You’ve all heard the saying before: You should never judge a book by its cover. Sounds ridiculous, right? Well, whether you like it or not, that’s exactly how people tend to determine an email’s worth by its subject line.
To give you some perspective, 35% of email recipients open emails based on subject lines alone according to HubSpot, and 21% of subscribers mark boring ones as spam, even if they know they aren’t.
In other words, customers are tough to impress.
If you really want to get noticed and prove you are deserving of their time and attention, supercharge your email subject lines with emotion. Because in the end, no matter how much we rationalize, our buying decisions spring from our emotions.
Read more: Creating Emotional Connections with Customers Using Data
Think of what a customer fears, dreams of, desires and wants in a product or solution. Use that as a premise of your subject lines to trigger an emotional response.
Some fashion and beauty brands have already been doing consistently well in this area. It’s time you learn the ropes from them.
Fair warning: It’s not a good idea to rely on emotions alone. The purpose of retail brands, like yours, is to sell. So hit a variety of customer touchpoints, including sending personalized emails, because they are 26% more likely to be opened than those without. Even better, they deliver 6X higher transaction rates.
Anyway, let’s dive in…
Email subject lines that induce FOMO
What does FOMO mean? Fear of missing out.
No one likes missing out on time-sensitive deals, including you. Just think of the last time you jumped on an offer because you didn’t want to regret losing out on a good bargain.
In another case, imagine a time when you felt some stress for not having bought something when there was still time, stock, and a good deal.
The same emotional reaction happens to your customers. Whether it’s creating a top-notch holiday campaign, announcing a limited time or a limited stock sale, pick the right set of words like ‘last chance, ‘don’t miss…’, to create urgency. Seeing such offers immediately activates this fear of missing out and drives them to act right away.
It’s exactly why this email from The North Face displays. The simple nudge is enough to get their recipient to grab this one– the last chance to save some money.

Examples of FOMO-provoking email subject lines:
Limited time offer:
- Alice & Olivia: LAST.DAY.DROP.EVERYTHING.
- Dropps: Get 15% off, but move quick.
- UNIQLO: TICK TOCK! Free shipping ends tonight
- Mango: LAST FEW HOURS to enjoy 30% off the entire collection!
Show it’s in demand:
- Nykaa: These will sell out in 3…2..⏳
- Sorel: These stunners are selling out fast
- Olay: Get it before it’s gone!?
- Marc Jacobs: New to sale and going fast
Imply negative outcomes:
- Nykaa: You snooze, you lose.
- Revolve: Say goodbye to 65% off ?
- UNIQLO: Get it before it’s gone
- Nike: Good stuff in your cart…checking out > missing out
More ideas:
- You’ve still got time
- Offer expires tonight
- The stock’s running out
- UH-oh. Your fav styles are (almost) gone
- ATTN: This pack will DEFINITELY sell out
- Saying goodbye is the toughest
- Our top 10 at 10% off for the next 24 hours
- LAST chance to save up to $55
- <New product> is selling like hot cakes
- You’ve ONE day left: FREE shipping +20% off
- Tonight only: Your wish list items on sale
- LIMITED-time offer on items on your wishlist
Email subject lines that drive curiosity
Can you guess what makes crime drama series binge-worthy? Why we click intriguing Upworthy and BuzzFeed posts? Or why we can’t stop reading novels? Blame our inherent need to close the loop between what we know and what we want to know. Otherwise known as – our curiosity!
This is also exactly why when people receive emails with partial information in the subject lines, they feel the urgent need to click ‘open.’
A perfect example is this email from Nykaa. This cliffhanger technique adds a touch of drama and mystery that is enough to tempt people to see what’s on the other side.

