it’s clean and ready for production at all times. Issues are identified in real-time, and alerts are immediately sent out to resolve them, reducing the volume of manual tests that need to be performed.
The result of these new Agile methodologies and tools is easy to see. Most of the core testing and QA activities performed during a code freeze are either being performed during development, or performed by software.
In Agile, software and features now exit development at a much higher level of confidence than they used to, making a dedicated code freeze harder and harder to justify.
Argument 2: Code Freezes Break a Core Agile Principle
This second argument is a little higher-level. Basically, it argues that code freezes don’t have a home in Agile methodology because they break one of this methodology’s core principles— reducing the time between development and release.
By contrast, you need to maintain distinct development and release phases if you’re going to deploy code freezes. After all, that’s where the code freeze lives— in between those two distinct phases.
Instead of trying to minimize or eliminate that window of time between development and release like most of Agile methodology, code freezes force you to formalize this window to the point that you need to build your development and release schedules around it.
If code freezes don’t align with core Agile principles, then it’s hard to make the case that they still belong in the methodology.
Argument 3: Code Freezes Lead to Slower, Lower-Quality Releases
This final argument is a big one, and it includes a few different angles.
Firstly, it argues that code freezes add a lot of complexity and additional moving parts to your roadmap, and naturally increase the chances that something will go wrong and throw off your timeline.
Even if nothing goes wrong, the work involved in code freezes is time-consuming and unpredictable (as you don’t know what bugs you will find or how long it will take to fix them), that by simply adding code freezes to your roadmap you will create slower development and release cycles.
It’s worth pointing out that, on the one hand, when you’re in a code freeze, developers will continue to develop code but without integrating or testing it while they wait for the freeze to be over. This will result in a build-up of code leading to greater risks and instabilities which could significantly slow down the momentum of your CI/CD processes.
On the other hand, developers may want to get new code changes out before the code freeze period begins. This could lead to incomplete or poorly written code which may not undergo the usual thorough testing for the sake of saving time as they rush to get projects done before the code freeze. The end-result is lower-quality, less comprehensive software and applications.
Furthermore, code freezes may reduce your development team’s productivity. While Agile in general, and CI/CD specifically, keep your developers constantly working in an unbroken chain of productivity, code freezes force your developers to stop work at pre-defined intervals.
In other words, they could break your CI/CD pipeline.
By doing this, you will break your team’s rhythm and force them to try to work around your code freeze policies, instead of finding and maintaining whatever flow makes them most productive.
Making the Case for Code Freezes: A Losing Battle?
At this point, it’s looking pretty bleak for anyone who still wants to include code freezes in Agile methodology. There are some very compelling arguments and an overall solid case that, since the development of modern Agile methodology, code freezes have become:
- Obsolete and irrelevant
- Misaligned with modern development practices
- A barrier to rapid, high-quality releases
But while these arguments are compelling, and contain a lot of accurate information, they are not bulletproof. And there are fundamental flaws within each that need to be discussed before closing the book on code freezes as a useful element of Agile product management.
The Problem With Argument 1: Automated Testing Is Not Comprehensive
Automated QA and Agile development practices have increased the quality of code as it’s produced, that’s a fact. However, just because a piece of code has passed unit testing, that doesn’t mean it’s actually production-ready.
Even the most refined CI/CD approaches don’t always include critical steps—like regression testing—that ensure a piece of code is defect-free. When it comes down to it there are just some things you can’t test and resolve while a piece of code is in production.
If you choose to utilize code freezes, you aren’t going to give up the benefits of automated QA and Agile best practices.
You and your team will simply catch your code’s smaller, more trivial problems during production, clearing the decks to focus on catching larger, higher-impact issues during your freeze, such as the overall stability and reliability of your new software or feature.
The Problem With Argument 2: “Reduce”, Not “Eliminate”
While Agile is designed to reduce the time between development and release, there’s a big difference between trying to reduce this window, and trying to completely eliminate it. Doing so would be next-to-impossible, especially for larger projects.
The code freeze may be very short in CI/CD— or may only apply to a specific branch while development continues on other branches—but it still exists.
No matter how refined Agile became, there is almost always going to be a point in all development and release roadmaps where a new piece of software or feature will be evaluated in a fixed state before it goes out to real-world users.
The Problem With Argument 3: Rethinking Speed and Quality
If you utilize code freezes, you will add a new step to your development and release cycle and any time you add a new step to any process, you slow down that process and you create a new potential failure point. Code freezes are no exception.
But it’s important to take a step back, and to take a broader view of this slowdown and lost productivity.
If your feature has bugs, you will need to fix them, regardless of whether you caught those bugs during a code freeze, or whether they made themselves known after release. From a pure development perspective, the amount of time needed to fix them will be about the same in both scenarios.
But if you’re dealing with bugs in a live environment, you have a host of other issues you need to take the time to deal with, including:
- Deciding whether to roll back the buggy feature or leave it live.
- Taking your developers off their new projects, after they’ve begun work.
- Making it up to your real-world users who were impacted by the bugs.
- Answering to and managing your internal stakeholders who are not too happy about your problematic release.
The list goes on. There’s nothing more complicated, time-consuming, and destructive to productivity—for you and your team—than releasing a broken feature or product. Code freezes minimize the chances of this happening.