Examples of using curiosity in subject lines:
- Huckberry: “Want” — everyone
- Michael Kors: Give us an inch…
- J.Crew: The shorts circuit
- TwoThirds: Meet our unique pieces!
- Revolve Tomorrow’s outfit forecast
- Kate Spade: You’re getting sleepy…
- Steve Madden: TORNADO warning
- Anthropologie: Let us per-SUEDE you.
- Birchbox: We’ve got some ideas for you.
- Sephora: Because you need these.
- Estée Lauder Online: Why’s everyone obsessed with retinol?
- Jimmy Choo: Dreams are made up of these + complimentary global shipping
More ideas:
- Not even in your wildest dreams would…
- Got a sec? Open this email right away, or…
- FIRST time ever on sale
- New launches inside
- Is THIS what you’ve been waiting for?
- You DESERVE this
- Don’t buy from us…
- Before you regret not buying your favs
- Saying goodbye is the toughest
- Did we tell you that…
- This is personal…
How to personalize and test subject lines to maximize your open rate
By crafting a personalized email with your customer’s name or a point of interest in the subject line, you’re ensuring a connection with your customer.
According to Forbes, 72% of customers ONLY interact with personalized messaging.
Personalization is an important way to build trust with your customer and maintain your relationship with them before, during, and after their purchases. If you’re not using personalization in your email campaigns, you’re likely missing out on a huge opportunity.
Whether you’re looking to personalize your email content to capture customer attention or A/B test your subject lines to determine the best-performing phrase, choosing the right software will help you transform your ideas into reality.
AB Tasty is the complete experience optimization platform to help you create a richer digital experience for your customers — fast. From recommendations to smart search, this solution can help you achieve personalization with ease, experiment with a low-code implementation and revolutionize your brand and product experiences.
Email subject lines that spark happiness
Since you already occupy a sacred space in your customers’ inboxes, why not become a reason for their happiness?
A lot of things make people happy. So right from using humor, wordplay, solving people’s problems, appealing to their vanity, surprising them with freebies and special offers to reminding them there’s good in them. For example, if you can relate their shopping efforts to contributing to a social cause, that’s one idea of reminding them there’s good inside. There are plenty of ideas that you can use to really catch their eyes and make them feel unique.
This email from Fortress of Inca, for example, plays the vanity card. Honest confession: I was at the receiving end and I had to open the email because my fabulous choice in shoes was being appreciated!

Examples of subject lines focusing on happiness:
- Pura Vida: Save the Amazon Rainforest!
- Michael Kors: FOOD IS LOVE: Help Us Watch Hunger Stop
- Sephora: Your beauty issues solved
- Nicole Miller: Button me up, Button me down.
- Alice & Olivia: Hot date? We’ve got you.
- J.Crew: We don’t do this (MAJOR) sale too often…
- JustFab: Your FREE money is waiting. We put $30 in your account.
- Pura Vida: Happy birthday to us (gifts for you!)
- DSW: Find out how you can make a difference.
- Patagonia: School lunch made easy
- The North Face: 5 jackets that will have everyone saying…where’d you get them from!
More ideas:
- Our birthday treat = gifts for you!
- Giving > Getting
- It’s true…these will look dapper on you
- What to wear for the New Year’s bash
- Style secrets you can master in under 10 minutes
- Your winter break packing list is HERE!
- You’re one click away from shopping complete spring look
- Impressed by items in your card: Buy ‘em before they’re gone
- You earned what’s INSIDE this email
Email subject lines that create excitement
So far we’ve already established that humans are emotional creatures. Let’s now use excitement to get your sales meter ticking, because chances are that it results in impulse shopping.
Selling to customers is much easier when they’re excited and in touch with their emotions. In a state of excitement, your level of enthusiasm brings you to think and behave differently.
There are a number of ways to get the excitement level up. You can start by highlighting the exclusiveness of your offer, adding social proof (drop names and numbers), capitalizing action verbs to motivate action completion and even using emojis and exclamation marks.
In the email subject line below, team Pura Vida does two things — attract attention and excite the subscriber with the clever use of an emoji, the word ‘holy smokes,’ and a few ‘!

Examples of Building Excitement in Subject Lines:
- J.Crew: What Adam Scott thinks of our suits
- Anthropologie: Just for you: the inside scoop
- Pura Vida: Special offer (but only for our BFFs)
- Olay: Over 50 million sold ❤️
- Sorel: Meet our exclusive Frozen 2 boots✨
- DSW: Reviewers have spoken: “BEST BOOTIE EVER!”
- Steve Madden: Take our shoe stylists’ word for it
- Meundies: Well, this is exciting!
- Adidas: You’re in. Welcome to Adidas
- Revolve: This collab was made for you
- theBalm Cosmetics: Welcome to #THEBALMERS community!
- Victoria’s Secret: 60% off bras & apparels, in stores only! GO, GO, GO!
More ideas:
- Beyonce-approved autumn wear you can’t say no to
- Sweet launch discount (for members only!)
- Howdie! Your faves are back in stock
- Sshh…you’re the FIRST ONE to be seeing this
- It’s between you and us ONLY
- For your eyes only, because you wanted it
- Baby, it’s baccccck!
- It’s your birthday! Get 30% off, a FREE gift and free shipping.
Ready to Craft Email Subject Lines That Deliver?
Full disclaimer: It takes a lot of A/B testing and patience to come up with subject lines that stay within the 40-50 characters limit and stir the right emotions. Thankfully, now you’re aware of which emotions to go after and how to invoke emotional decision-making.
So it’s time to get to work! But before you go, and for maximum impact, keep these equally important things in mind:
- Match your brand personality with the tone of voice of your subject lines.
- Segment your audience to send targeted/personalized emails.
- A/B test your email send times.




 Once all these criteria have been met, a KPI can be properly designed and implemented with confidence. However, it will need monitoring and adjustment as time goes on once the KPI has been fully integrated.
Once all these criteria have been met, a KPI can be properly designed and implemented with confidence. However, it will need monitoring and adjustment as time goes on once the KPI has been fully integrated.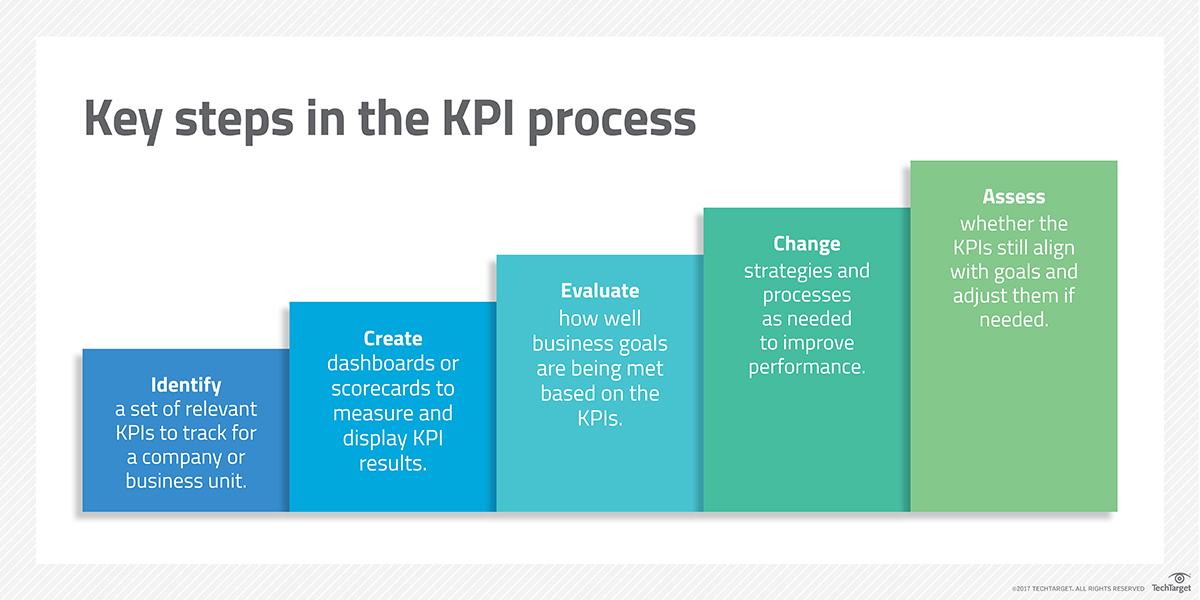



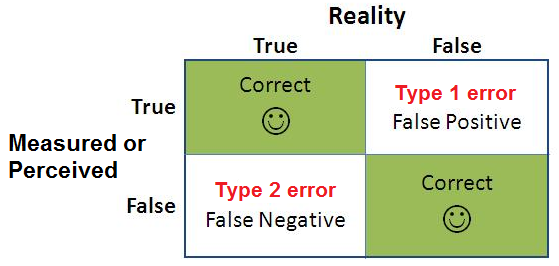
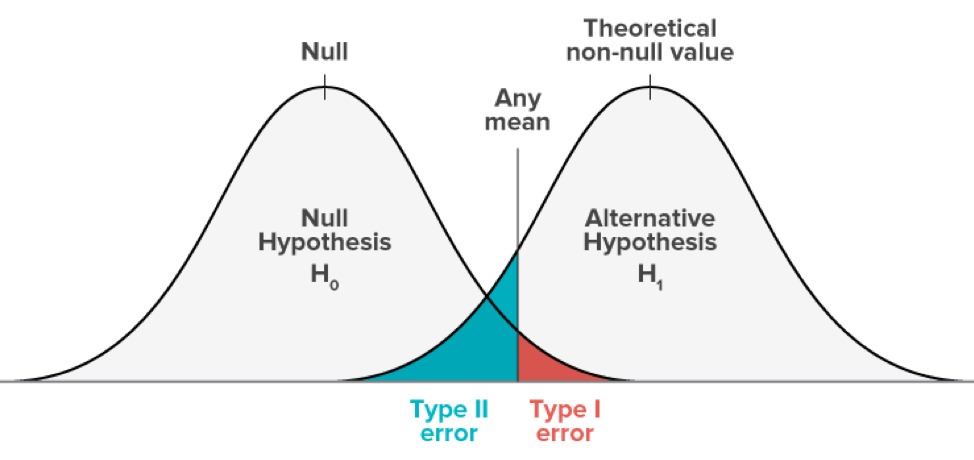
 You launch an A/B test to see if the variation (B) could outperform your control version (A).
You launch an A/B test to see if the variation (B) could outperform your control version (A).