And as to the argument that code freezes lead to lower quality features and products because they reduce the amount of business requirements you can collect?
Your business requirements will always be little more than a “best guess” as to what your product or feature should function like. The most valuable requirements will always come from real-world users when deploying your product or feature in real-world scenarios.
How feature flags can replace code freezes
As we’ve already mentioned, a code freeze is done as a preventative measure against risky and/or faulty new code changes during sensitive periods.
However, a code freeze could actually increase risk. As developers continue to work on new changes that don’t get released during the freeze period, this means that the next release will have a pile up of commits making this release incredibly risky.
If any issues come up, it will be that much harder to pinpoint the source of the problem which means more time is wasted trying to locate and fix it.
This is where feature flags come in. Using feature flags means that developers no longer need to depend on code freezes during high traffic times to reduce the risk of code changes.
By decoupling deployment from release, feature flags allow developers to deploy a new feature or code change into production and toggle it off so it’s not visible to users and then gradually release it to specific user sets—for example, internally within your organization.
As a result, teams can continuously ship new code and work on new features with customers none the wiser as they will be hidden behind these flags and can be toggled on or off at any time. Teams can also turn off— or roll back— a buggy change at any time with a kill switch so users no longer have access to it while it’s being fixed.
In summary, feature flags give teams more control over the release process and help reduce the risk of deploying into production, especially during particularly sensitive, high traffic periods without negatively impacting the user experience.
Is it time to kill the code freeze?
Ultimately, code freezes still play an important role to avoid downtime or unexpected bugs during exceptionally busy times in the year.
Every e-commerce website is different so you will need to decide if a code freeze is the right choice for your website. If you do decide to implement a code freeze, draw up a carefully detailed plan in advance with your development team.
This will help you determine what codes need to be frozen, what needs to be optimized and what projects should be put on hold to avoid “sloppy” releases before going ahead with the freeze period.
There are cases where they play a less critical role. Very small projects may not need dedicated code freeze periods, for example.
New features that have relatively minor consequences might not be worth the freeze. The same is true for phased release plans when you just want to test new features with a warm audience who you have primed to expect a buggy, imperfect experience, in which case feature flags are an efficient way to progressively roll out these features.
It is worth taking the time—even a very short period of time—to make sure your new features are as perfect as you think they are before you put them in the hands of the people who matter most: your real-world users.
This is where feature flags become your greatest ally to allow you to provide an optimal customer experience without having to pause your deployments.
However, keep in mind that feature flags are a great asset that should be used year-round and not only during periods of high traffic to minimize risk and maximize quality.




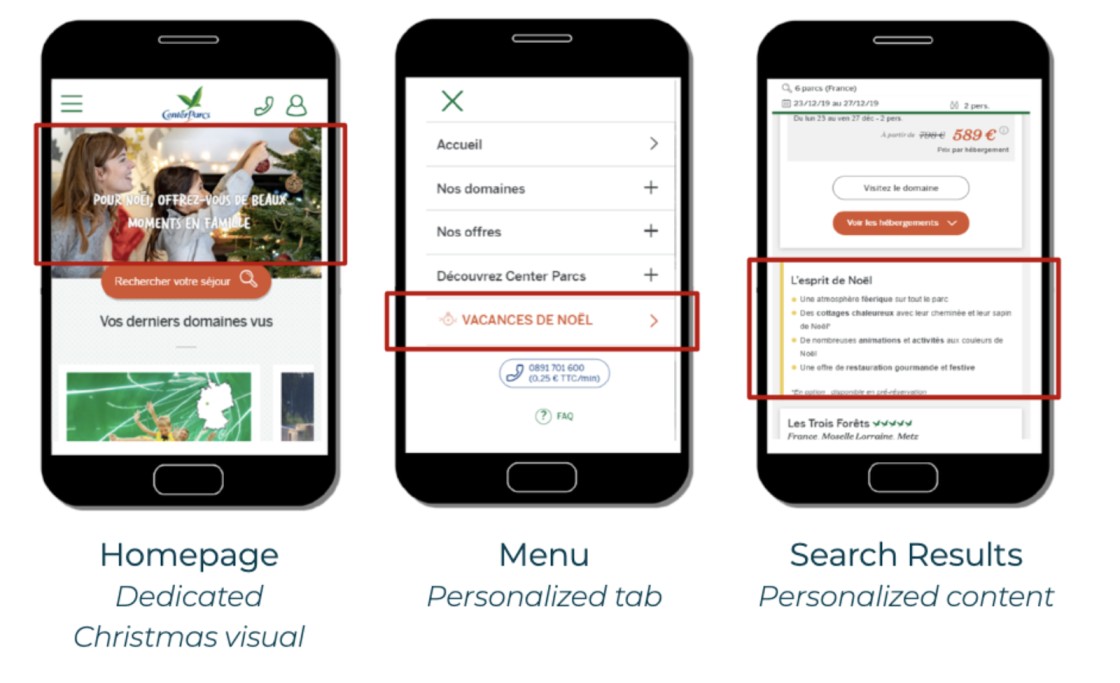


 FoodPanda knows that hunger cannot wait. In the image above you can see that they retarget with two magical words: “FREE+DELIVERY”
FoodPanda knows that hunger cannot wait. In the image above you can see that they retarget with two magical words: “FREE+DELIVERY”